Deep Research — это новый класс систем, в которых большие языковые модели не просто генерируют текст «по запросу», а проходят полный цикл исследования: ставят задачу, ищут и отбирают источники, ведут память, синтезируют выводы и оформляют их в проверяемый отчёт. Цель — превратить LLM из чат‑ботов в полуавтономных исследователей.
Авторы крупного обзора (Шаньдунский университет, РУДН, Тsinghua и др.) предлагают первую целостную «дорожную карту» Deep Research: стадии развития, архитектуру, техники и ключевые проблемы.
Три этапа эволюции: от поиска к «ИИ‑учёному»
Исследователи выделяют три уровня зрелости Deep Research:
- Agentic Search — автономный поиск
Система:
- сама формулирует поисковые запросы;
- бегло просматривает результаты (веб, базы, документы);
- выдаёт краткий ответ с ссылками на источники.
Главный фокус — точность и эффективность поиска, а не глубина анализа.
- Integrated Research — интегративное исследование
LLM научается:
- совмещать разнородные источники;
- учитывать противоречия и неопределённость;
- строить связные, структурированные обзоры (обзоры литературы, аналитические отчёты).
Это уже инструмент для длинных задач и решений «на уровне отчёта», а не одного ответа в пару абзацев.
- Full‑stack AI Scientist — «полный AI‑учёный»
Целевая стадия, где агент способен:
- выдвигать гипотезы,
- проектировать и запускать эксперименты (симуляции, вычисления, скрипты),
- критиковать существующие работы,
- предлагать новые теории, проверяемые и воспроизводимые.
Здесь ИИ переходит от «повторения и компоновки известного» к созданию нового знания.
Четыре опоры Deep Research: как устроен «исследовательский цикл» ИИ
Типичный Deep Research‑агент работает в виде замкнутого цикла:
- Query Planning — планирование запроса
Сложный вопрос разбивается на цепочку подзадач. Есть три основных стратегии:
- параллельная: независимые подпункты решаются одновременно;
- последовательная: каждый шаг опирается на результат предыдущего;
- древовидная: модель исследует ветви возможных ходов, отбрасывая неудачные.
Это делает рассуждение пошаговым и контролируемым, а не разовой «выдачей ответа из головы».
- Knowledge Acquisition — добыча знаний
В отличие от старого подхода с одним поисковым запросом, Deep Research:
- многократно обращается к веб‑поиску и специализированным базам;
- использует мультимодальный поиск (текст + изображения, таблицы, карты, спутниковые снимки);
- динамически варьирует глубину и ширину поиска.
Цена — рост вычислений и риски несогласованности между модальностями, но взамен появляется живой, актуальный контекст, а не только «знания до даты обучения».
- Memory Management — управление памятью
Ключевое отличие от обычных LLM. Память отвечает за то, чтобы:
- консолидировать (переводить краткосрочные результаты в долгосрочное представление — векторные записи, заметки);
- индексировать (строить структуры для быстрого поиска по накопленным знаниям);
- обновлять (переписывать устаревшую или уточнённую информацию);
- забывать (осознанно удалять шум и неактуальное, чтобы не захламлять контекст).
Без такой динамической памяти длинные исследования разваливаются на несвязанные эпизоды.
