🚀 DeepSeek-V3.2: как открытая модель догнала GPT-5
📅 2 декабря 2025 года команда DeepSeek-AI представила исследование "DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models", доказывающее: открытые модели могут конкурировать с лучшими закрытыми системами.
📍 В чём была проблема
Последние месяцы открытые модели начали отставать от GPT-5 и Claude по трём направлениям: медленная работа с длинными текстами, слабые рассуждения на сложных задачах и неумение пользоваться инструментами как настоящий ИИ-агент.
⚡️ Три решения учёных
1. Умное внимание вместо полного перебора
Представьте библиотеку на 128 000 книг. Обычная модель листает все подряд. DeepSeek научили выбирать сразу 2048 самых нужных — работает в разы быстрее без потери точности.
Технически это называется Sparse Attention: модель использует "быстрый индексатор" (маленькая нейросеть), который за один проход определяет, какие части текста действительно важны для ответа.
2. Серьёзное обучение на ошибках
DeepSeek потратила более 10% всего бюджета на дообучение через reinforcement learning — когда модель учится на своих успехах и провалах.
Результат: модель научилась рассуждать пошагово, замечать свои ошибки и исправлять их — как это делают топовые закрытые системы.
3. Виртуальные тренажёры для агентов
Команда создала автоматический конвейер генерации задач: 1827 виртуальных окружений и 85 000 заданий, где модель училась искать информацию, писать код, работать с файлами.
Пример: "Спланируй трёхдневное путешествие по Китаю с бюджетными ограничениями" — модель должна использовать 14 инструментов для поиска отелей, ресторанов, билетов и соблюсти все условия.
📊 Что получилось
DeepSeek-V3.2 достигла уровня GPT-5:
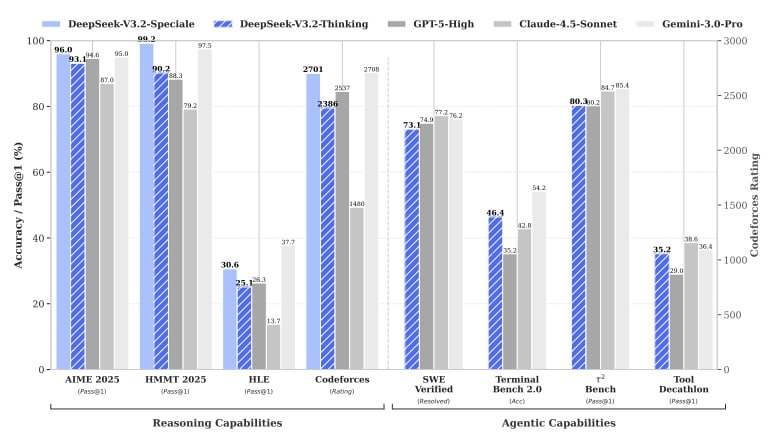
✅ Олимпиадная математика: 93% решённых задач (GPT-5: 94.6%)
✅ Программирование: рейтинг 2386 на Codeforces — топ-0.3% в мире
✅ Real-world задачи: 73% решённых багов в реальном коде (лучший результат среди открытых моделей)
Специальная версия без ограничений на размышления взяла золото на математических и программистских олимпиадах — впервые для открытой модели.
💡 Что это значит для ИИ-индустрии
1️⃣ Открытые модели могут догнать закрытые при правильной архитектуре и достаточных вычислениях на обучение. DeepSeek доказала это на практике.
2️⃣ Не нужно обрабатывать весь текст целиком. Умный выбор важных частей экономит ресурсы без потери качества — это делает длинные контексты практичными для реального использования.
3️⃣ Автоматическая генерация задач позволяет обучать агентов в масштабе без сбора реальных пользовательских данных — это меняет экономику разработки ИИ-систем.
Команда честно отмечает ограничения: модель пока знает меньше фактов и использует больше слов для ответа, чем Gemini. Но главное доказано — разрыв между open-source и закрытыми системами можно сокращать.
📄 Исследование: https://arxiv.org/abs
#AIWiz #DeepSeek #ИИдлТекста