Синтез речи (англ. speech synthesis) — это искусственное воспроизведение человеческой речи. Компьютерная система, предназначенная для этого, называется синтезатором речи и может быть реализована как в программном, так и в аппаратном виде. Система преобразования текста в речь (англ. text-to-speech, TTS) переводит обычный текст на человеческом языке в речь; существуют также системы, преобразующие символическое лингвистическое представление, например фонетическую транскрипцию, в речь[1]. Обратный процесс называется распознаванием речи.
Синтезированная речь может создаваться путём конкатенации фрагментов записанной речи, хранящихся в базе данных. Системы различаются по размеру хранимых единиц: система, сохраняющая фонемы или дифоны, имеет наибольший диапазон вывода, но её речь может быть менее разборчивой. Для специализированных областей применения возможен синтез целых слов или предложений, что позволяет достичь высокого качества. Либо синтезатор может моделировать голосовой тракт и другие особенности человеческого голоса, полностью формируя «синтетическую» речь[2].
Качество синтезатора речи определяется его сходством с человеческим голосом и разборчивостью. Хороший синтезатор текста в речь помогает людям с нарушениями зрения или затруднениями при чтении прослушивать письменные тексты. Первый синтезатор речи в операционной системе появился в 1974 году в UNIX через утилиту speak[3]. В 2000 году синтезатор Microsoft Sam был основной голосовой системой функции экранного диктора в Windows 2000 и последующих версиях Windows XP.
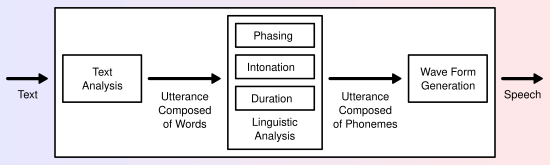
Общая схема работы типовой TTS-системы
Система преобразования текста в речь (или «движок») обычно состоит из двух частей:[4] фронтенда (передней части) и бэкенда (задней части). Фронтенд преобразует исходный текст, содержащий числа и аббревиатуры, в слова; этот этап называется нормализацией текста, предобработкой или токенизацией. Затем фронтенд назначает каждому слову фонетическую транскрипцию и разбивает текст на просодические единицы (фразы, клаузы, предложения). Преобразование слов в фонемы называется text-to-phoneme или grapheme-to-phoneme conversion. Итоговое символическое лингвистическое представление формируется на выходе фронтенда и поступает на бэкенд, который преобразует это представление в звук. Иногда вычисление целевой просодии (тональная кривая, длительности фонем) также входит в этот этап[5].
История
Ещё до появления электронной обработки сигналов предпринимались попытки создания машин, имитирующих человеческую речь[6]. Известны и легенды о «медных головах», способных говорить, например, связанных с Папой Сильвестр II (ум. 1003), Альбертом Великим (1198–1280) и Роджером Бэконом (1214–1294)[7].
В 1779 году немецко-датский учёный Кристиан Готлиб Кратценштейн стал лауреатом конкурса Российской императорской академии наук и художеств, создав модели голосового тракта, воспроизводившие пять долгих гласных (в МФА: [aː], [eː], [iː], [oː], [uː])[8]. За этим последовала ручная акустико-механическая "говорящая машина" Кемпелена (1791)[9], в которой моделировались язык и губы — позволив получать не только гласные, но и согласные. В 1837 году Чарльз Уитстон создал собственную говорящую машину, а в 1846 Джозеф Фабер продемонстрировал Euphonia. В 1923 году Пажет вновь воспроизвел устройство Уитстона[10].
В 1930-е годы в Bell Labs был сконструирован первый вокодер, позволяющий автоматически анализировать речь. На основе работы с вокодером Хомер Дадли разработал синтезатор "The Voder", показанный на Всемирной выставке в Нью-Йорке в 1939 году.
