Владельцам программатора UFPI мои самодельные утилиты бесполезны чуть менее чем полностью. Для остальных - примеры их использования будут в третьей части. А здесь я напишу немного теории и в конце оставлю короткое описание параметров и ссылки на исходные тексты утилит.
Напомню несколько отличий NAND памяти от привычных нам блочных устройств:
1. Запись в NAND производится путем сброса значения битов из единичного значения в нулевое. Например, если ячейка памяти содержала двоичное значение 11111111b, в нее записали 01011010b, то в памяти останется значение 01011010b. А если затем туда же попробовать записать 10101010b, то в памяти мы получим 00001010b (побитовое И между 01011010b и 10101010b = 00001010b).
2. Сброс ячеек NAND в единичные значения производится операцией стирания. Операция делается поблочно (erase block). Обычно размер блока большой - десятки/сотни килобайт и это дорогостоящая операция в плане времени и потребляемой энергии. Поэтому используются специальные способы хранения, чтобы минимизировать количество этих операций. Это либо файловые системы, оптимизированные для NAND (например, UBIFS), либо запись ведется в свободные (стёртые заранее) блоки. Как следствие, на устройстве можно найти несколько копий, например, u-boot environment и необходимо искать, какая из них является актуальной.
3. Также NAND вещь весьма ненадежная. Может содержать бэд блоки и подвержена bit flip. Бэд блоки помечаются специальным образом либо в разделе BBT (bad block table - наш вариант), либо в OOB (out of band) области данных. Я ранее уже приводил картинку:
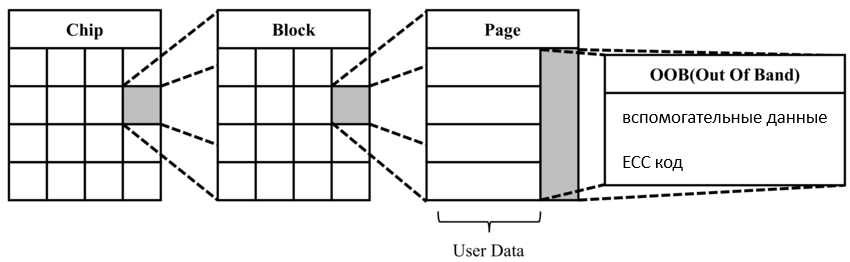
В моей Мини 3 про используется микросхема ESMT F59L4G81CA (аналог TOSHIBA TC58NVG2S0HTA00). В ней размер erase блока 272 Кб или 64 страницы по 4352 байта.
Ниже я буду использовать термин "сырой" дамп NAND - это дамп всех данных, включая OOB. "Очищенный" дамп NAND - дамп только полезных данных, без OOB. Очищенный дамп пригоден для анализа утилитами binwalk, монтирования nandsim и редактирования. Мои утилиты позволяют конвертировать сырой дамп в очищенный и наоборот.
Отступление про кодирование блоков в NAND
Формат хранения данных внутри страницы зависит от топологии микросхемы, производителя устройства и операционной системы. В нашем случае формат такой:

Каждая страница NAND содержит по 8 штук 528-байтных секторов и 128 байт spare пространства. Первые 512 байт каждого сектора содержат пользовательские данные. Далее идут 2 служебных байта ("специальная метка" в таблице выше) - они используются для идентификации адресов начала специальных ("rsv" в терминологии Amlogic u-boot) данных:
nbbt - bad block table
nenv - u-boot environment
nkey - ключи unifykey
nsec - никогда не встречал
ndtb - отсюда идет чтение device tree командой "imgread dtb _aml_dtb адрес"
nddr - возможно, данные для инициализации DDR
Как видно, каждая сигнатура имеет ровно 4 байта. Первые два символа сигнатуры записаны в двух служебных байтах первого сектора, вторые два - в служебных байтах второго сектора соответствующего блока. Например, nbbt:
В последующих секторах в двух служебных байтах идут данные о версии - тем самым устройство находит последнюю версию данного блока. Я в логику версионности не вникал - желающие могут поизучать функцию meson_rsv_scan в файле drivers\mtd\aml_rsv.c в исходниках Khadas.
Nednik в своей статье тоже не заморачивается с определением последней версии данных, а просто правит все копии nenv.
Обычно первый используемый u-boot блок (bad block table) находится в 20-ом erase блоке NAND, так что его смещение от начала сырого дампа NAND будет:
nbbt == 20 block = (4352*64)*20 = 550000h
Остальные блоки можно искать прибавляя соответствующее количество erase блоков NAND_xxx_BLOCK_NUM со скриншота выше. Блоки идут в том порядке как на скриншоте.
Если на вычисленный адрес выпадет сбойный блок NAND, то сигнатура не сойдется с xxx_NAND_MAGIC и устройство продолжит поиск в следующем. Сбойные блоки, помеченные в таблице NBBT не учитываются и все последующие блоки сдвигаются (возможно, за исключением блоков UBIFS - так как в ней поддержка bad блоков реализована нативно). Формат таблицы NBBT простой - блоки кодируются значениями 00 == нормальный, не-00 == bad block (02 - bad block с завода).
