
Druid – это высокопроизводительная, распределенная база данных для аналитики в реальном времени (real-time analytics database). Она создана для быстрых OLAP-запросов (Online Analytical Processing) по большим наборам данных. Druid идеально подходит для сценариев, где требуется мгновенная обработка и визуализация потоковых или исторических данных, таких как бизнес-аналитика, мониторинг сетевых событий, анализ пользовательского поведения и IoT-аналитика.
Основные функциональные возможности
Ключевые особенности Apache Druid делают его мощным инструментом для интерактивной аналитики:
- Колоночное хранение: Данные хранятся в колоночном формате, что значительно ускоряет запросы с агрегациями, так как с диска считываются только необходимые для запроса столбцы.
- Аналитика в реальном времени: Druid спроектирован для мгновенного приёма данных (ingestion) из потоковых источников, таких как Apache Kafka или Amazon Kinesis. Данные становятся доступными для запросов практически сразу после поступления.
- Оптимизация для временных рядов (Time-series): Все данные в Druid обязательно партиционируются по временной метке (__time). Такая архитектура обеспечивает сверхбыстрые запросы с фильтрацией по временным диапазонам.
- Предварительная агрегация (Roll-up): Во время приёма данных Druid может агрегировать сырые данные, уменьшая их итоговый объем и значительно ускоряя запросы. Например, вместо хранения каждой отдельной метрики можно хранить их суммы или средние значения за минуту.
- Масштабируемая распределенная архитектура: Druid состоит из набора микросервисов, каждый из которых выполняет свою роль. Это позволяет независимо масштабировать различные компоненты кластера в зависимости от нагрузки.
- Два API для запросов: Поддерживает как собственный JSON-based API, так и стандартный SQL, что упрощает интеграцию с BI-инструментами (такими как Apache Superset, Tableau).
Плюсы и минусы
Плюсы:
- Невероятно быстрые OLAP-запросы: Время ответа на агрегирующие запросы обычно составляет от долей секунды до нескольких секунд даже на петабайтных наборах данных.
- Приём данных в реальном времени: Отлично справляется с потоковой передачей данных, делая их доступными для анализа «на лету».
- Горизонтальная масштабируемость и отказоустойчивость: Архитектура позволяет легко добавлять новые узлы для увеличения производительности и надежности.
- Эффективное хранение: Благодаря колоночному формату, сжатию и опциональной предварительной агрегации, Apache Druid экономно использует дисковое пространство.
Минусы:
- Сложная архитектура: Кластер Druid состоит из множества различных типов узлов (services), что усложняет его развертывание и обслуживание по сравнению с монолитными системами.
- Ограниченная поддержка JOIN-операций: Изначально Druid не поддерживал JOIN-операции на уровне запросов. Хотя эта функциональность была добавлена, она имеет ограничения и не так эффективна, как в традиционных реляционных СУБД. Druid не предназначен для замены хранилища данных, где требуются сложные соединения таблиц.
- Нет точечных обновлений/удалений: Druid оптимизирован для вставки и массового чтения. Обновление или удаление отдельных записей является сложной и неэффективной операцией.
Архитектура и особенности реализации
Архитектура Apache Druid — это его главная особенность. Кластер состоит из набора специализированных сервисов (узлов):
- Broker: Принимает запросы от клиентов, определяет, какие сегменты данных содержат нужную информацию, и направляет подзапросы на узлы Historical и MiddleManager. Затем собирает и возвращает итоговый результат.
- Router: (Опционально) Умный прокси-сервер, который направляет запросы к брокерам, а запросы на приём данных — к оверлордам.
- Coordinator: Управляет сегментами данных на исторических узлах (Historical). Он отвечает за загрузку, выгрузку и репликацию сегментов, обеспечивая балансировку и доступность данных.
- Overlord: Управляет задачами приёма данных. Он принимает задачи, координирует их выполнение и управляет состоянием узлов MiddleManager.
- Historical: Хранит неизменяемые сегменты данных и обслуживает запросы к ним. Это «рабочие лошадки» для запросов по историческим данным.
- MiddleManager: Принимает новые данные (в том числе из потоков), создает новые сегменты и передает их в долговременное хранилище (Deep Storage) для последующей загрузки узлами Historical.
Иллюстрация архитектуры Druid:
Схематичное изображение взаимодействия всех компонентов можно найти в официальной документации.
