
OpenAI официально представила GPT-5.2 — новое поколение своих фронтир-моделей, которое компания позиционирует как серьёзный инструмент для сложной профессиональной работы. Речь идёт не просто об улучшенной версии предыдущей модели, а о заметном скачке в возможностях: от агентных пайплайнов до многочасовых задач с длинным контекстом и полноценной мультимодальностью. Давайте разберёмся, что именно изменилось и стоит ли эта новинка внимания разработчиков, аналитиков и всех, кто работает с AI ежедневно.
Кодинг: из помощника в полноценного коллегу
Одно из самых заметных улучшений GPT-5.2 касается программирования. На тесте SWE-Bench Pro, который считается одним из самых жёстких испытаний для AI в реальной разработке, GPT-5.2 Thinking решает 55.6% задач. Для сравнения, предыдущая версия GPT-5.1 справлялась с 50.8% кейсов. Казалось бы, разница небольшая, но на практике это означает заметно меньше ручной доработки патчей и более стабильную работу с крупными репозиториями.
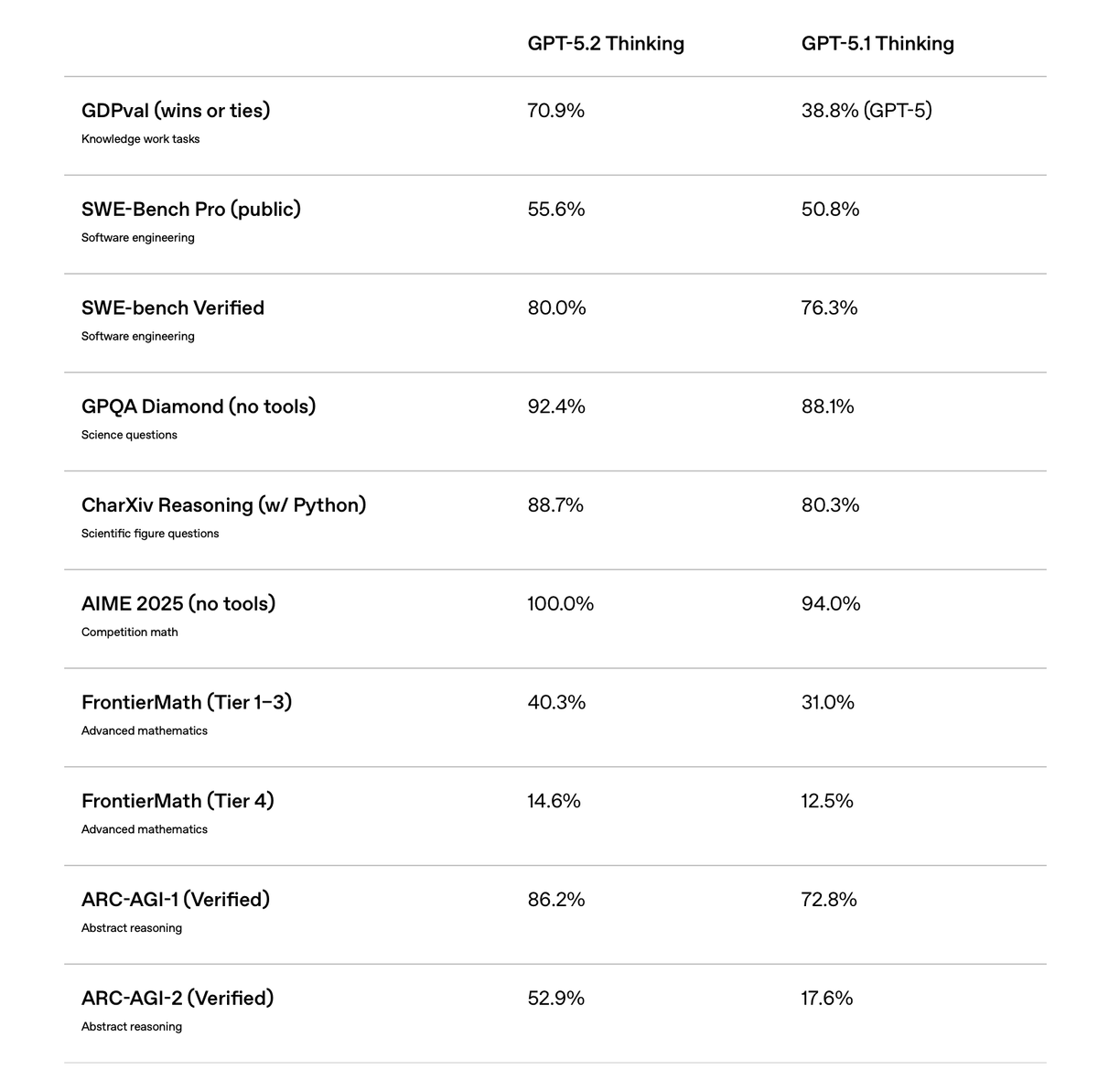
На упрощённой версии теста SWE-Bench Verified модель показывает ещё более впечатляющий результат — 80% решённых задач. Честно говоря, когда я впервые увидел эти цифры, подумал: «Ну наконец-то!» 😅 Потому что предыдущие версии часто генерировали код, который выглядел правильным, но требовал серьёзных доработок.
