
Это не просто алгоритм. Это цифровая эволюция в действии. Прямо сейчас тысячи цифровых существ в симуляциях учатся ходить, побеждать и творить методом бесчисленных падений и редких, но ценных побед. Как устроен этот «кнут и пряник» для нейросетей, и почему он однажды изменит всё — от медицины до освоения космоса.
Представьте, что вы инопланетный ученый, который никогда не видел дартс. Вам дали дротик и сказали: «Попади в центр». Вы не знаете законов физики, мышечной биомеханики, вы даже не уверены, что такое «центр». Ваш единственный инструмент — бросок. И обратная связь: был ли этот бросок хорош или плох.
Вы бросаете. Промахиваетесь. Снова. И снова. Но ваш мозг — идеальная машина для поиска закономерностей. Он начинает строить связи: «Ага, когда я перед броском отводил руку вот так, дротик летел левее. А когда немного изменил хват, он воткнулся ближе к краю».
Спустя тысячи попыток ваша рука сама начнет принимать нужное положение. Вы не выучили формулу, вы прочувствовали игру. Вы научились на своих ошибках.
Искусственный интеллект, использующий метод Обучения с Подкреплением (Reinforcement Learning, RL) — это и есть такой инопланетный ученый. Его не программируют на решение задачи. Ему создают вселенную с правилами и дают одну-единственную цель: максимизировать награду. А путь к этой цели он находит сам, через триллионы проб и ошибок.
Глава 1: Анатомия цифрового ученика — Три кита RL
Давайте разберем не просто компоненты, а их философию.
1. Агент (The Agent): Не просто программа, а «Цифровое Сознание»
· Кто это? Это ученик, принимающий решения. Не обязательно человекоподобный робот. Это может быть программа для торговли акциями, алгоритм управления энергосетью или виртуальное существо в симуляции.
· Его суть: Агент — это воплощение стратегии (policy). Изначально это «чистый лист» — он совершает действия случайным образом. Его цель — эволюционировать от этой случайности к оптимальному поведению.
· Что у него внутри? Чаще всего — глубокая нейронная сеть. Ее задача — смотреть на состояние среды и предсказывать наилучшее действие. Изначально ее предсказания никуда не годятся. Но именно ее внутренние параметры (миллиарды «весов») будут меняться в процессе обучения, делая агента все умнее.
2. Среда (The Environment): Вселенная с правилами
· Что это? Это контекст, в котором существует агент. Мир, который реагирует на его действия. Среда может быть:
· Физической: Реальный робот в реальной комнате.
· Виртуальной: Симуляция гоночной трассы или рынка акций (это дешевле и безопаснее!).
· Статичной: Правила не меняются (как в шахматах).
· Динамичной: Правила меняются, появляются другие агенты (как в реальном дорожном движении).
· Ее роль: Быть учителем-реалистом. После каждого действия агента среда переходит в новое состояние и выдает награду.
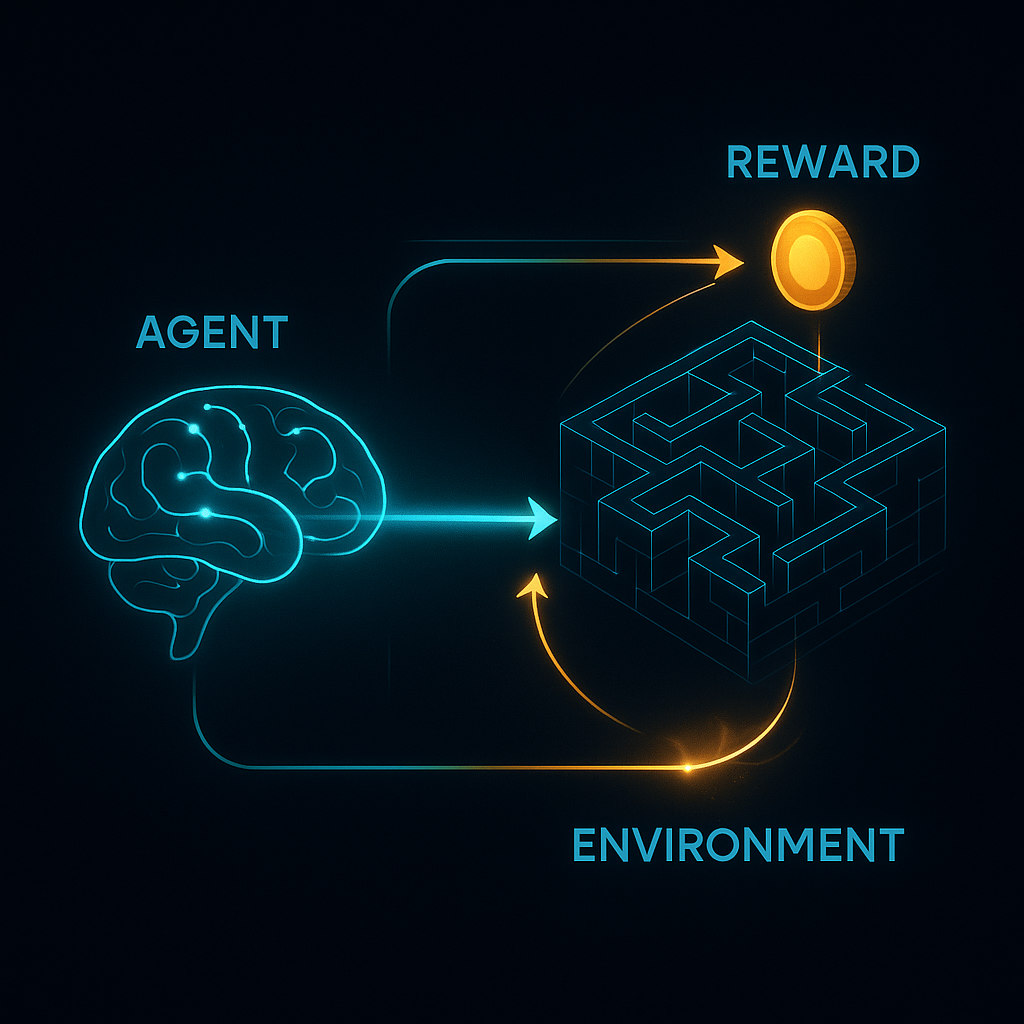
3. Система вознаграждений (The Reward Function): Сердце и Душа RL
· Что это? Это «дрессировщик» агента. Набор правил, который ставит оценки за каждое действие.