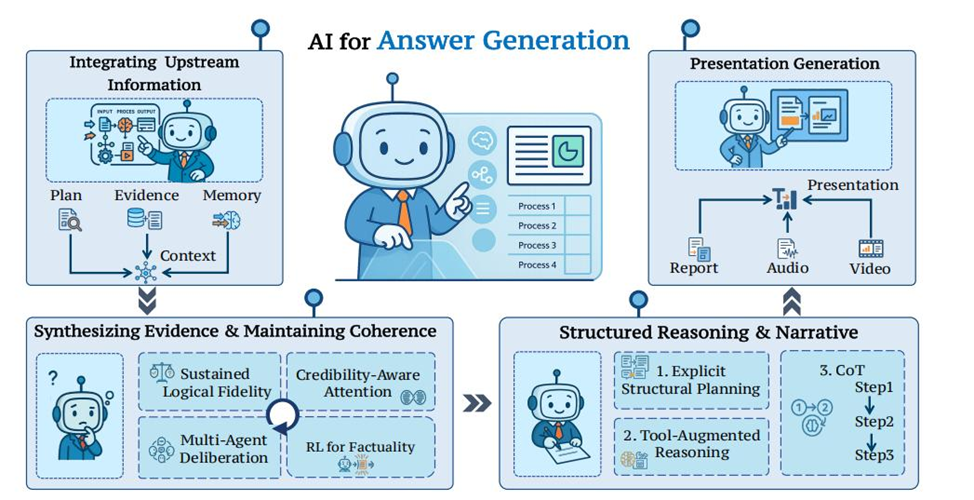
- Answer Generation — порождение ответа
Здесь задача не «написать красивый текст», а:
- примирить противоречивые источники;
- сохранить логическую целостность на протяжении десятков страниц;
- явно показать цепочку рассуждения и привести точные ссылки;
- при необходимости комбинировать текст, схемы, таблицы, графики.
Эволюция идёт от простого слияния выдержек к полноценному научному нарративу с аргументацией и структурой.
Главные вызовы Deep Research
Авторы обзора выделяют несколько фундаментальных проблем:
- Когда именно искать?
Сейчас многие агенты работают по грубой схеме: «если не уверен — ищи ещё». Это ведёт к:
- чрезмерным затратам (over‑retrieval),
- или, наоборот, преждевременным ответам без достаточной базы.
Нужна тонкая «политика поиска»: модель должна решать не только что сказать, но и когда стоит поискать ещё.
- Плоская память
Популярные векторные хранилища (embeddings по кускам текста) слабо отражают:
- причинно‑следственные связи,
- иерархии теорий,
- структуру аргументации.
Без более богатых, структурных форм памяти (графы знаний, абстрактные онтологии) глубинное рассуждение остаётся ограниченным.
- Нестабильное обучение агентов
RL‑алгоритмы вроде PPO/GRPO ведут себя терпимо в одношаговых задачах, но в многошаговых агентных сценариях:
- награда может внезапно деградировать,
- появляются «пустые» или шаблонные ответы,
- возникают технические проблемы — коллапс энтропии, взрыв градиентов.
То есть пока нет надёжного, промышленного стандарта обучения реально долгоживущих исследовательских агентов.
- Сложность и предвзятость оценки
Формат «LLM‑as‑Judge» (модель оценивает текст другой модели) стал де‑факто стандартом, но:
- судья может любить «слишком длинные» или похожие на себя ответы;
- массовые попарные сравнения стоят дорого и по деньгам, и по времени;
- устойчивые, честные метрики для длинных выводов пока только формируются.
Куда всё это идёт
Авторы обзора видят несколько необходимых векторов развития:
- Модельная агностичность: Deep Research должен уметь работать поверх разных LLM и подстраиваться под их стиль и сильные/слабые стороны.
- Стандартизированная память: более общие, модульные «слои памяти», поддерживающие отслеживание, обновление и корректные ссылки на найденные факты.
- Модульные фреймворки: легко расширяемые пайплайны, позволяющие переключаться между инструментами (поиск, базы, симуляторы) и разными окружениями.
В итоговом видении Deep Research — это шаг от «реактивного ассистента» к активному ИИ‑исследователю, который:
- планирует,
- ищет,
- проверяет,
- и формирует знание с опорой на прозрачные доказательства.
Если эта линия будет успешно развиваться, у нас действительно появится не «поисковик с чатиком», а класс систем, к которым можно будет доверять сложные научные и инженерные задачи — при условии, что человек останется в роли архитектора целей и критика выводов.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/