Как и обещали, выкладываем статью про микст, она сложная, если будут вопросы, обязательно обсудим, пишите в комментариях!
Смешанный голос или микст-голос — это тип вокальной эмиссии (тип вокализации, тип атаки звука), которая эффективно «смешивает» тембровые характеристики механизмов работы гортани М1 (полный голос/грудной голос/тяжелый механизм) и М2 (фальцет/головной голос/легкий механизм) этот приём широко используется в художественной сфере, например, с целью сделать тембр вокальных регистров однородным в области перехода этих самых регистров.
Исторически одна из первых попыток физиологического определения смешанного голоса, относится к конференции Collegium Medicorum Theatri (CoMeT) в 1983 году. В то время были определены четыре регистра (#1; #2; #3; #4, предшественники нынешних M0, M1, M2 и M3), но внимание было уделено и еще одному регистру, обозначенному как #2A, который упоминается многими преподавателями вокала и определяется как смешанный голос. Он был помещен между №2 и №3, и, хотя его было трудно описать и продемонстрировать эмпирически, его считали существенным, учитывая его заметное распространение в среде преподавания вокала и пения.
С пересмотром концепции регистров и определения вокальных механизмов (M0, M1, M2 и M3) дискуссия о природе смешанного голоса возобновилась в свете новых научных открытий. В частности, вопрос заключался в том, можно ли считать смешанный голос самостоятельным гортанным механизмом или же он просто подразумевал — при наличии того же механизма — регулировку активности резонаторных полостей и источника с целью получения желаемых тембровых вариаций (характеристик голоса).
Благодаря электроглоттографии теперь стало возможным исследовать типы вокальной эмиссии певца по всему вокальному диапазону. Рассматривая отдельно диапазоны (частоту и интенсивность) издаваемых звуков в М1 (грудной режим работы гортани) и в М2 (фальцет, краевое смыкание голосовых складок). Если построить фонограмму певческого голоса с учетом полного расширения M1 и M2 (крайние тона певческого голоса в каждом механизме смыкания голосовых складок), то получим две области, которые частично перекрываются. Это означает, что каждый голос имеет возможность воспроизводить определенное количество нот (с различной интенсивностью) в режиме M1 или M2, независимо друг от друга.
Смотрите изображение №1.
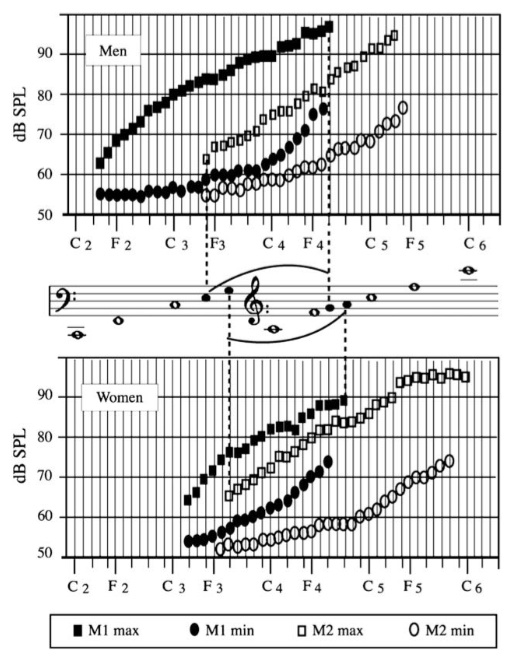
Из анализа фонетограмм, проведенного среди певцов и певиц, можно заметить, что область M1 в среднем больше у мужчин, тогда как область M2 в среднем больше у женщин. Однако область перекрытия M1 и M2 одинакова по амплитуде и частотному диапазону для обоих полов.
Смотрите изображение №2
и изображение №3.
На рисунке мы можем наблюдать фонетическую область, общую для механизмов М1 и М2. Эта область и может характеризовать смешанный голос. Исходя из вышесказанного, «смешанные» звуки могут воспроизводиться в разных режимах работы голосовых складок, как в М1 (микс 1), так и в М2 (микс 2), что иногда приводит к тому, что их очень трудно различить. Опытный певец на самом деле способен издавать звуки микс 1, имитирующие звуки M2, и звуки микс 2, имитирующие звуки M1. Однако с помощью электроглоттографии можно с уверенностью определить, какой именно механизм отвечает за данный смешанный звук. Таким образом, можно с достаточной уверенностью утверждать, что существуют два микса : микс 1, который производится в области фонетического перекрытия M1-M2, начиная с M1, и микс 2, который производится в области фонетического перекрытия M1-M2, начиная с M2. Простыми словами, опытный певец может маскировать разные режимы работы гортани в любой зависимости от творческой задачи.
