OpenAI выложила в open‑source небольшой, на первый взгляд не впечатляющий LLM: всего 0,4 млрд параметров, но с радикальной особенностью — 99,9% весов обнулены. Это демонстрация подхода Circuit Sparsity, в котором модель изначально проектируется как почти пустая, а внутри неё вырастают лишь минимально необходимые «цепи» для решения задач.
Цель такого экстремального обнуления — не производительность, а понятность: превратить ход вычислений модели в нечто, похожее на схемотехнику, где:
- есть чётко выделенные проводники (ненулевые веса),
- отдельные функциональные блоки,
- и возможность проследить, как конкретный сигнал идёт от входа к ответу.
Почему «отрезание 99,9%» делает модель понятнее
В обычных трансформерах:
- матрицы весов плотные,
- информация распределена по множеству нейронов,
- одна и та же концепция «размазана» по десяткам и сотням узлов.
Это даёт гибкость, но разрушает локализуемость: нельзя честно сказать, какой именно параметр «отвечает» за конкретную часть рассуждения.
Circuit Sparsity делает несколько шагов:
- Жёстко минимизирует L0‑норму весов, заставляя почти все связи стать нулевыми.
- Оставляет крошечную долю активных связей, по которым действительно бегут сигналы.
- Для каждой задачи вырезает минимальный рабочий контур (minimal circuit) — подграф, являющийся и необходимым, и достаточным.
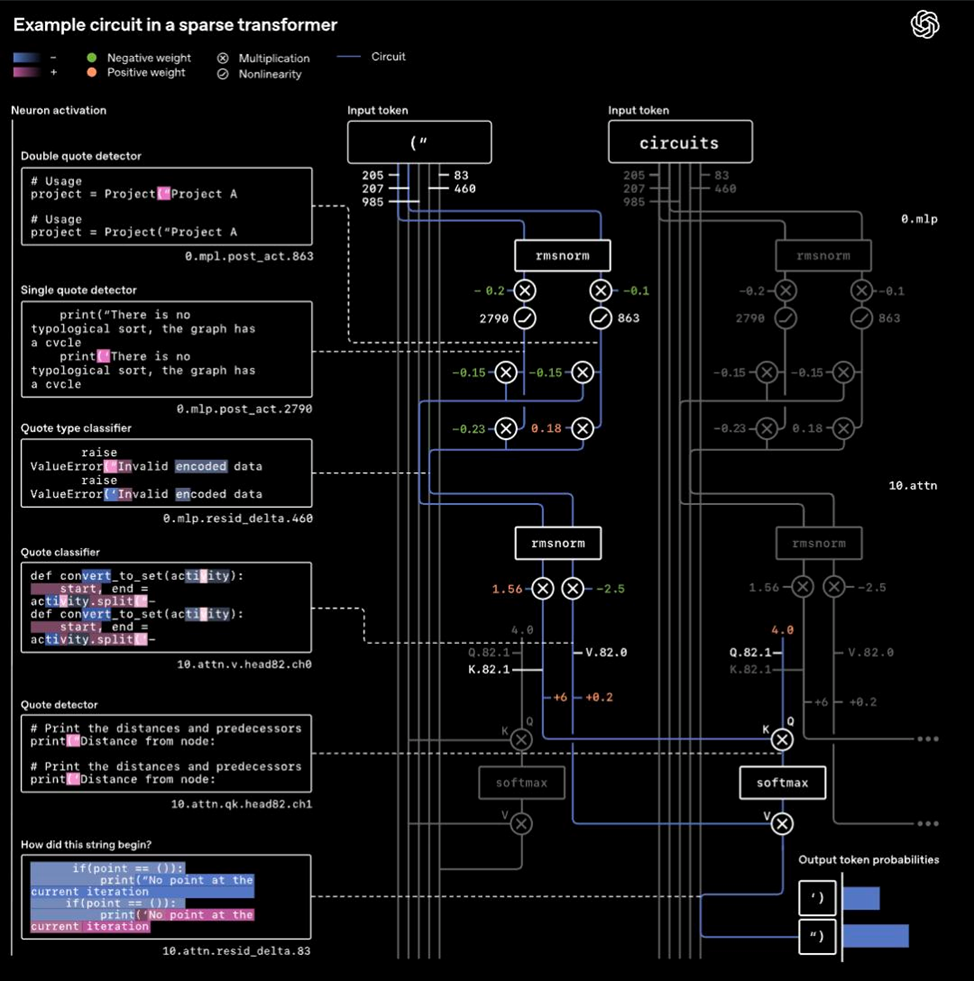
Пример из статьи: задача проверки правильного закрытия кавычек в Python. Для её решения оказывается достаточно:
- двух нейронов в MLP‑слое и
- одной головы внимания.
