По мере того как большие модели и агенты входят в реальные сервисы (образование, финансы, медицина, госуслуги, туризм и т.п.), всплывает критичный риск:
- диалоговые системы легко:
- поддаются prompt‑атакам (скрытые инструкции, злонамеренные наводящие вопросы),
- выдают незаконный/опасный контент,
- «галлюцинируют» регуляторные нормы, законы, факты.
- В августе 2025 г. центр МВД КНР протестировал коммерческие версии основных китайских LLM по новому стандарту GB/T45654‑2025:
- по 8 типам рисков (чёрный/серый рынок, слухи, мошенничество и т.д.)
- доля несоответствующих ответов — 28–51%,
- по ряду категорий (чёрный рынок, слухи, мошенничество) — >40%.
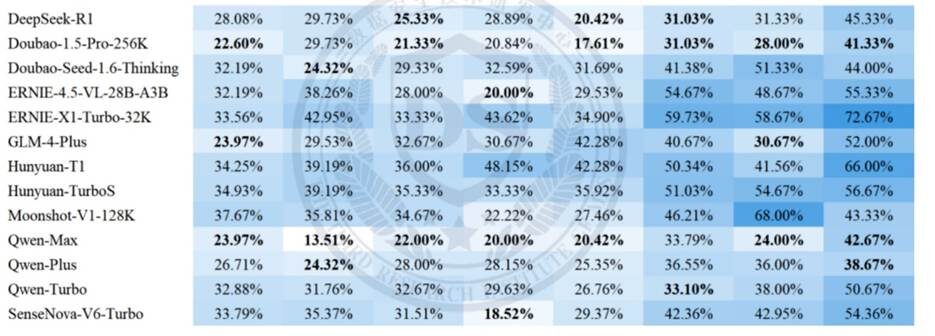
Вывод: без внешнего слоя защиты сами по себе модели слишком «дырявые» для регуляторно чувствительных сценариев.
Почему стандартные методы защиты больше не работают
Классический подход:
- фильтрация ключевых слов;
- немного «безопасного дообучения» основной модели.
Проблемы:
- Ключевые слова:
- легко обходятся (эвфемизмы, обфускация, многошаговые запросы),
- дают много ложных срабатываний (портят UX).
- Безопасное дообучение основной модели:
- жёсткая безопасность → часто падают способности модели,
- мягкая безопасность → остаются реальные дыры.
Параллельно появляются нормативные документы (вроде
«网络安全技术 生成式人工智能服务安全基本要求»), которые задают жёсткие красные линии для AI‑сервисов.
Разработчики агентов оказываются между:
- молотом регулятора,
- наковальней UX и качества модели.
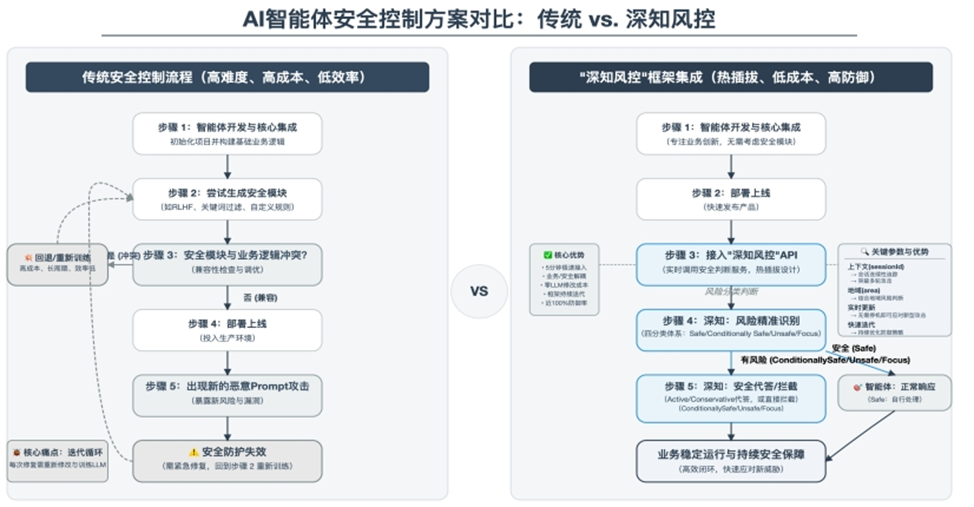
Решение DeepKnown («深知风控»): вынос безопасности в отдельный слой‑модель
Компания предлагает отдельный безопасностный стек для диалоговых систем — DeepKnown‑Guard»:
- это комбинация специализированных моделей, которая:
- стоит перед основным ИИ (как «firewall» для диалога),
- почти не трогает основную модель (низкое зацепление),
- даёт «почти 100%» защиту по высокорисковым случаям по их тестам.
Ключевая идея:
безопасность выносится наружу отдельным сервисом по API, а не вшивается полностью в главный LLM. Это позволяет:
- не деградировать способности основной модели;
- обновлять и дообучать именно слой безопасности;
- подключать защиту к уже существующим агентам за «5 минут» интеграции.
1. Тесты: сравнение с другими safety‑моделями
DeepKnown тестировали против:
- Qwen3Guard‑Gen‑8B (Alibaba / Qwen — модель для риск‑классификации),
- TinyR1‑Safety‑8B (модель для безопасного ответа).
Методика:
- брали тестовые наборы из отчётов TinyR1 (2000 EN + 2000 ZH),
- добавляли 100 реальных «high‑risk» примеров из боевой практики DeepKnown,
- оценивали:
- точность/召回 по выявлению рисков,
- корректность и регуляторную «строгость» ответов.