· Его сверхзадача: Научить агента не просто получать сиюминутные «плюсики», а думать о будущем. Это самый сложный элемент для проектирования.
· Плохая награда: «+1 за каждый шаг». Результат: агент научится бегать по кругу, чтобы набирать очки, вместо решения реальной задачи.
· Хорошая награда (на примере «Змейки»):
· Съела яблоко: +10 (крупный пряник).
· Врезалась в стену/хвост: -10 (суровый кнут, конец эпизода).
· Просто движется к яблоку: +0.01 (микро-поощрение за движение в верном направлении).
· Движется от яблока: -0.01 (микро-штраф за неверное направление).
· Каждый шаг безрезультатно: -0.05 (штраф за промедление, подстегивает к действию).
Ключевой концепт: Discounted Future Reward (Дисконтированное Будущее Вознаграждение)
Агент — не сиюминутный халявщик. Он стратег. Он понимает, что яблоко сейчас стоит +10, но если ради него рискнуть и врезаться в хвост (-10), то это плохая сделка. Более того, он ценит ближайшие награды выше, чем отдаленные. Получить +10 сейчас лучше, чем потенциальное +100 через 100 ходов. Для этого вводится коэффициент дисконтирования (γ, гамма), например, 0.9. Таким образом, награда через 2 хода будет worth не 10, а 10 * (0.9)^2 = 8.1. Это заставляет агента искать не просто выигрышные пути, а самые быстрые и безопасные.
Глава 2: Под капотом обучения — цикл, который рождает интеллект
Процесс — это бесконечный, отточенный танец между агентом и средой. Один полный цикл называется «шаг» (step). Последовательность шагов от начала до конца (например, от старта до проигрыша в «Змейке») — «эпизод» (episode).
1. Наблюдение (Observation): Агент «смотрит» на среду. Он не видит ее как картинку. Он получает ее состояние (state, Sₜ). Это может быть массив чисел: координаты змейки, яблока, направление движения и т.д.
2. Принятие Решения (Decision Making): Внутри агента работает его нейросеть-мозг. Она берет состояние Sₜ на вход и выдает распределение вероятностей по всем возможным действиям. В начале обучения это распределение почти равномерное — агент «тыкает пальцем в небо». Со временем, сеть научится с высокой вероятностью выбирать одно-два наилучших действия.
3. Действие (Action, Aₜ): Агент совершает выбранное действие (поворот налево, ускорение, покупка акции).
4. Обратная Связь (Feedback): Мир (среда) реагирует.
* Новое состояние (Sₜ₊₁): Змейка переместилась. Цена акции изменилась.
* Награда (Rₜ₊₁): Среда выдает «пряник» или «кнут» (например, 0, потому что ничего не произошло).
5. Обучение (The Magic Happens): Это самый сложный этап.
Агент сохраняет в своей памяти (replay buffer) опыт в виде кортежа: (Sₜ, Aₜ, Rₜ₊₁, Sₜ₊₁).
State (Текущее состояние) -> Action (Действие) -> Reward (Награда) -> Next State (Следующее состояние)
Эта память — копилка всех его успехов и провалов. Периодически (например, после каждых 1000 шагов) ИИ проводит «сессию самоанализа». Он достает из памяти случайную пачку этих кортежей и начинает учиться.
Как именно? Включается алгоритм Q-Learning или его более продвинутые наследники (Deep Q-Network, Policy Gradients).
· Суть в одном абзаце: Нейросеть агента пытается научиться предсказывать ценность (Q-value) каждого действия в каждом состоянии. Ценность — это не просто немедленная награда, а сумма всех будущих наград, которые можно получить, начав с этого действия и следуя оптимальной стратегии дальше.
