Каждый день мучаетесь с тьмой файлов — от простых заметок до гигантских логов? Легко запутаться в этом хаосе. Но стоит использовать Python — и работа с файлами становится элементарной! Всего пара строк кода — и вы экономите и время, и нервы. Давайте разберёмся, как Python может раз и навсегда избавить вас от «файловой головной боли».
Как читать текстовые файлы
Если имеете дело с логами, конфигами или большими текстовыми данными, самое первое — научиться быстро и удобно просматривать содержимое. Python делает это проще простого: достаточно встроенной open() и нескольких полезных методов. Самый удобный и безопасный способ — использовать конструкцию с with: она сама позаботится о файле.
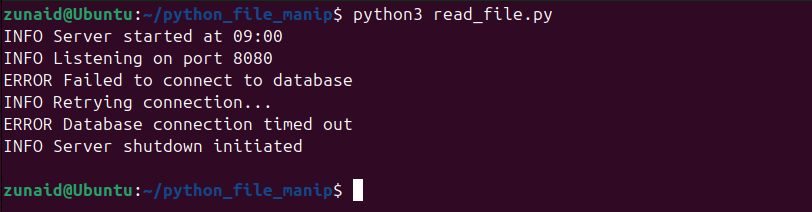
Всё содержимое файла — в одной строке кода! Такой способ отлично подойдёт для небольших и средних файлов. with сам закроет файл — никакой головной боли.
Хотите читать файл по строкам? Вот так — по шагам, без лишних заморочек:
Также в Python есть удобные методы readline() и readlines() — используйте их, если нужна гибкость.
readline() удобно использовать, если, например, нужно вытащить первые десять строк или добраться до определённой, например, lines[5]. readlines() сразу отдаёт список всех строк — удобно, если планируете массово что-то менять, индексировать или обрабатывать.
Как создавать и менять текстовые файлы
Любой, кто пишет на Python, быстро сталкивается с задачей — что-то сохранить или обновить в файле: отчёты, очищенные данные, логи и многое другое. Всё проще, чем кажется — смотрите:
Открытие файла с опцией "w" создаёт новый файл или полностью перезаписывает существующий. Удобно, если нужен свежий результат — например, формировать новый отчёт каждый день. Если нужно добавить данные в конец файла, используйте режим "a".
Такой способ добавляет свежие данные, не трогая старое содержимое. Если нужно сразу записать много строк, используйте writelines().
Никаких циклов: передаёте список строк в writelines() — и готово. Только не забудьте добавить символ переноса строки
в каждую строку, иначе текст слипнется.
Как я анализирую и визуализирую данные с помощью Python и Seaborn
Не зря Python считается королём работы с данными. Хотите быстро и наглядно визуализировать ваши графики? Обратите внимание на библиотеку Seaborn — она дружелюбна и выдаёт крутые картинки с первых минут.
Почему я выбрал Seaborn
Как найти нужное в текстовых файлах
Чтение и запись освоили? Следующий шаг — умение находить в файле нужную строку или шаблон. Например, искать ошибки в логах или конкретные значения. Python это делает элементарно, а с регулярками — вообще решает задачи любой сложности. Простой пример с циклом:
Ищете конкретное слово? Это на одну строку, буквально! А если формат сложнее — например, искать ID или временные метки — используйте модуль re:
Такой вариант незаменим, если нужно ловить строки с нужным ID пользователя или со строго определённой структурой.
Замена текста прямо в файлах: быстро и без боли
Если поиск освоен, то следующий шаг — автоматическая замена нужных данных. Python всё упростил до предела: хотите «найти и заменить» — используйте стандартные методы для строк:
Так легко убрать повторяющееся слово по всему файлу. Нужна замена по сложному шаблону? Нет ничего проще с регулярными выражениями:
Regex — спасение, если нужно менять не одно слово, а совпадения по определённой схеме.
7 идей для использования random в Python
Хотите немного хаоса в код? random — идеальный способ добавить случайность: от генерации чисел до перемешивания списков. Каждый Python-разработчик обязан знать этот маленький, но мощный инструмент. Давайте смотреть, как это работает!
Подключаем random в Python
Быстрая статистика по файлу: строки, слова, буквы — контроль за пару минут
Нужно узнать, сколько в файле строк, какие слова встречаются чаще всего, или подсчитать общее число символов? Python справится за секунды. Это отлично для анализа текста, подготовки отчётов или обработки больших массивов данных. Всё просто — обычный цикл решает задачу.
Перебирайте строки одну за одной — и легко считайте что угодно, даже если файл огромный. Чтобы посчитать слова:
Метод .split() разбивает каждую строку на слова, и дальше можно делать любые подсчёты и фильтры.
Если задача посложнее — подключайте модуль collections:
Хотите знать топ-10 самых частых слов? Counter сам всё подсчитает и отсортирует, а .most_common() покажет результат по убыванию.
Разделить или склеить? Легко работаем с большими файлами
Огромные текстовые файлы не всегда удобно обрабатывать целиком. Иногда надо разбить их на части, а порой — соединить кучу кусочков в один большой файл. И тут Python тоже выручает!
Для деления файла на части по определённому количеству строк — никаких сложностей, достаточно простого цикла. Нужно собрать десятки файлов в один? На помощь придёт модуль glob:
glob находит в папке logs/ все нужные файлы по шаблону, а дальше — их содержимое автоматически объединяется за секунды. Очень удобно для недельных логов, итоговых отчётов или склеивания частей экспортов.
Зная эти трюки, можно забыть о рутине: объединяйте логи за месяц, разбивайте гигантские файлы, готовьте данные для анализа прямо на лету — никаких ограничений!
Модуль math в Python: быстрые вычисления на каждый день
Говорят, Python сам по себе как калькулятор. А если подключить модуль math — возможностей становится море: почти все функции научного калькулятора здесь и даже больше, да ещё и использовать проще.
Константы
Безопасная работа с файлами: перехват ошибок и защита от сбоев
В жизни с файлами не всё так гладко: может не оказаться нужного файла, не хватить прав или произойти сбой — и ваши данные пропадут. Потому всегда применяйте try/except: любые ошибки перехватите вовремя.
Такой подход позволит спокойно реагировать на любые проблемы — будь то отсутствие файла или доступа, ничего не сломается. И важно: заранее заботьтесь о кодировках. Если с файлами работали в разных системах, всегда учитывайте возможные различия.
Умная обработка кодировок спасёт ваши файлы при работе с разными компьютерами или системами.
Как использовать модуль statistics в Python
Для серьёзной статистики в Python есть мощные библиотеки, но для быстрых расчётов прекрасно подойдёт модуль statistics — никаких скучных формул и лишних заморочек, только результат.
Зачем нужен модуль statistics?
Теперь вы знаете самые востребованные приёмы работы с файлами в Python. Хотите узнать ещё больше? Изучите модуль os и поэкспериментируйте с функцией open() — там ещё много скрытых фишек, которые сэкономят вам массу времени.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru