Mistral 3
Mistral Large 3 - флагман:
• 675B параметров (активны 41B)
• Sparse Mixture-of-Experts (MoE) - первая MoE-модель Mistral после легендарной Mixtral
• Мультимодальность: текст + изображения (визуальный энкодер на 2.5B параметров)
• Контекстное окно 256K токенов
• Обучена с нуля на 3000 GPU NVIDIA H200
Ministral 3 - семья компактных моделей для edge-устройств:
• Три размера: 3B, 8B, 14B параметров
• Для каждого размера три варианта: Base, Instruct, Reasoning
• Все с поддержкой изображений и мультиязычности
• Могут работать на ноутбуках, смартфонах, дронах😏
🔘Характеристики
Производительность Mistral Large 3:
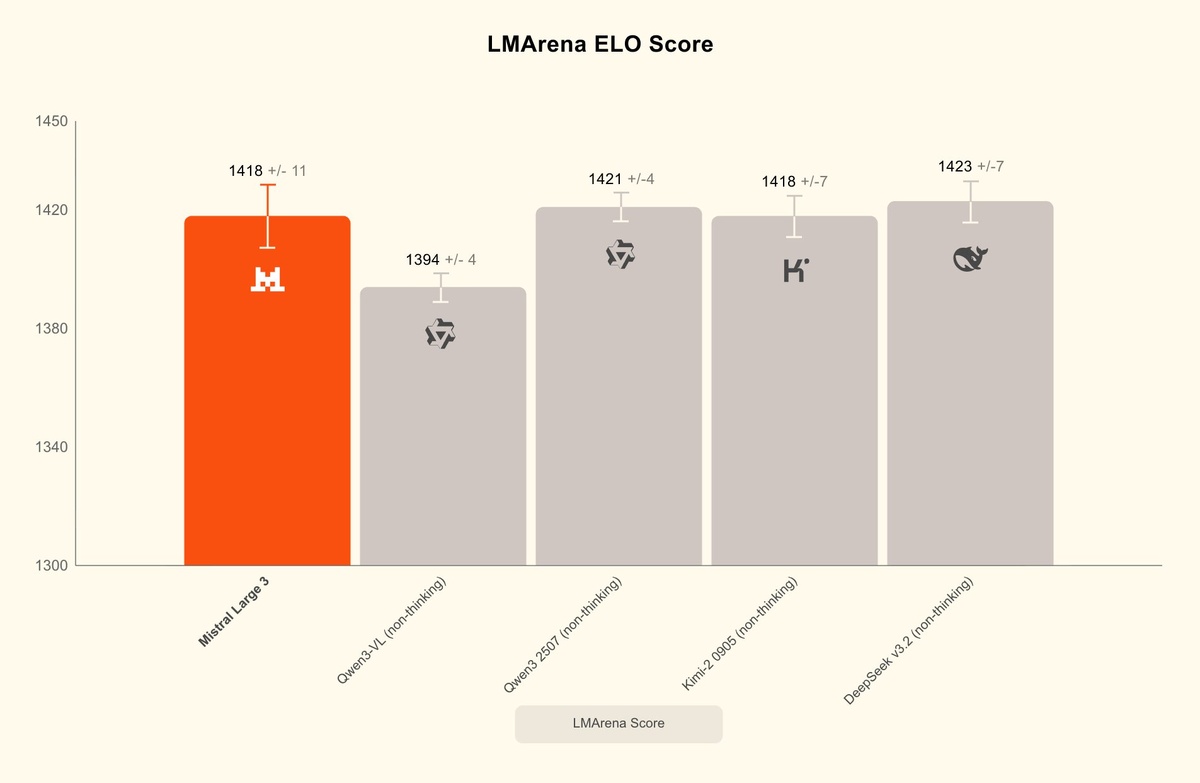
• #2 в LMArena среди open-source моделей без reasoning (#6 в общем зачёте)
• 81% точности на MMLU benchmark
• Лучшая модель для неанглоязычных диалогов
• Конкурирует с GPT-4 и Claude, оставаясь открытой
Ministral 3:
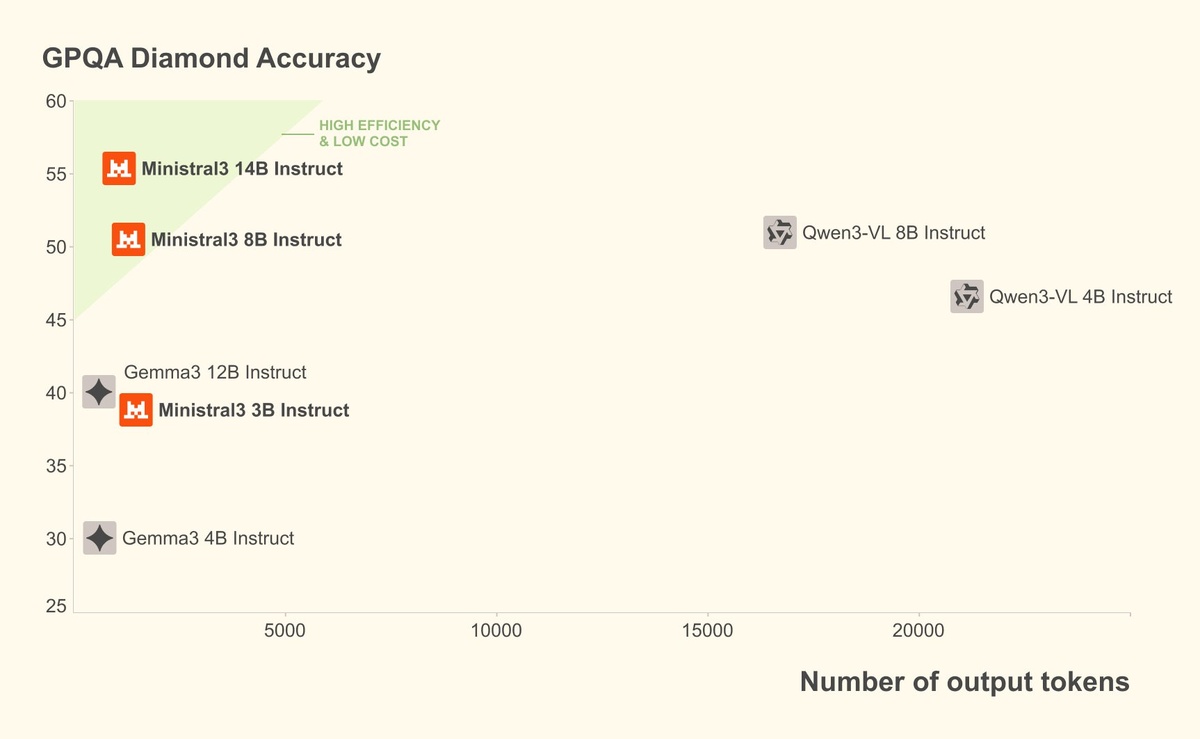
• 14B Reasoning: 85% на AIME 2025 - задачи олимпиадного уровня по математике
• Лучшее соотношение цена/качество среди всех open-source моделей
• Генерирует на порядок меньше токенов при той же точности = экономия денег
• Работает на одной RTX 4090 или даже на Mac с 32GB RAM
Все модели Mistral 3 понимают изображения нативно (не через костыли), поддерживают 40+ языков с рождения, собенно сильны в европейских, азиатских и арабском языках
256K контекст = анализ целых книг или огромных кодовых баз
🔘Агентные возможности
• Нативный function calling
• JSON structured output
• Интеграция с MCP (Model Context Protocol)
• Лучшие в классе возможности для работы с инструментами
• Быстрое выполнение функций для автоматизации
🔘API Pricing
Mistral Large 3: $0.50 за 1M входных токенов, в 3.5x дешевле, чем GPT-4, при сопоставимом качестве
Massive 256K контекст по той же цене
Все модели под Apache 2.0
Ministral 3 3B можно запустить на 4GB видеопамяти
🔘Бенчмарки
MMLU: 81% (топ среди open-source)
AIME 2025: 85% у 14B reasoning
GPQA Diamond: state-of-the-art с минимальным количеством токенов
LMArena: #2 среди non-reasoning open-source моделей
Multilingual: лучшие на non-English/non-Chinese диалогах
Hugging Face: Mistral-Large-3 | ministral-3