GLM-4.6V
Команда Z.ai представила новую серию открытых мультимодальных lm
🔘GLM-4.6V (106B) - для облачных и высокопроизводительных сценариев
🔘GLM-4.6V-Flash (9B) - компактная версия для локального развертывания
Впервые в мультимодальной модели интегрированы встроенные возможности Function Calling. Теперь:
- Изображения, скриншоты и документы передаются напрямую как параметры инструментов без преобразования в текст
- Модель визуально понимает результаты работы инструментов и использует их в дальнейших рассуждениях
- Без потери информации при конвертации
Создание rich-контента
GLM-4.6V автоматически генерирует качественный структурированный контент с изображениями:
- Понимает сложные документы с графиками, таблицами, формулами
- Самостоятельно вызывает инструменты для обрезки ключевых визуалов
- Проводит визуальный ауди" изображений на релевантность
Визуальный веб-поиск
End-to-end мультимодальный поиск:
- Распознает намерения пользователя и автономно запускает нужные инструменты поиска
- Анализирует смешанную визуально-текстовую информацию
- Выдает структурированный визуально-богатый ответ
Репликация интерфейсов
- Пиксельная точность: загружаешь скриншот - получаешь готовый HTML/CSS/JS код
- Интерактивное редактирование
Контекст 128K токенов
Зза один проход ~150 страниц сложных документов / 200 слайдов презентации / Часовое видео
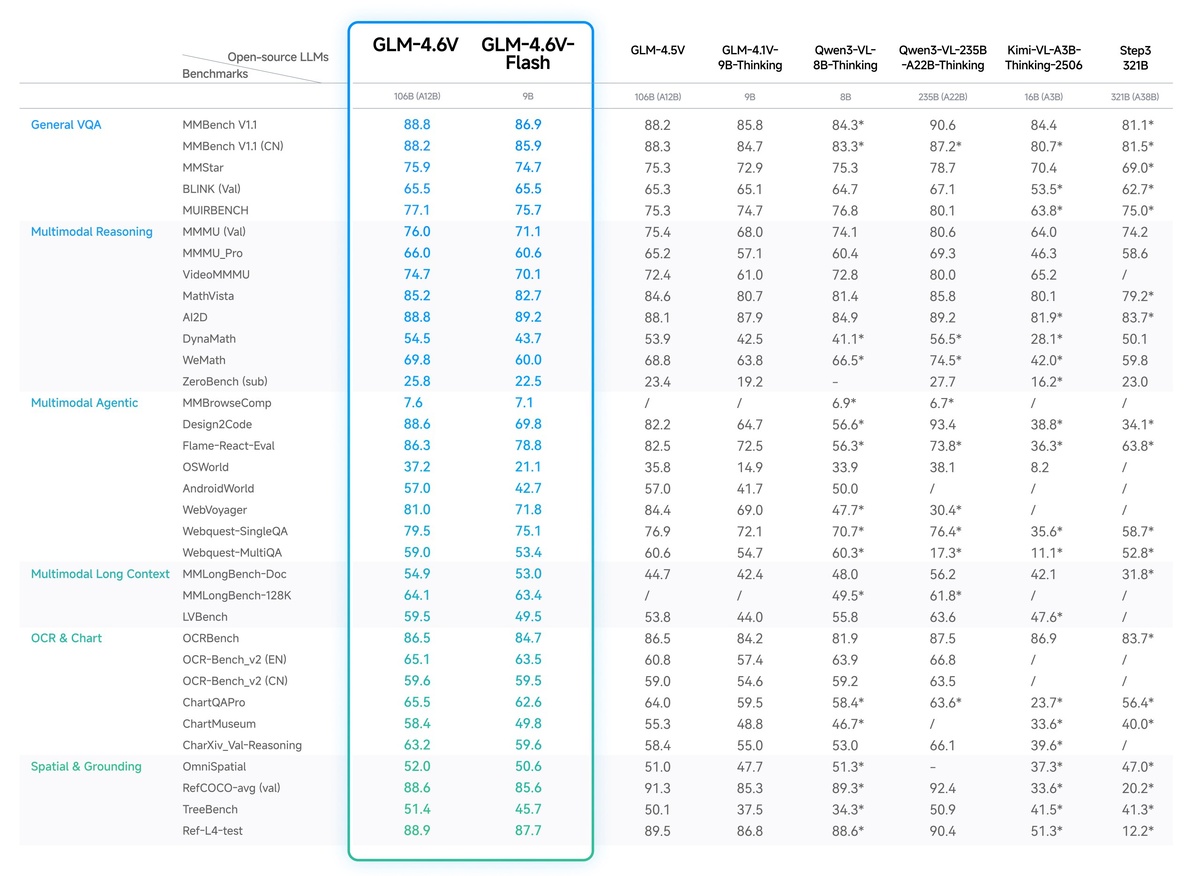
GLM-4.6V показала SOTA-результаты среди открытых моделей сопоставимого масштаба на 20+ бенчмарках, включая MMBench, MathVista и OCRBench
Под капотом
- Расширенное окно контекста до 128K токенов
- Миллиардные датасеты мультимодального восприятия
- Синтетические данные для агентного обучения
- Reinforcement Learning для мультимодальных агентов
Поддерживает vLLM и SGLang