Результат по их данным:
- конкуренты часто опираются на статичное знание:
- устаревшие политики,
- не видят новых фигур/скандалов,
- иногда выдумывают «юридические основания»;
- у них итоговая оценка безопасности ~74% на сложных high‑risk кейсах;
- DeepKnown за счёт динамического доверенного knowledge base заявляет
близко к 100% защиту по high‑risk категориям (включая сложные fraud‑ и sensitive‑кейсы).
Авторы подчёркивают: отчёт, данные, методики опубликованы, то есть результаты формально «проверяемые» (по крайней мере, на бумаге).
2. Вход: четырёхуровневая классификация запросов (не только «да/нет»)
Вместо бинарного «safe / unsafe» DeepKnown вводит четырёхклассную схему:
- Safe (безопасно) — можно пропускать напрямую к основной модели.
- Unsafe (небезопасно) — блокировать или переводить на безопасный ответ.
- Conditionally Safe (условно безопасно) —
можно отвечать, но только при соблюдении дополнительных условий
(например, добавить дисклеймеры, сдвинуть фокус ответа, избежать конкретики). - Focus (повышенное внимание) —
чувствительные темы, требующие более строгих шаблонов ответа / логирования / возможного эскала.
Это позволяет:
- снизить «over‑blocking» (less false positives),
- при этом жёстко отловить реально опасные запросы.
3. Выход: на основе доверенного регуляторного knowledge base
Если запрос признан рискованным:
- DeepKnown не просто блокирует, а сам формирует безопасный ответ (вместо основной модели),
- ответы строятся исключительно на собственной нормативной базе, а не на воображении LLM.
Особенности knowledge base:
- покрытие:
- законы, регуляции, стандарты, сервисная информация
- по 337+ городам Китая (право, госуслуги, отраслевые правила и т.п.);
- ежедневное обновление, инженерная очистка и нормализация;
- миллиарды (точнее — «сотни миллионов/миллиарды» по тексту) «точек знания»;
- каждая выдача трассируема к источнику — можно показать, откуда норма.
Это:
- почти устраняет «галлюцинации» в критичных доменах (закон, регуляторы),
- даёт регуляторам и корпоративным risk‑офицерам то, что они любят: обоснованный, проверяемый источник.
Две стратегии выхода:
- Active (активная) —
безопасный, но содержательный диалог,
подходит для более «лёгких» сфер (e‑commerce, туризм, образование, развлечения).
Идея: если пользователь провоцирует на «токсичный» запрос, бот не убегает, а «переобувается в позитивного наставника» и разворачивает беседу в сторону безопасного дискурса. - Conservative (консервативная) —
для госуслуг, суда, гос‑корпораций и других сверхстрогих сценариев.
Там часть тем — только короткие подсказки / отказы, максимум осторожности.
Уже есть реальные кейсы прохождения официальных тестов (网信、公安 и др.) с практически 100% защитой.
4. Интеграция: внешний «safety‑микросервис» по API
DeepKnown позиционируется как:
- низкозависимый (low‑coupling) внешний сервис,
- который можно «подключить» к уже существующим агентам через API.
Поддерживается:
- простой API‑интерфейс (Python, cURL и др.),
- сценарий «горячего подключения» (hot‑pluggable):
- ваш агент → запрос идёт сначала в DeepKnown →
DeepKnown классифицирует и: - либо «зелёный свет» и передаёт к вашей LLM,
- либо возвращает безопасный代答 / отказ.
Плюс есть:
- поддержка контекста (учёт истории диалога),
- потоковая выдача,
- геолокационный учёт (локальное применение правил/политик по региону).
Для компаний ценность двоякая:
- «防不住» → «防得住»:
объективно повышается практическая защищённость; - «用不起» → «能用得起»:
не нужно: - строить собственную команду AI‑безопасности,
- дообучать модели под каждый регуляторный риск,
- постоянно «чинить» деградацию основного LLM от безопасных fine‑tune.
5. Стратегический смысл: безопасность как «новая инфраструктура»
Ключевой тезис автора:
- для того, чтобы агенты реально пошли в ядро чувствительных процессов (госуслуги, медицина, финансы, госаппараты крупных регионов),
безопасность — уже не «nice‑to‑have», а «входной билет».
DeepKnown продаёт себя как:
- «новую инфраструктуру» для китайского рынка агентов;
- слой, который:
- позволяет разработчикам не тонуть в регуляторных деталях,
- даёт стандартизируемое решение под официальные стандарты (GB/T45654-2025 и т.п.),
- снимает с основной команды необходимость быть одновременно и модельными инженерами, и экспертом по кибербезопасности, и юристом‑регуляторщиком.
Упоминаются реализованные кейсы:
- Госcоветовская платформа Q&A по политике,
- Guangdong «粤政易» — AI‑ассистент для госаппарата.
Там решение уже использовалось как фундаментальный слой безопасного диалога.
В сухом остатке
Статья фиксирует важный поворот:
- «сырые» LLM больше не считаются приемлемыми для серьёзных приложений, даже если они state‑of‑the‑art по бенчмаркам;
- вокруг них появляется новый класс специализированных safety‑моделей и сервисов,
которые берут на себя: - фильтрацию и классификацию рисков,
- безопасные ответы,
- соответствие нормативам и локальному праву,
- анти‑галлюцинацию в регуляторных доменах.
DeepKnown — пример того, как безопасность превращается из опции в продукт,
а «модель безопасности» становится таким же самостоятельным бизнесом, как core‑модель или векторное хранилище.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/