Доктор Франклин С. Купер и коллеги в Haskins Laboratories в конце 1940-х посторили устройство Pattern playback, превращавшее спектрограммы звуковых паттернов речи обратно в реальное звучание. С этим аппаратом Алвин Либерман и команда открыли акустические признаки фонетических сегментов речи.
Электронные устройства

Компьютер и корпус синтезатора речи, использовавшийся Стивеном Хокингом, 1999 год
Первые компьютерные системы синтеза речи появились в конце 1950-х. В 1968 году Норико Умеда и др. разработали первую англоязычную систему "текст в речь" в Японии[11]. В 1961 году физик Джон Ларри Келли-младший и Луи Герстманн использовали компьютер IBM 704 для синтеза речи, воспроизведя песню «Daisy Bell» (с музыкальным сопровождением Макса Мэтьюза). Эту сцену вдохновлённо перенял Артур Кларк для фильма Космическая одиссея 2001 года, где HAL 9000 поёт тот же самый мотив[12]. Несмотря на успехи в чисто электронном синтезе, исследования механических устройств продолжались[13].
Линейное предсказание речи (LPC), один из методов кодирования речи, начал разрабатываться Фумитадой Итакурой и Сюдзо Саито (NTT) в 1966 году, а позднее — Бишну Аталом и Манфредом Шрёдером в Bell Labs[14]. LPC легло в основу ранних чипов синтеза речи, например, используемых в игрушках Texas Instruments Speak & Spell с 1978 года.
В 1975 году Итакура разработал метод линейные спектральные пары (LSP) для высококомпрессионного кодирования речи, а его команда создала чип синтеза речи на этой основе, ставший стандартом в международных системах связи и мобильной телефонии[15].
В 1975 году был выпущен один из первых специализированных комплексов синтеза речи MUSA, способный читать итальянский текст и даже петь «а капелла»[16].
С появлением портативных устройств c синтезом речи в 1970-х одной из первых была создана калькулятор для слепых TSI Speech+ (1976), а также серия игрушек Speak & Spell (1978), электронный шахматный компьютер с озвучкой (1979). Первой видеоигрой с синтезом речи была Stratovox (1980), а первой компьютерной игрой — Manbiki Shoujo на PET 2001[18].
В 1976 году был создан CT-1 Speech Synthesizer для микрокомпьютеров S-100[19]. До 1990-х синтезированные голоса были преимущественно мужскими, пока в AT&T Bell Laboratories не была создана женская модель (А. Сирдал)[20].
С 2000-х с каждым годом синтезаторы становятся дешевле и доступнее широкой аудитории[21].
Искусственный интеллект
В 2016 году компания DeepMind представила WaveNet, продемонстрировавший возможности глубоких нейросетей в моделировании речевых сигналов и формировании речи на основе спектрограмм, что положило начало синтезу речи на основе нейросетей[22]. В 2018 году Google AI представила Tacotron 2, использующую нейросетевые архитектуры с механизмом внимания для преобразования текста в спектрограммы и далее в речь с помощью нейровокодера. В 2019 году Microsoft Research выпустила FastSpeech, а в 2020 — Glow-TTS с поддержкой передачи эмоциональных и стилистических особенностей голоса. В 2021–2024 годах платформа 15.ai позволила на практике клонровать голоса вымышленных персонажей по крайне малым объёмам данных (<15 секунд записи), что послужило толчком к взрывному росту мемов-интернет контента с ИИ-голосами[23]. В 2023 году ElevenLabs представила веб-платформу для синтеза, различающего эмоции[24]. В 2024 году OpenAI заявила о возможности клонрования голоса по 15-секундному образцу[25].
Технические особенности
Ключевые качества системы синтеза речи — естественность и разборчивость[26]. Естественность — насколько речь похожа на человеческую, разборчивость — насколько легко её понять. Идеальная система должна обеспечивать оба показателя.
Существует два основных подхода к синтезу речевого сигнала: конкатенативный синтез и формантный синтез. Каждый имеет свои преимущества и недостатки и сфера применения зависит от целей.