Актуальные адреса некоторых блоков RSV можно увидеть в логе загрузки:
Следует иметь в виду, что в логе адреса указаны без учета OOB - то есть в блоках "полезных данных" по 4096 байт, а не в "сырых" по 4352 байта. Так что для "сырого" дампа NAND адреса требуется пересчитать. Например, из строки "meson_rsv_write 269 write nenv to 0x600000" адрес u-boot environment в сыром дампе станет:
0x600000/4096*4352=0x660000
Отступление про ECC кодирование
Как я писал выше, NAND память подвержена bit flip, то есть самопроизвольным переводом отдельных битов из одного состояния в другое. Для сохранения целостности данных используются коды коррекции ошибок. Amlogic любит код BCH. Какой именно код используется в устройстве и сколько ошибок на страницу допустимо, можно посмотреть в исходниках u-boot в файле drivers\mtd\nand\raw\aml_nand\nand_flash.c в структуре aml_nand_flash_ids:
У нас используется режим BCH8: 14-байтовый BCH код с полиномом 0x402b, исправляющий 8 битов ошибок на один 514-байтовый блок. Обратите внимание, что блок не 512, а 514 байт, так как захватывает дополнительно два служебных байта.
Данные перед расчетом ECC инвертируются, после чего рассчитанный ECC тоже инвертируется. Тем самым страница из всех 0xFF (то есть страница после форматирования) получит ECC код также из всех 0xFF (если кто не знает - BCH код для всех нулей == все нули).
Первый блок NAND
Формат самого первого блока NAND отличается от остальных. В нем в слегка зашифрованном виде (XOR с фиксированным набором данных) содержится малополезная информация, описывающая NAND. ECC в нем рассчитывается по особому (блоки по 370 байт, а не по 514), править в нём особо нечего - так что стоит его оставлять как есть.
Утилита по работе с ECC
Ранее Nednik делал телеграм-бот для пересчета ECC отдельных секторов (боту предоставляешь 514 байт данных и он возвращает 14 байт ECC). Я по его подсказке написал утилиту по проверке и восстановлению данных в сыром дампе NAND на основании ECC, и по пересчету ECC на основании модифицированного файла.
Использование утилиты:
./ecc_fix [-v] [-2 или -4] [-skip N] <command> <input_file> [output_file]
Команды:
check - проверить данные в файле по их ECC
fixdata - исправить ошибки в файле на основании имеющихся в нем ECC
fixecc - пересчитать ECC на основании данных файла
Ключи:
-v - verbose режим, выдает на экран адреса блоков с ошибками.
-2 - поддержка NAND с размером страницы 2176 байт
-4 - поддержка NAND с размером страницы 4352 байт
-skip N - пропустить первые N блоков (блок==4352 байта) от начала файла (в выходной файл они будут записаны без изменений). Полезно если правите только в конце дампа и боитесь что утилита что-то поломает в стартовых секторах.
После снятия дампа программатором, следует обязательно восстановить его данные ключом fixdata. Если этого не сделать - в дампе останутся ошибки в отдельных битах (на весь дамп их будет несколько тысяч), что помешает провести его анализ. Утилита не трогает сектора, в которых ECC не позволяет восстановить данные - это, например, первый блок NAND, а так же отформатированные блоки UBIFS.
Утилита разработана только под NAND память с секторами по 4352 байта и с erase block размером в 8 секторов. В ней захардкожен алгоритм BCH, позволяющий восстановить 8 битов ошибок, используя 14 байт ECC кода и полином 0x402b:
bch_init(14, 8, 0x402b, false);
Для поддержки других типов NAND требуется исправить константы в начале main.c и перекомпилировать утилиту. Полиномы для другого количества бит, например, для BCH16, можно подсмотреть в файле lib\bch.c, в таблице prim_poly_tab.
Команда fixecc работает только совместно с утилитой file_combine, описанной ниже.
Утилита по конвертации сырого дампа в очищенный и назад
Для редактирования предварительно восстановленного по "ecc_fix fixdata" дампа, следует очистить его от OOB данных. Для этого я написал специальные утилиты:
./file_skip [-2 или -4] <original_input_file> <output_file>
./file_combine [-2 или -4] <original_input_file> <edited_output_file> <final_file>
Утилита file_skip удаляет OOB данные из файла original_input_file, производя на выходе файл output_file, готовый для редактирования.
Утилита file_combine на основе первоначального файла original_input_file обрабатывает отредактированный файл edited_output_file и записывает результат в final_file.
Утилита file_combine делает "магию", которую понимает утилита ecc_fix - ищет только те сектора, которые были изменены в отредактированном файле и помечает их специальным образом. При этом сохраняется значения двух служебных байт, что позволяет вносить изменения в RSV разделы, в частности u-boot environment и DTB. Сектора, в которых не было изменений сохраняют старые OOB, в том числе и с неправильным ECC - тем самым сохраняются нестандартный первый сектор, специальные сектора UBIFS и любые другие, формат OOB данных которых я не знаю.
Для тех кто посмотрел исходники:
static const uint8_t modify_marker[14] = {
0xD8, 0x26, 0x44, 0x65, 0x7F, 0x2F, 0x2B, 0x97, 0x1B, 0x6C, 0x53, 0x3A, 0x99, 0x9E
};
это значение ECC для страницы из всех нулей. Значение выбрано специально, так как страница из всех нулей не может быть изменена записью в нее каких-либо данных (только форматированием).
Файл final_file следует обработать утилитой ecc_fix с командой fixdata:
./ecc_fix [-2 или -4] <final_file> <write_this_file_to_nand>
Пока на этом всё. Примеры того, как правильно отредактировать дамп NAND и пересчитать в нем ECC я напишу в следующей статье.