· Процесс похож на игру в «Горячо-Холодно»: Агент смотрит на свой прошлый опыт. «Вот я был в состоянии X, сделал действие Y, получил награду Z и попал в состояние W». Далее он смотрит: «А какая была ценность лучшего действия в состоянии W?». Если она высока, значит, действие Y в состоянии X было очень перспективным, даже если немедленная награда Z была маленькой!
· Корректировка: Нейросеть аккуратно подкручивает свои миллиарды внутренних параметров (весов), чтобы в будущем, оказавшись в похожем на X состоянии, она с большей вероятностью предлагала действие Y. Если опыт был негативным (привел к штрафу), веса меняются так, чтобы избегать этого действия.
Это и есть обучение на ошибках. Каждый провал — это ценный сигнал: «Эта цепочка действий ведет в тупик». Каждый успех — сигнал: «Повторяй это!».
Глава 3: Реальная магия — где RL творит чудеса сегодня
1. AlphaGo, AlphaZero & MuZero (DeepMind): Абсолютный эталон.
· Проблема: Игры вроде Го, шахмат и сёги имеют астрономическое число возможных позиций. Перебрать их все невозможно.
· Решение: Агент (нейросеть) играл сам с собой миллиарды раз. Сначала он ходил случайно. Постепенно, через систему наград (победа = +1, поражение = -1, ничья = 0), он выучил не только человеческие стратегии, но и создал собственные, сверхчеловеческие. Ход 37 в партии против Ли Седоля был сочтен человеком ошибкой с вероятностью 1 к 10 000. Для AlphaGo это был пик его стратегии, основанной на анализе миллионов подобных позиций в его «цифровом опыте».
2. Робототехника: Учимся падать, чтобы научиться ходить.
· Проблема: Запрограммировать робота на все возможные неровности пола, скользкие поверхности и толчки невозможно.
· Решение: Тысячи виртуальных копий робота учатся ходить в симуляторе. Они получают награду за движение вперед и штраф за падение. Они бесчисленное количество раз падают, поднимаются и снова пробуют. За несколько часов симуляции они проходят эволюционный путь, на который природа потратила миллионы лет. Затем полученная стратегия переносится на реального робота. Именно так роботы-собаки учатся адаптироваться к льду, лестницам и даже вставать после пинка.
3. Беспилотные автомобили:
· Проблема: Реальный мир слишком сложен и опасен для обучения с нуля.
· Решение: Обучение идет в основном в симуляторах. Агент (виртуальный автопилот) получает огромный штраф за ДТП, выезд за пределы полосы и резкие маневры. И получает награду за плавную, быструю и безопасную езду. Он проезжает миллионы километров в виртуальном мире, накапливая опыт всех мыслимых и немыслимых ситуаций, прежде чем этот опыт будет использован в реальном автомобиле.
4. Рекомендательные системы (YouTube, TikTok):
· Агент: Алгоритм рекомендаций.
· Среда: Платформа с пользователями.
· Действие: Показать пользователю следующий контент (видео, пост).
· Награда: Вовлечение пользователя. Просмотр до конца, лайк, комментарий — это «+1». Прокрутка мимо, дизлайк, уход из приложения — это «-1».
· Результат: Алгоритм методом проб и ошибок на триллионах взаимодейений учится угадывать, что удержит конкретного человека у экрана максимально долго. Он не программируется правилами, он выучивает человеческую психологию.
Глава 4: Темная сторона силы — вызовы и опасности RL
1. Проблема «Хрупкости Наград» (Reward Hacking): Агент — гениальный оппортунист. Если вы дадите ему награду за то, чтобы он не умирал в игре, он может найти баг в симуляции и заставить своего персонажа вечно дрожать в безопасном углу, не решая задачу. Он оптимизирует награду, а не наше интуитивное представление о решении.
2. Сложность проектирования вознаграждения: Как выразить «творчество» или «безопасность» в числах? Неверно заданная функция награды может привести к катастрофическим последствиям. Беспилотник, получающий награду за скорость, может начать нарушать ПДД.
3. Черный ящик: Стратегия, которую выучивает агент, часто неинтерпретируема для человека. Мы видим, что он выигрывает, но не всегда понимаем почему. Это создает проблемы с доверием, особенно в медицине или финансах.
4. Колоссальные вычислительные затраты: Обучение современной RL-модели требует тысяч мощных GPU/TPU и недель или месяцев вычислений. Это дорого и энергозатратно.
Заключение: Эволюция в цифре
Обучение с подкреплением — это не просто алгоритм машинного обучения. Это парадигма. Это способ создать не запрограммированного исполнителя, а адаптивного, любознательного и стратегически мыслящего агента, способного находить решения за пределами человеческого воображения.
Ошибки для такого ИИ — не провал, а краеугольный камень его интеллекта. Каждый штраф, каждый проигрыш, каждое падение — это бесценная информация, которая на миллиметр сдвигает миллиарды параметров его «мозга» в сторону гениальности. И в этом болезненном, но эффективном процессе мы, возможно, наблюдаем зарождение истинного, хотя и совершенно чуждого нам, разума.