Такой вывод можно сделать из сенсационного исследования специалистов Университета Мэриленда и компании Microsoft. Но с некоторыми оговорками.

30 сентября в онлайн-архиве научных статей arXiv.org появилась публикация о том, насколько точно большие языковые модели отвечают на вопросы, сформулированные на разных языках.
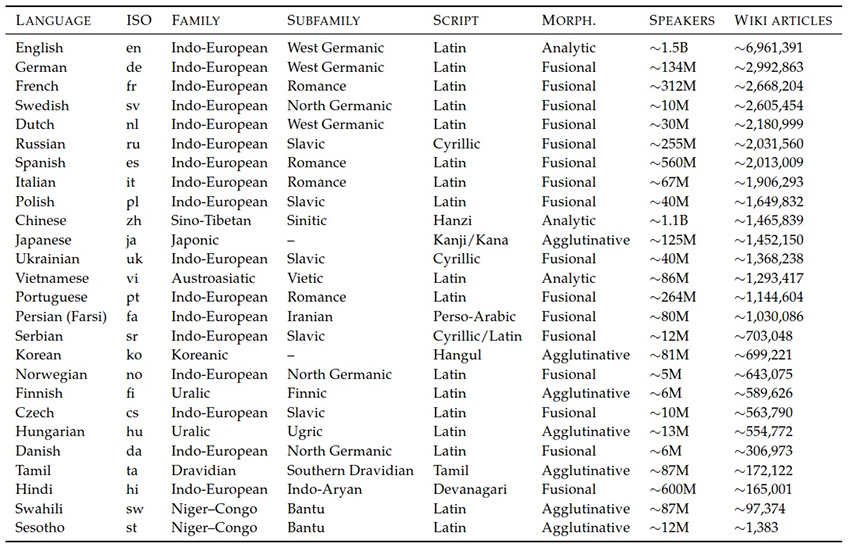
Использовались 26 языков, от самых распространенных до довольно
экзотических (во всяком случае для Интернета). Вот их список с данными
по числу «пользователей» и по представительству в сети, измеренному
через количество статей в «Википедии».
В качестве подопытных нейросетей были выбраны Llama (от известной
экстремистской организации Meta), Qwen (от мирной китайской компании
Alibaba), Gemini (Google) и OpenAI.
Для тестирования составлялись специальные промты на 26 языках, в
большинстве представляющие собой задачи типа «иголка в стоге сена»: от
ИИ требовалось найти данные, спрятанные в длинном тексте. Русскую
словесность в исследовании достойно представила «Война и мир» Льва
Толстого. Этот «наборов слов» оказался самым большим. Впрочем, для
тестов брались равновеликие отрывки объемом по 8000, 32 000, 64 000 и
128 000 токенов, единиц, на которые нейросеть разбивает текст в процессе
анализа. Чаще всего токены напоминают слоги.
Результат, на первый взгляд, получился сенсационный.
Вот как его формулируют авторы статьи: «Английский и китайский
доминируют в обучающих данных большинства современных языковых моделей, и
поэтому можно было ожидать, что именно они окажутся лучшими. Однако при
длинах контекста 64K и 128K мы неожиданно наблюдаем, что польский язык
показывает лучшие результаты в задачах типа «иголка в стоге сена» – со
средней точностью 88% по всем моделям. Английский при этом занимает лишь
6-е место из 26 со средней точностью 83,9%. Ещё удивительнее то, что
китайский оказывается четвертым с конца – его средняя точность
составляет 62,1%».
Поскольку сразу вслед за польским разместился русский язык, Рунет
взорвался статьями о том, что с ИИ надо говорить на великом и могучем,
который оказался более понятным нейросетям, чем язык Шекспира, Гейтса и
прочих Вильямов. А происходит это потому, что особенности морфологии,
синтаксиса и наличие падежей, от которых рыдают иностранцы, с точки
зрения ИИ уменьшают двусмысленность выражаемых по-русски мыслей.
Повод для законной гордости, конечно, есть. Но необходимы некоторые пояснения.
Результаты выше показывают, насколько точно понимает ИИ польский язык
при работе именно с польским текстом, русский – с русским, а английский
– с английским. Но если вы намерены искать информацию во всемирном
масштабе, то тут картина несколько иная. К сожалению, авторы
исследования провели лишь несколько межязыковых тестов, когда запрос
составлялся на одном языке, а текст для поиска брался на другом, но из
таблицы ниже видно, что если вы хотите поработать с информацией,
например, на корейском языке, но его не знаете, то спрашивать лучше
все-таки по-английски, а не по-польски.