Конкатенативный синтез
Конкатенативный синтез основан на соединении заранее записанных сегментов речи. Обычно такой подход позволяет добиться наибольшей естественности, но различия в произношении и автоматизация сегментации могут вызывать артефакты. Существует несколько подтипов: выбор единиц (unit selection), дифонный синтез, доменно-специфический синтез.
Синтез через выбор единиц
Этот подход оперирует большими базами записанной речи, фрагментируя её на фонемы, дифоны, слоги, морфемы, слова, фразы, предложения; затем сегменты индексируются по акустическим параметрам (основная частота, длительность и т.д.), и в момент синтеза выбирается оптимальная последовательность единиц[27]. Данный метод требует чрезвычайно больших объёмов памяти[28].
Дифонный синтез
Использует минимальную базу, включающую все возможные дифоны — пары звуков, характерные для языка (например, для испанского ~800, для немецкого ~2500). На выходе к ним применяется целевая просодия, формируемая средствами цифровой обработки сигналов (LPC, PSOLA, MBROLA и др.). Такой синтез менее естественен и всё чаще уступает дорогим вариантам или исследовательским задачам.
Доменно-специфический синтез
Использование заранее записанных фраз и предложений для ограниченных задач (например, автоматические объявления в транспорте, прогноз погоды). Очень проста по реализации, обеспечивает максимальную естественность звучания там, где разнообразие фраз ограничено.
Формантный синтез
При формантном синтезе не используются сэмплы речи; сигнал создаётся путём аддитивного синтеза по акустической модели (физическое моделирование голосового тракта). Такой подход даёт искусственное звучание, но обеспечивает разборчивость даже на высоких скоростях, устойчив и компактен (важно для встраиваемых систем)[29].
Артикуляционный синтез
Осуществляет моделирование процессов и органов человеческого речевого аппарата (голосовой тракт и т.д.), впервые реализован экспериментально в 1970-х в Haskins Laboratories. Современные системы могут имитировать биомеханику и аэродинамику голосовых связок, бронхов, ротовой и носовой полости[30].
HMM-синтез
Метод основан на скрытых марковских моделях, моделирующих одновременно спектр частот (голосовой тракт), основную частоту и длительность просодии речи. Волновые формы генерируются непосредственно на их основе по критерию максимального правдоподобия[31].
Синтез на основе чистых тонов
Способ, при котором форманты заменяются на чистые тоны ("свисты")[32].
Глубокие нейросети
0:06
Речь, синтезированная нейросетевым вокодером HiFi-GAN
Синтез на основе глубокого обучения использует глубокие нейросети для генерации речи по тексту (text-to-speech) или спектру (вокодер). Требует больших объёмов данных для обучения.
Аудио-дипфейки
В 2023 году зафиксированы случаи, когда синтезированные голоса с помощью ElevenLabs позволяли обходить биометрическую аутентификацию (аудио дипфейки)[33].
Проблемы и ограничения
Нормализация текста
Процесс нормализации текста для синтеза речи сложен: требуется учитывать омографы, числа, аббревиатуры и особенности языка. Например, "project" читается по-разному в фразах "my project" и "to project". Также нелегко определять, как читать числа или сокращения, поскольку в контексте их интерпретация меняется[34].
Преобразование текста в фонемы
Существуют два основных подхода: словарный (по базе слов с озвученной транскрипцией) и правиловый (по набору орфографических правил языка). Первый — быстрый и точный, но не универсальный; второй — применим ко всему, но требует сложных правил для исключений. Обычно комбинируются оба способа.
Оценка качества синтеза
Отсутствие единых объективных критериев оценки систем синтеза речи долгое время усложняло сравнение технологий; с 2005 года для разных систем стали использовать общие контрольные наборы данных[35].
Просодика и эмоции
Исследования показывают, что слушатели распознают эмоции (например, улыбку) по интонационным особенностям синтезированной речи[36]. Но автоматизация передачи эмоций остаётся сложной задачей.