
Вы когда-нибудь вводили в поиске «лазерная эпелляция» вместо «лазерная эпиляция»?
Или писали «книжный магозин» в форме обратной связи?
А теперь представьте: ваш сайт ничего не находит, потому что сравнивает строки жёстко, по принципу «точно или ничего».
Результат?
Потерянный клиент. Пустая корзина. Разочарованный пользователь.
Но есть способ сделать систему человечнее — с помощью алгоритма, который уже 60 лет служит мостом между машинной точностью и человеческой небрежностью.
Это — расстояние Левенштейна 🌟
📜 История в двух строках
Алгоритм назван в честь Владимира Иосифовича Левенштейна, советского математика, который впервые описал его в 1965 году.
Задача была простой: насколько две строки отличаются друг от друга?
Ответ — не «да/нет», а число: сколько операций нужно, чтобы превратить одну строку в другую.
Разрешённые операции:
- ✏️ Замена символа (k → c)
- ➕ Вставка символа (cat → coat)
- ➖ Удаление символа (book → boo)
🔢 Как это работает? Пошаговый пример
Допустим, нужно сравнить:
- s1 = "kitten"
- s2 = "sitting"
Сколько шагов, чтобы превратить kitten в sitting?
- k → s (замена) → sitten
- e → i (замена) → sittin
- Добавить g в конец (вставка) → sitting
→ Всего 3 операции. Расстояние Левенштейна = 3.
Кажется, просто? Но под капотом — динамическое программирование, и вот как это выглядит в коде.
💻 Реализация на PHP: не просто levenshtein(), а понимание
Да, в PHP есть встроенная функция levenshtein(). Но чтобы реально понять, как это работает — напишем свою реализацию.
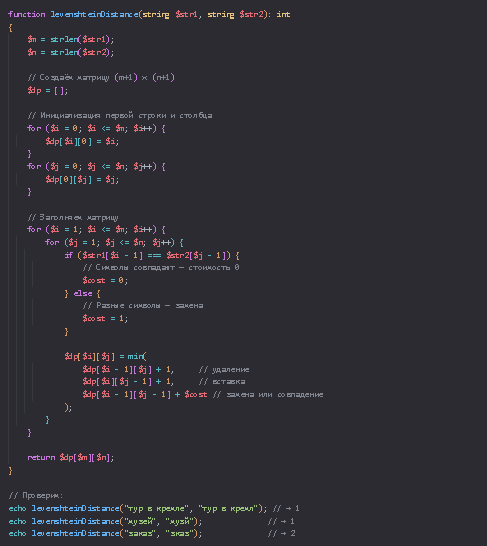
👉 Эта функция не использует встроенную библиотеку — вы видите, как строится матрица, как выбирается минимальный путь. Это даёт гибкость: например, можно ввести разный вес для замены и вставки (а в некоторых языках — учитывать раскладку клавиатуры: ф рядом с а, значит, опечатка «фмзыей» → «музей» менее критична).
🛠 Где это реально выручает? 4 живых кейса
1. Умный поиск по каталогу туров
Пользователь ищет:
«Ночной круз по Неве»
(Опечатки: «круз» → «круиз», пропущена буква)
Ваш код:
2. Очистка имён при импорте данных
Вы получаете CSV с клиентами:
- «Анна Петрова»
- «Аня Петрова»
- «Анна Петроваа»
Расстояние между «Анна Петрова» и «Анна Петроваа» = 1 → система предлагает:
«Объединить эти записи?»
Это автоматическая дедупликация, спасающая часы ручной работы.
3. Проверка уникальности отзывов
Спамеры пишут:
- «Отличный тур! Рекомендую!»
- «Отличный тур! Рекомендую!!!»
- «Отличныйй тур! Рекомендую!»
Если расстояние между новым отзывом и уже существующим < 5 — отклонить как дубликат.
4. Интеграция между системами: CRM ↔ Сайт
Представьте:
- На сайте создана заявка: «Экскурсия в Павловск»
- В CRM есть продукт: «Павловск (автобусный тур)»
Жёсткое сравнение — не найдёт связь.
Но если посчитать расстояние между названиями — оно мало → система автоматически привязывает сделку к правильному продукту.
⚠️ Когда НЕ стоит использовать Левенштейна?
- Синонимы: «автобус» и «машина» — разные слова, но по смыслу близки → нужен NLP.
- Длинные тексты: для абзацев лучше использовать косинусное сходство или TF-IDF.
- Языковые особенности: например, «ё» и «е» — в русском часто взаимозаменяемы, но алгоритм считает это разными символами.
→ Решение: нормализовать строки перед сравнением:
💡 Профессиональный совет: комбинируйте!
Самый мощный подход — каскад:
- Точное совпадение (==) → сразу даёт результат.
- Расстояние Левенштейна ≤ 2 → предлагает исправление.
- Поиск по ключевым словам → если не помогло — ищет по тегам.
- ИИ-модель (если бюджет позволяет) → понимает смысл.
🏁 Заключение: будьте дружелюбнее к ошибкам
Люди опечатываются. Это нормально.
А вот системы, которые карают за это, — теряют доверие.
Расстояние Левенштейна — это не «математическая забава». Это практический инструмент эмпатии, встроенный в код.
Он превращает «ошибку» в «почти попал» — и даёт пользователю второй шанс.
✨ Хороший продукт работает правильно.
Великий продукт работает даже тогда, когда пользователь ошибся.