Представляем вашему вниманию интересное исследование Бондаренко А.Г. и Кравец А.Г. "Идентификация ключевых технологий на основе сбора и анализа данных из открытых русскоязычных источников".
Известия ЮФУ. Технические науки. 2025. №3 (245). URL: https://cyberleninka.ru/article/n/identifikatsiya-klyuchevyh-tehnologiy-na-osnove-sbora-i-analiza-dannyh-iz-otkrytyh-russkoyazychnyh-istochnikov
▎Актуальность и цели исследования
Актуальность исследования обусловлена необходимостью разработки новых подходов к анализу технологических тенденций, основанных на обработке открытых данных на русском языке.
Основной целью исследования является разработка и апробация нового подхода к сбору, обработке и анализу открытых данных для идентификации ключевых технологических направлений. Сбор, обработка и анализ открытых данных с использованием методов веб-скрейпинга и анализа текстовых данных позволит выявить ключевые технологические термины и тенденции, а также сформировать перечень технологий для дальнейшего анализа патентной активности.
▎Ход исследования
В рамках исследования реализован метод веб-скрейпинга для сбора данных о технологиях из открытых русскоязычных источников, включая научные статьи, новостные ресурсы и патенты.
Результатом этого процесса является формирование структурированных датасетов. Полученные данные, после предварительной обработки, представляются в виде наборов ключевых терминов (биграмм и триграмм) и их частотности. Это позволяет определить перечень технологий, которые в дальнейшем используются для фильтрации патентной информации.
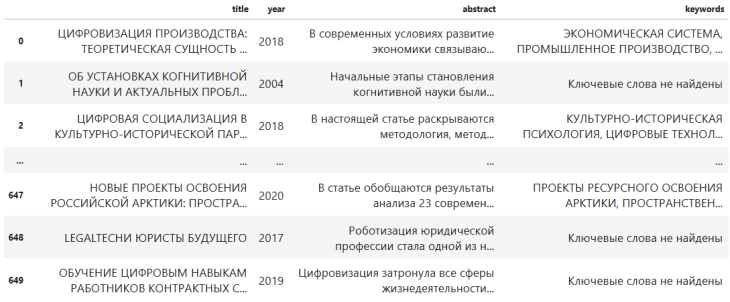
Для сбора данных из научных статей выполняется поиск ссылок на публикации. Полученные URL-адреса сохраняются в текстовый файл, где каждая ссылка отделена переносом строки.
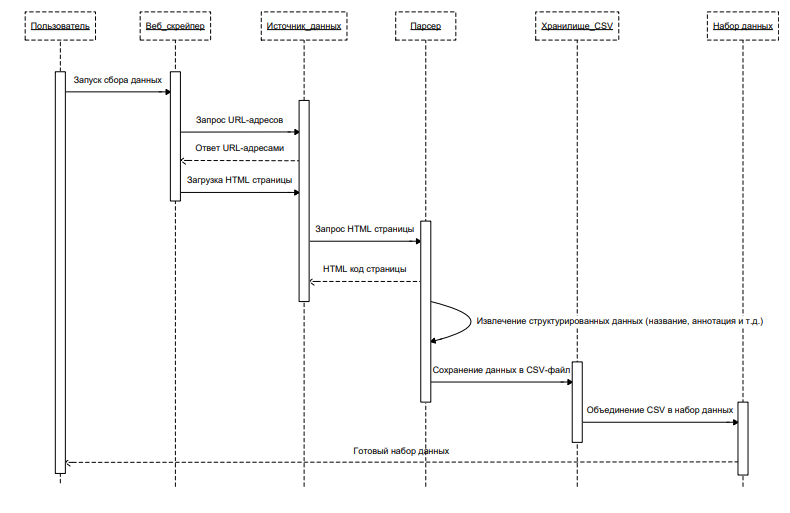
Для извлечения структурированных данных из этих веб-страниц разработан специализированный веб-скрейпер. Этот веб-скрейпер предназначен для сбора данных с сайта eLibrary. Он обеспечивает авторизацию на сайте посредством Selenium, с использованием логина и пароля, и работает в headless-режиме браузера. Ссылки на страницы статей загружаются из созданного текстового файла. Далее, Selenium загружает HTML-код каждой страницы, а BeautifulSoup извлекает необходимые данные: название статьи, год публикации, аннотацию и ключевые слова. Ключевые слова извлекаются из таблиц с определенной структурой.