Этого мини‑контура хватает, чтобы:
- обнаружить кавычки,
- различить их тип,
- отследить соответствующие пары в контексте.
Удалите любой элемент — и задача ломается. То есть это не просто «где‑то там участвует несколько сотен параметров», а строго очерченная цепочка, без которой модель не справляется.
Почему это интереснее для объяснимости, чем MoE
Сегодня основной индустриальный способ приблизиться к разреженности — Mixture of Experts:
- модель разделяют на экспертов (подсети),
- специальные «ворота» направляют запрос к части экспертов,
- на каждом шаге работает лишь небольшой поднабор параметров.
MoE хорошо ложится на оборудование, даёт выигрыш по FLOPs, но:
- эксперты всё равно внутри плотные,
- функциональные границы между ними размыты,
- знания дублируются, manifold признаков «рвётся» на фрагменты,
- балансировка нагрузки и стабильность требуют сложной настройки.
Circuit Sparsity, наоборот, стремится к изначально структурированной, «родной» разреженности:
- представления проецируются в огромное пространство,
- активируется строго ограниченное число узлов,
- каждый узел максимально специализирован под одну функцию.
Так получаются блоки, которые можно:
- изучать изолированно,
- визуализировать как «электрические схемы»,
- модифицировать точечно — отключая или перенастраивая конкретный механизм.
Это открывает путь к гораздо более серьёзной интерпретации: мы начинаем не гадать о скрытых паттернах, а видеть микромеханизмы рассуждений.
Огромная цена за ясность: 100–1000× дороже по вычислениям
У подхода есть и очевидная тёмная сторона:
- нынешняя реализация требует в 100–1000 раз больше вычислений, чем сопоставимая плотная модель,
- по качеству такая маленькая сеть неизбежно далека от современных флагманов.
MoE при этом остаётся оптимальным компромиссом:
- отлично поддерживается фреймворками,
- даёт хорошее соотношение «качество/стоимость»,
- уже доказал масштабируемость в реальных продуктах.
Поэтому Circuit Sparsity сейчас — это инструмент научного анализа, а не замена продакшн‑архитектурам. Тем не менее он задаёт другую планку: не только скорость и размеры, но и разборчивость внутренних механизмов.
Как можно обойти ограничение по стоимости
Исследователи видят два практичных направления:
- Извлекать разреженные контуры из уже обученных плотных LLM.
Вместо того чтобы заново тренировать разрежную модель, можно:
- взять большую dense‑модель,
- проанализировать её поведение на конкретной задаче,
- «выкопать» минимальный необходимый подграф.
Это резко удешевляет процесс и превращает Circuit Sparsity в метод анализа, а не обучение «с нуля».
- Ускорять «нативно» разрежные модели.
То есть не отказываться от идеи исходно объяснимой сети, но:
- развивать специализированные библиотеки для настоящей разреженной матричной алгебры,
- улучшать методы обучения, чтобы сделать их устойчивыми и более дешёвыми.
Если эти направления выстрелят, можно получить класс моделей, у которых:
- достаточная для практики мощность,
- при этом внутренние цепи рассуждений доступны для аудита.
В более широком контексте Circuit Sparsity — это часть попытки превратить LLM из чёрных ящиков в системы, которые можно «разобрать» до уровня минимальных схем.
Если у нас получится увидеть, какие именно подграфы отвечают за ложные обобщения, токсичное поведение или выдуманные факты, появится шанс не просто штрафовать модель внешними стимулами, а чинить её на уровне схемотехники. Это может стать ключевым шагом к надёжному и поддающемуся сертификации ИИ.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/