Фронтенд больше не слабое место
Ранние тестеры особенно отмечают улучшения в работе с фронтендом. GPT-5.2 способна генерировать сложные интерфейсы, работать с нетривиальными 3D-элементами и создавать UI одним большим промптом. По сути, это первая модель от OpenAI, которая выглядит как полноценный инструмент для full-stack разработки, а не просто продвинутый кодогенератор.
Для тех, кто занимается веб-разработкой, это означает возможность описать интерфейс словами и получить рабочий прототип за минуты. Конечно, финальная доводка всё равно потребуется, но объём ручной работы сокращается в разы. Представьте себе готовый лендинг через пару минут, который нужно лишь немного доделать (тут даже корзина работает). Дизайнеры с верстальщиками сейчас сильно напряглись 🙂
Длинный контекст: проблема решена
Работа с длинными контекстами всегда была ахиллесовой пятой больших языковых моделей. Теоретически они могли обрабатывать десятки или сотни тысяч токенов, но на практике качество ответов резко падало, если нужная информация находилась где-то в середине огромного текста. GPT-5.2 Thinking заметно лучше справляется с контекстами до 256 тысяч токенов.
На тесте MRCRv2 модель показывает почти идеальное извлечение нужной информации, даже если она «утоплена» в сотнях тысяч токенов. Что это означает на практике?
- Можно загружать целые договоры и получать точные ответы на вопросы по конкретным пунктам
- Работа с многофайловыми проектами становится удобнее — модель не теряет контекст при анализе большой кодовой базы
- Длинные отчёты, исследования и переписки обрабатываются без потери смысла
- Ответы остаются консистентными на протяжении всего диалога
Compact-режим для агентных сценариев
Отдельно стоит упомянуть новый compact-режим, который позволяет GPT-5.2 «думать» даже за пределами контекстного окна. Это особенно важно для долгих агентных сценариев, когда AI-агент выполняет цепочку действий на протяжении нескольких часов. Теперь модель может сжимать предыдущие шаги, сохраняя при этом важную информацию.
Помню, как раньше приходилось вручную делить большие задачи на части, чтобы модель не «забывала» начальные инструкции. Теперь это в прошлом 😉
Tool-calling: агенты наконец стали предсказуемыми
Одна из самых больных тем в разработке AI-агентов — это надёжность использования инструментов. Модель может отлично рассуждать, но при вызове внешних функций часто допускает ошибки: неправильные параметры, пропущенные шаги, логические сбои. GPT-5.2 делает серьёзный шаг вперёд в этом направлении.
На тесте Tau2-bench Telecom модель достигает 98.7% успешного использования инструментов. Причём даже в быстром режиме с отключенными рассуждениями (reasoning.effort='none') точность заметно выросла по сравнению с предыдущими версиями.
От роя агентов к одному мега-агенту
Несколько компаний, тестировавших GPT-5.2, сообщили, что смогли заменить набор из десятка мелких специализированных агентов одним универсальным агентом с 20+ инструментами. Это упрощает архитектуру, снижает накладные расходы и делает систему более предсказуемой.
Представьте себе: раньше для обработки входящих заявок нужно было три агента — один читает письмо, второй классифицирует, третий формирует ответ. Теперь один агент на GPT-5.2 справляется со всей цепочкой, причём с меньшим количеством ошибок.
