MergeTree – это семейство движков таблиц в ClickHouse, разработанное для хранения данных, отсортированных по первичному ключу. Эти движки обеспечивают высокую производительность для широкого спектра аналитических запросов, поддерживая быструю вставку данных и их последующую фоновую обработку (слияние кусков данных). Семейство MergeTree engine является основой для большинства высоконагруженных задач в ClickHouse.
Основные функциональные возможности
Движки семейства MergeTree Engine предоставляют мощный набор функций для эффективной работы с большими объемами данных:
- Хранение данных, отсортированных по первичному ключу: Данные физически упорядочиваются на диске согласно выражению ORDER BY (первичный ключ). Это позволяет очень быстро выполнять запросы с фильтрацией по этому ключу или диапазону его значений.
- Партиционирование: Данные можно разбивать на отдельные части (партиции) по заданному критерию, обычно по месяцам или дням (PARTITION BY). Это ускоряет запросы, затрагивающие только определенные партиции, и упрощает управление данными (например, удаление старых партиций).
- Разреженный первичный индекс: ClickHouse не индексирует каждую строку, а только блоки данных (гранулы). Это экономит место и позволяет быстро находить нужные блоки данных для чтения. Размер гранулы задается настройкой index_granularity.
- Поддержка репликации и дедупликации (для ReplicatedMergeTree): ReplicatedMergeTree обеспечивает отказоустойчивость путем хранения копий данных на разных серверах и гарантирует консистентность данных между репликами. Также он позволяет выполнять дедупликацию вставляемых блоков данных.
- Манипуляции с данными: Поддерживаются операции ALTER для изменения структуры таблицы, удаления и обновления данных (хотя последние являются тяжеловесными операциями и реализуются через фоновые мутации).
- TTL (Time To Live): Возможность автоматически удалять устаревшие данные на уровне строк или целых партиций.
- Поддержка семплирования данных: Позволяет выполнять запросы на выборке данных для получения приблизительных результатов значительно быстрее.
Плюсы и минусы
Плюсы:
- Высочайшая производительность запросов: Особенно для аналитических запросов с агрегациями и фильтрацией по диапазонам благодаря сортировке и разреженному индексу.
- Эффективное сжатие данных: За счет сортировки однотипные данные располагаются рядом, что улучшает коэффициенты сжатия.
- Горизонтальная масштабируемость: Легко масштабируется путем добавления новых серверов (особенно с ReplicatedMergeTree).
- ️ Надежность: ReplicatedMergeTree обеспечивает отказоустойчивость.
- Быстрая вставка данных: Данные пишутся на диск быстрыми пачками (batches — part).
Минусы:
- Медленные обновления и удаления: Операции UPDATE и DELETE являются асинхронными и ресурсоемкими, так как требуют перезаписи целых кусков данных (parts). MergeTree Engine не предназначен для OLTP-нагрузок, с частыми точечными изменениями.
- Сложность выбора первичного ключа: От правильного выбора ORDER BY сильно зависит производительность.
- Неэффективен для запросов с фильтрацией по столбцам, не входящим в первичный ключ (без использования вторичных индексов).
Особенности реализации и использования
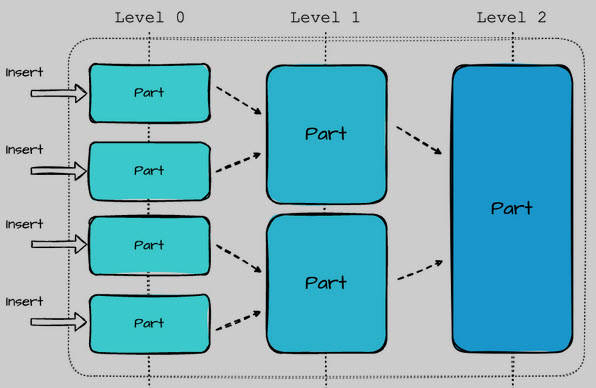
Данные в таблицах MergeTree хранятся в виде кусков (parts). Каждый кусок отсортирован по первичному ключу. При вставке новых данных создаются новые небольшие куски. ClickHouse периодически в фоновом режиме сливает (merges) эти куски в более крупные, поддерживая оптимальную структуру данных и эффективность.
Ключевые аспекты при создании таблицы:
- ENGINE = MergeTree(): Базовый движок.
- ORDER BY (expression): Определяет первичный ключ и порядок сортировки. Это самый важный параметр для производительности.
- PARTITION BY (expression): (Опционально) Определяет, как данные будут разбиты на партиции. Часто используется дата (например, toYYYYMM(EventDate)).
- SETTINGS index_granularity = 8192: Определяет количество строк в одной грануле индекса. Значение по умолчанию обычно подходит для большинства сценариев.
Пример создания таблицы:

В этом примере данные партиционируются по месяцам, а первичный ключ состоит из CounterID, EventDate и хеша UserID.
Best Practices использования MergeTree Engine
- Тщательно выбирайте первичный ключ (ORDER BY):Включайте столбцы, которые чаще всего используются в WHERE клаузах для фильтрации диапазонов.
Не делайте ключ слишком широким (много столбцов), это может замедлить вставку и слияния.
Порядок столбцов в ORDER BY имеет значение. - Используйте партиционирование разумно:Наиболее частый ключ партиционирования – дата (месяц, день).
Избегайте слишком гранулярного партиционирования (например, по секундам), это приведет к большому количеству кусков. - Оптимизируйте index_granularity: Стандартное значение (8192) хорошо подходит для большинства случаев. Уменьшение может улучшить скорость чтения для очень выборочных запросов, но увеличит размер индекса.
- Избегайте частых мелких вставок: Старайтесь вставлять данные большими пачками (сотни тысяч или миллионы строк за раз), чтобы уменьшить количество создаваемых мелких кусков.
- Мониторьте процесс слияния кусков: Слишком много кусков может замедлить запросы. Настройте параметры слияния при необходимости.
- Используйте ReplicatedMergeTree для production-сред: Это обеспечит отказоустойчивость.
- Для удаления и обновления данных используйте мутации (ALTER TABLE ... DELETE/UPDATE) с осторожностью: Помните, что это фоновые тяжеловесные операции.
Иллюстрация структуры кусков MergeTree Engine :
Troubleshooting и Тюнинг
Распространенные проблемы:
- Медленные запросы:Проверьте, используется ли первичный ключ в фильтрах.
Проанализируйте EXPLAIN запроса.
Слишком много кусков (parts) в таблице. Проверьте system.parts. - Слишком долгие слияния (merges):Большое количество мелких кусков.
Недостаточно ресурсов сервера (CPU, I/O). - Ошибка Too many parts: Увеличьте max_parts_in_total или оптимизируйте вставку/слияния.
Тюнинг:
- Параметры слияния:max_bytes_to_merge_at_max_space_in_pool: Максимальный общий размер кусков для слияния при максимальной доступности дискового пространства.
max_parts_to_merge_at_once: Максимальное количество кусков, объединяемых в одном слиянии.
Настройки находятся в конфигурационном файле ClickHouse (обычно config.xml или в профилях пользователей). - Настройки таблицы:merge_with_ttl_timeout: Частота проверки и выполнения TTL-слияний.
- Системные настройки:background_pool_size: Количество потоков для фоновых операций (включая слияния).
max_concurrent_queries: Ограничение одновременных запросов.
Пример проверки количества кусков:
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант"