🎨 Что важнее для ИИ-художника: понимать смысл или видеть детали?
📅 11 декабря 2025 года команда из Adobe, NYU и Австралийского национального университета опубликовала исследование, которое переворачивает представление о том, как учить ИИ рисовать картинки.
🤔 Неожиданное открытие
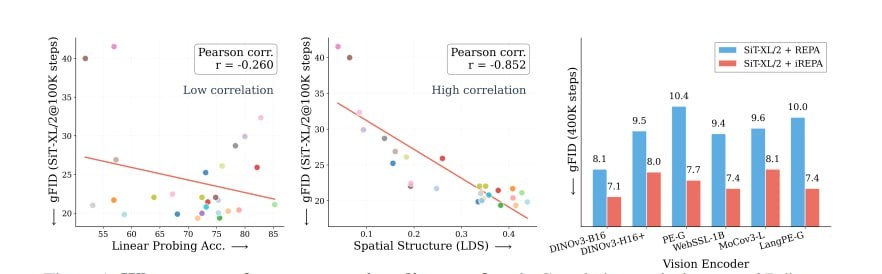
Казалось бы, логично: чем лучше ИИ понимает, что изображено на картинках (отличает кошку от собаки), тем лучше он их генерирует. Учёные проверили 27 разных vision-моделей и обнаружили обратное.
Модели с точностью распознавания ~53% рисовали лучше, чем монстры с 80%+ точностью. Как так?
Оказалось, для генерации важно не "что это", а как части картинки связаны между собой — текстура травы, тени от объектов, переходы цветов. Это называется "пространственная структура".
Пример: Модель может не знать, что на фото зонт, но отлично понимать, как свет падает на ткань и создаёт складки. И этого достаточно, чтобы нарисовать реалистичный зонт.
⚡️ Что сделали исследователи
Создали метрики, которые измеряют не "насколько умная модель", а "насколько хорошо она видит связи между деталями". Эти метрики показали корреляцию с качеством генерации выше 0.85, тогда как обычная точность распознавания — всего 0.26.
Затем улучшили стандартный метод обучения (REPA → iREPA): заменили сложный проектор на простую свёртку 3×3 и добавили нормализацию, которая усиливает передачу пространственной информации.
📊 Результат
iREPA ускоряет обучение и улучшает качество генерации для моделей любого размера. Причём эффект растёт с масштабом — чем больше модель, тем заметнее выигрыш.
💡 Что это значит на практике
Если вы работаете с AI-генерацией изображений, важнее выбрать модель, которая хорошо "чувствует" детали и их взаимосвязи, чем ту, что идеально классифицирует объекты.
Неожиданный вывод: Иногда "глупая" модель с хорошей пространственной структурой нарисует реалистичнее, чем "умная" с высокой точностью распознавания.
Исследование меняет подход к выбору базовых моделей для генерации: вместо погони за точностью на ImageNet стоит смотреть на то, насколько хорошо модель сохраняет локальные связи между частями изображения.
📄 Исследование: What matters for Representation Alignment: Global Information or Spatial Structure?
#AIWiz #ImageGeneration #ComputerVision