Другие важные улучшения
Работа с изображениями стала точнее
GPT-5.2 заметно лучше понимает визуальный контент: графики, дашборды, интерфейсы, технические схемы. Количество ошибок при интерпретации GUI уменьшилось почти вдвое. На задачах типа «прочитай диаграмму и объясни, что происходит» модель работает аккуратнее и даёт более детальные описания.
Это особенно полезно для аналитиков данных, которые работают с визуализациями, и для тех, кто проектирует интерфейсы. Теперь можно загрузить скриншот дашборда и попросить модель объяснить логику или предложить улучшения.
Меньше галлюцинаций
Фактических ошибок стало меньше примерно на треть. OpenAI не раскрывает точную методологию подсчёта, но тестеры подтверждают: модель реже выдумывает несуществующие факты, библиотеки или API. Это критично для аналитики, резюмирования документов и деловой переписки, где точность информации на первом месте.
Лично меня раньше всегда напрягало, когда модель с уверенным видом рассказывала про несуществующую функцию в React 😅 Приятно, что эта проблема становится менее острой.
Цены и доступность GPT-5.2
Новая модель уже доступна для пользователей ChatGPT с подписками Plus, Pro, Business и Enterprise. В API она представлена под именами gpt-5.2 и gpt-5.2-chat-latest, а самая мощная версия называется gpt-5.2-pro.
Цены в API выросли относительно GPT-5.1:
- Input: 1.75 доллара за миллион токенов
- Output: 14 долларов за миллион токенов
- Cached input: скидка 90%
На первый взгляд кажется, что модель подорожала, но OpenAI подчёркивает важный момент: GPT-5.2 делает ту же работу короче и быстрее. Меньше «лишних» токенов в ответах, точнее формулировки, быстрее достижение результата. По факту итоговые расходы для многих сценариев могут оказаться ниже или сопоставимыми.
Кэшированные запросы со скидкой 90% особенно выгодны для приложений, которые многократно обращаются к одним и тем же данным — например, для ботов поддержки, работающих с базой знаний компании.
Кому стоит переходить на GPT-5.2
Разработчики
Если вы пишете код с помощью AI, GPT-5.2 станет заметным апгрейдом. Улучшения в SWE-Bench показывают, что модель лучше справляется с реальными задачами, а не просто с учебными примерами. Работа с крупными кодовыми базами стала удобнее благодаря длинному контексту.
Прорыв в генерации фронтенда означает, что теперь можно доверить модели создание сложных интерфейсов. Это экономит часы рутинной работы и позволяет сосредоточиться на бизнес-логике.
AI-агенты и автоматизация
Если вы строите агентные системы, повышение точности tool-calling до 98.7% — это серьёзная причина для обновления. Меньше ошибок означает меньше костылей и обработчиков исключений в вашем коде.
Аналитики и работа с документами
Улучшенная работа с длинными контекстами и визуальным контентом делает GPT-5.2 отличным инструментом для анализа отчётов, договоров, финансовых документов. Снижение количества галлюцинаций повышает доверие к выводам модели.
Что осталось за кадром
При всех улучшениях стоит помнить о нескольких моментах. Во-первых, модель всё ещё не идеальна — 55.6% на SWE-Bench Pro означает, что почти половину задач она решает с ошибками или не решает вообще. Во-вторых, работа с очень специфическими доменами (медицина, право, наука) требует дополнительной проверки и экспертизы.
Кроме того, OpenAI не раскрывает деталей обучения модели, что вызывает вопросы у части сообщества. На каких данных обучалась GPT-5.2? Какие методы использовались для снижения галлюцинаций? Ответов на эти вопросы пока нет.
Выводы
GPT-5.2 — это не просто инкрементальное обновление. Это попытка OpenAI сделать AI-модели действительно полезными для профессиональной работы, а не только для экспериментов и прототипов. Улучшения в кодинге, работе с длинным контекстом, tool-calling и визуальном понимании делают модель универсальным инструментом для широкого круга задач.
Да, она подорожала. Да, она всё ещё не совершенна. Но если вы каждый день работаете с AI — пишете код, строите агенты, анализируете документы — GPT-5.2 заслуживает внимания. Это шаг к тому моменту, когда AI-ассистент перестанет быть просто помощником и станет полноценным коллегой.
А вы уже попробовали GPT-5.2? Заметили ли разницу по сравнению с предыдущими версиями в своих задачах?
Каждый день я публикую свежие материалы, разборы и новости в Telegram. Если не хотите пропускать интересное — подписывайтесь и читайте в удобное время!