Смотрите изображение №4.
Но в чем разница между звуками Микс 1 и Микс 2?
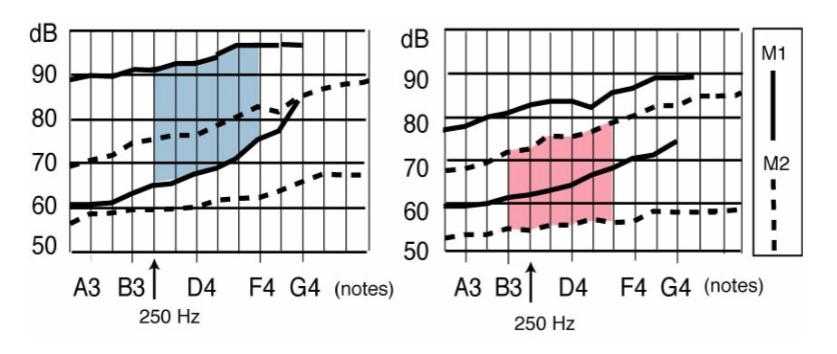
Если вы попросите опытного певца воспроизвести звуки на одинаковой частоте в Микс 1 и Микс 2, вы заметите, что звук Микс 2, как правило, имеет меньшую интенсивность (условно громкость). Однако, каким бы искусным ни был певец, существуют некоторые тембральные различия между звуками Микс 1 и Микс 2, при этом наблюдается большее гармоническое богатство, особенно в диапазоне 4–8 кГц, у звуков Микс 1.
Певца (в рассматриваемом исследовании – опытного контртенора) просят воспроизвести смешанные звуки, начиная с M1 (микс1), то можно заметить, что певец снижает интенсивность (условно громкость) примерно на 4 дБ и способен сжать (понизить) звук в частотном окне 6–8 кГц (рисунок 5). И наоборот, если попросить певца воспроизвести смешанный звук, начиная с M2 (микс2), мы увидим, что певец увеличивает интенсивность примерно на 3,5 дБ и усиливает гармоники между 6–8 кГц в спектре мощности. Великолепное мастерство исполнителя позволяет микшированным звукам достигать почти полной «акустической мимикрии» (совпадения) со звуками механизма, к которому они хотят приблизиться.
Смотрите изображение №5 и изображение №6.
Из имеющихся в настоящее время данных по этому вопросу можно сделать вывод, что смешанный голос, по-видимому, не представляет собой гортанный механизм сам по себе, а скорее это тип голосовой эмиссии, которая, начинается с определенного гортанного механизма (М1 или М2, то есть режимов работы голосовых складок) и – предположительно – посредством тонких модификаций источника и речевого тракта (настройки резонаторов), позволяет получать звуки, которые с точки зрения восприятия являются промежуточными между двумя механизмами или похожими один на другой механизм (микс 1, который имитирует М2, микс 2, который имитирует М1). Таким образом, можно утверждать, что существуют два смешанных регистра: Микс 1 и Микс 2, в зависимости от гортанного механизма, из которого они происходят. Перспективы будущего могут заключаться в изучении — до сих пор гипотетических — модификаций источника и голосового тракта, применяемых певцами для получения смешанных звуков различной природы с помощью таких методов исследования, как высокоскоростная эндоскопия и функциональная магнитно-резонансная томография.
Что это даёт педагогам по вокалу и вокалистам. Любой опытный певец, умея маскировать переход может спеть любую песню в любой тесситуре, используя разные режимы работы гортани, с правильно настроенным голосовым трактом (резонаторами) в зависимости от художественной задачи.
Перевод и выводы на основе материалов врача-хирурга, специалиста по отоларингологии, специалиста по профессиональной и художественной вокологии, фонохирургии Marco Fontini сделаны Евгением Марченковым.
Наш сайт:
https://sivvocal.ru
Мы в ВК:
https://vk.com/schoolsvoboda
Мы в Telegram:
https://t.me/sivvocal
Мы в Max:
https://max.ru/schoolsvoboda
Мы в Rutube:
https://rutube.ru/channel/789977
Мы в YouTube:
https://youtube.com/@sivvocal?si=cZHU7
5ooYk-N9qW8
C уважением, ваша «Свобода и воля»