С другой стороны, из этой же таблицы выходит, что корейцам даже при
работе с родными корейскими текстами лучше общаться с ИИ по-английски. К
польскому и русскому, как и к французскому, итальянскому и испанскому
это, очевидно, не относится. В отношении других языков требуется
дополнительное исследование. Включая китайский.
Вообще, конечно, забавно, что нейросети «думают» на «родном»
английском хуже, чем на «иностранных» польском и русском (хотя в случае с
китайским ИИ это не так уж удивляет). Впрочем, возможно, это не
обязательно связано с неким расовым превосходством носителей этих
языков. В конце концов, быть однозначным – не такое уж и очевидное
достоинство.
Приведем простой пример. В русском самым многозначным считается слово
«идти», у которого, по данным академического «Большого толкового
словаря русского языка» под ред. С.А. Кузнецова, зафиксировано 26
основных и 14 фразеологически связанных значений («идти пешком», «идет
дождь», «часы идут», «идет фильм», «идет война» и т.д.). В английском
же, по данным составителей Оксфордского словаря, самым многозначным
оказалось схожее слово run, у которого они насчитали… 645 значений.
Другой пример. Как известно, словарный запас произведений Пушкина и
Шекспира был приблизительно равным – около 25 000 слов. Вот только
Шекспир жил на 200 лет раньше. Думается, этот гандикап не до конца
ликвидирован и сегодня.
Напомним высказывание Набокова о двух языках, один из которых был ему
родным, а второй принес литературную славу: «Телодвижения, ужимки,
ландшафты, томление деревьев, запахи, дожди, тающие и переливчатые
оттенки природы, все нежно-человеческое (как ни странно!), а также все
мужицкое, грубое, сочно-похабное, выходит по-русски не хуже, если не
лучше, чем по-английски; но столь свойственные английскому тонкие
недоговоренности, поэзия мысли, мгновенная перекличка между
отвлеченнейшими понятиями, роение односложных эпитетов – все это, а
также все относящееся к технике, модам, спорту, естественным наукам и
противоестественным страстям – становится по-русски топорным,
многословным и часто отвратительным в смысле стиля и ритма».
В любом случае человеческие языки создавались не для удобства ИИ, и
то, что некоторые из них ему больше «понравились», возможно, не так уже
для них лестно. Кроме того, предложенные нейросетям на этом «экзамене»
вопросы не требовали особого глубокомыслия. Просто в голову Андрея
Болконского, умирающего на Бородинском поле, посреди размышлений о
высоких облаках вдруг приходила удивительная мысль о том, что слову слон
соответствует число 47146, и все, что требовалось от ИИ, это правильно
ответить на вопрос, какое число этому слону соответствует. Отыскать
столь глубокий смысл в «Войне и мире» для ИИ почему-то оказалось легче,
чем в «Маленьких женщинах» Олкотт, «Бравом солдате Швейке» Гашека и даже
«Дон Кихоте» Сервантеса. Но на вопрос о том, будет ли ИИ, «думающий»
по-польски, лучше всех играть в шахматы, такой тест вряд ли прольет
много света.
А самое главное, что вышеприведенные результаты получены путем
усреднения по разным нейросетям, а если взглянуть на полную «турнирную
таблицу», то ситуация выглядит иначе.
Видно, что самой продвинутой из нейросетей оказалась Gemini 1.5 от
Google. И при работе с ней никакого особого преимущества польский или
русский не дают. Их «превосходство» образовалось из-за неспособности
пяти остальных языковых моделей адекватно справиться с английским
текстом. Но в принципе, «думать» по-английски не хуже, чем на любом
другом языке, видимо, не есть что-то совершенно невозможное для ИИ.
Вопрос лишь в «тренированности». Понятно, что языковые модели будут
быстро совершенствоваться и «недоучек» среди них станет все меньше, о
чем явно говорит разница между результатами двух версий китайской Qwen.
Есть уверенность, что даже с китайским нейросети рано или поздно
разберутся.
Похоже, ИИ скоро будет совершенно по барабану, на каком языке
общаться с кожаными мешками, так что разговаривать с ним действительно
лучше на том наречии, на котором пользователю самому легче точно
сформулировать свою мысль и, что еще важнее, усвоить ответ. В любом
случае, не следует ждать, что Microsoft начнет срочно переводить всю
свою документацию на польский язык для повышения эффективности своих
языковых моделей. А уж перетолмачивать для удобства ИИ на английский
русские тексты, если это вдруг придет в голову каком-нибудь «Газпрому», и
вовсе бессмысленно.
Источник: НИКС - Компьютерный Супермаркет