Для расширения базы данных исследования, включающей информацию о технологических трендах выполняется сбор URL-адресов новостных источников. Этот этап реализуется посредством JavaScript-скрипта, предназначенного для автоматического сбора ссылок на новостные веб-сайты.
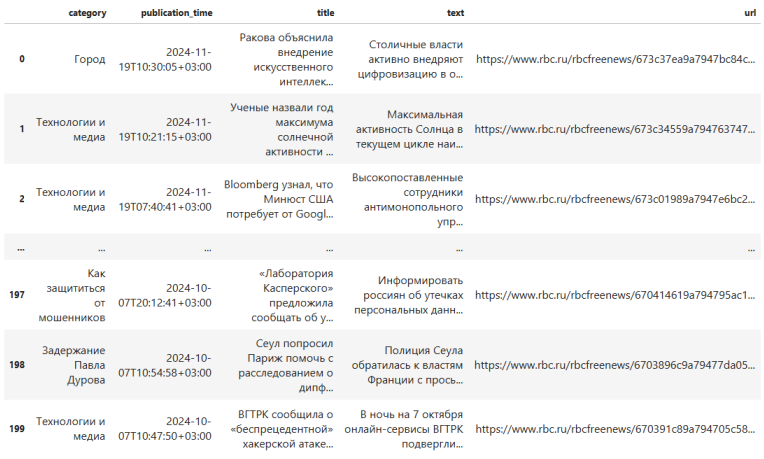
Принцип сбора данных с новостных ресурсов аналогичен процессу, применяемому для научных статей. Разработанный Python-скрипт использует библиотеки Selenium и BeautifulSoup для анализа структуры веб-страниц и извлечения необходимых данных из списка полученных URL-адресов. Скрипт автоматически собирает информацию о категории новости, времени публикации, заголовке и полном тексте новостной статьи. Полученные структурированные данные затем агрегируются и сохраняются в CSV-файл для дальнейшей обработки и анализа.
Сбор данных из патентов. Для проведения анализа технологических трендов в качестве источника патентной информации используется датасет, который состоит из 89 отдельных файлов. Каждый файл содержит данные о патентах, относящихся к определенной технологической области.
Анализ объединенного датасета патентов демонстрирует недостаточность текстовых данных для проведения полноценного анализа. В связи с этим, на текущем этапе принято решение о дополнении датасета аннотациями к патентам. Для этого разработан процесс автоматизированного сбора описаний патентов посредством парсинга URLссылок, содержащихся в исходном датасете. На первом этапе извлекаются все доступные ссылки на патентные описания. Затем эти ссылки передаются специально разработанному парсеру, который использует библиотеки Selenium и BeautifulSoup для извлечения аннотаций из веб-страниц.
Обработка сформированного датасета и выявление ключевых технологических терминов. Для последующего анализа и выявления ключевых технологических терминов все текстовые данные, извлеченные из различных источников, на текущем этапе подвергаются ряду процедур обработки.
Анализ частотности биграмм и триграмм позволил выявить доминирующие термины. Гистограммы позволяют идентифицировать ключевые технологии и выявить наиболее значимые сочетания слов, отражающие основные концепции и направления в технологических областях. Данная информация послужит основой для дальнейшего анализа и формирования перечня технологий, которые будут использованы для фильтрации патентной информации.
Формирование временных рядов ключевых терминов и анализ патентной активности. На основе полученных данных биграмм и триграмм идентифицирован ряд ключевых технологий. Следующим шагом исследования стала разработка метода идентификации ключевых технологий (МИКТ) на основе анализа временных рядов патентной активности.
▎Результаты исследования
▎Заключение
В рамках проведенного исследования был разработан и реализован комплексный подход к сбору, обработке и анализу открытых данных с целью идентификации ключевых технологий. Разработка метода веб-скрейпинга, использование методов обработки естественного языка и анализа временных рядов позволило сформировать структурированные датасеты. На основе анализа частотности биграмм и триграмм были выделены ключевые технологические термины, которые в дальнейшем легли в основу для МИКТ. В рамках исследования проанализированы исключительно русскоязычные документы, что позволяет учитывать специфику отечественного технологического развития.