Разработчики использовали агентов (другие ИИ), чтобы тренировать Grok быть приятным собеседником. Это дало плоды в тестах на эмпатию (EQ-Bench) и креативное письмо. xAI перешли от гонки «кто лучше решит интеграл» к гонке «кто лучше поймет человека». Grok 4.1 позиционируется не просто как калькулятор, а как компаньон с характером, который при этом перестал выдумывать факты на ходу.
🔥 Главное (TL;DR):
- Абсолютный лидер рейтингов: Grok 4.1 занял первое место на LMArena, обогнав Claude Sonnet 4.5, GPT-5 Preview и Gemini 2.5.
- Две версии: Grok 4.1 Thinking — думающая модель, топ-1 в мире.
Grok 4.1 — быстрая версия без режима «размышлений». Самое смешное, что даже эта «быстрая» версия занимает 2-е место в общем зачете, обходя топовые «думающие» модели конкурентов. - Эмоциональный интеллект: Модель училась не только на фактах, но и на стиле общения. Она лучше считывает полутона, сарказм и эмоциональное состояние пользователя.
🧠 "Мягкие навыки" — киллер-фича
Разработчики использовали агентов (другие ИИ), чтобы тренировать Grok быть приятным собеседником. Это дало плоды в тестах на эмпатию (EQ-Bench) и креативное письмо.
📊 Сухие цифры и факты
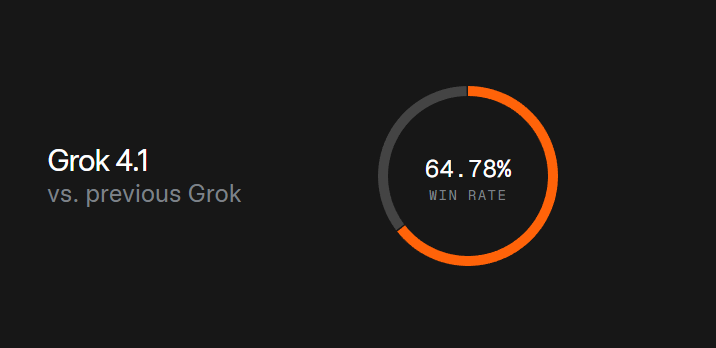
- Слепые тесты: В период "тихого запуска" (1-14 ноября) люди выбирали ответы Grok 4.1 в 64.78% случаев по сравнению с прошлой версией.
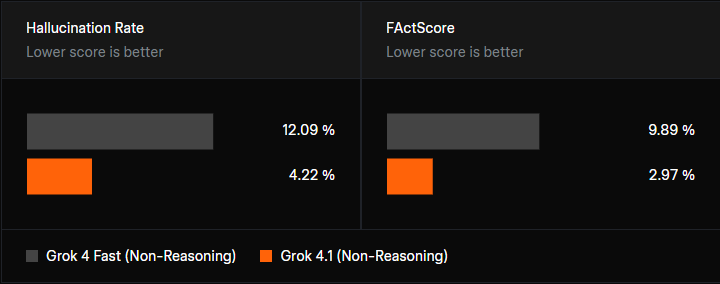
- Меньше галлюцинаций: В новой версии удалось радикально снизить количество выдуманных фактов. В быстрых ответах уровень ошибок упал с ~12% до ~4%.
- LMArena Elo: У Grok 4.1 — 1483 балла. Ближайший конкурент (не от xAI) отстает на 31 балл, что в мире больших языковых моделей — пропасть.
🧐 Суть обновления
xAI перешли от гонки «кто лучше решит интеграл» к гонке «кто лучше поймет человека». Grok 4.1 позиционируется не просто как калькулятор, а как компаньон с характером, который при этом перестал выдумывать факты на ходу.