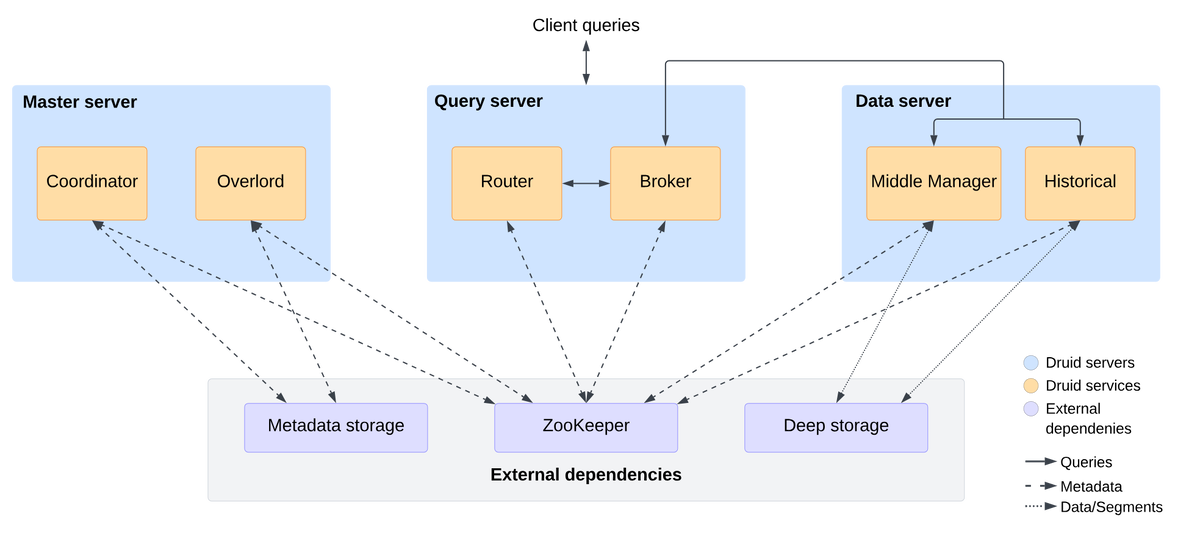
Ссылка на диаграмму архитектуры с официального сайта Apache Druid
Best Practices
- Продуманная схема данных: Тщательно выберите измерения (dimensions) — столбцы, по которым вы будете фильтровать и группировать, и метрики (metrics) — столбцы, которые вы будете агрегировать (COUNT, SUM, AVG).
- Используйте Roll-up: Включайте предварительную агрегацию при приёме данных, если вам не нужна гранулярность до каждой отдельной записи. Это значительно сократит размер данных и ускорит запросы.
- Оптимальный размер сегмента: Стремитесь к тому, чтобы размер сегментов данных находился в диапазоне 300-700 МБ. Слишком мелкие или слишком большие сегменты могут негативно сказаться на производительности.
- Правильное партиционирование: Помимо обязательной партиции по времени, можно использовать дополнительное партиционирование по измерениям с высокой кардинальностью для дальнейшей оптимизации.
- Выбирайте правильный тип запроса: Используйте нативные запросы TopN вместо GroupBy для получения топ-N результатов — они намного эффективнее.
Troubleshooting и Тюнинг
- Медленные запросы:Проверьте, не сканирует ли запрос слишком много сегментов. Оптимизируйте временной диапазон.
Убедитесь, что на узлах Broker и Historical достаточно памяти для кэширования.
Проанализируйте план запроса. Возможно, стоит пересмотреть схему данных или использовать другой тип запроса. - Проблемы с приёмом данных:Следите за логами Overlord и MiddleManager (или Indexer).
Увеличьте количество task slots на MiddleManager, если задачи на приём данных стоят в очереди. - Тюнинг JVM: Каждый тип узла Druid имеет свои требования к памяти. Тщательно настройте параметры кучи (heap) Java для Broker, Historical и MiddleManager, чтобы избежать проблем с производительностью и сборкой мусора.
- Кэширование: Настройте кэширование на уровне Historical (для данных сегментов) и Broker (для результатов запросов), чтобы ускорить повторяющиеся запросы.
Примеры с кодом
1. Пример спецификации для приёма данных (Ingestion Spec):
Это JSON-объект, описывающий, как Druid должен загрузить данные.
2. Пример запроса на Druid SQL:
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант"