
Надежность — это не цель, а управляемый риск
В наши дни, когда каждая компания становится технологической, главный конфликт происходит на границе между скоростью разработки новых функций (velocity) и стабильностью сервисов. Продакт-менеджеры требуют релиза «еще вчера», а инженеры-операционисты с ужасом ждут ночных сообщений.
Site Reliability Engineering (SRE), методология, разработанная в Google, предлагает решение: перестать стремиться к нереалистичной цели 100% доступности и научиться управлять риском. Для SRE надежность — это не абстрактное пожелание, а конкретная, измеримая величина, выраженная в деньгах, времени и, самое главное, в четких численных метриках.
SRE переводит операционную работу в инженерную плоскость, позволяя организации сознательно балансировать. Главный принцип в том, что 100% надежности невозможно достичь без колоссальных затрат, которые пользователи, скорее всего, даже не заметят. Наша задача — найти оптимальный уровень ненадёжности, который допустим для бизнеса, и превратить этот допуск в ресурс, которым можно торговать.
Определяющая Триада SRE: SLI, SLO и Бюджет Ошибок
Фундаментом управления надежностью являются три взаимосвязанных концепции:
1. SLI (Service Level Indicator) — Индикатор уровня обслуживания. Это количественная мера, показывающая фактическое состояние сервиса. Примеры: процент успешных запросов или среднее время ответа (задержка).
2. SLO (Service Level Objective) — Цель уровня обслуживания. Это целевое значение, которое устанавливается для SLI. Например: "99.9% запросов должны быть успешными". SLO — это внутренняя цель, основа для работы команды.
3. SLA (Service Level Agreement) — Соглашение об уровне обслуживания. Это контракт, часто юридически обязывающий, между поставщиком и потребителем, включающий финансовые или другие последствия за нарушение SLO.
SRE-подход концентрируется именно на SLO, так как они напрямую определяют, какой уровень отказа допустим.
SLI и золотые сигналы: измерение опыта пользователя
Надежность должна измеряться так, как ее ощущает конечный пользователь. Неправильно выбранный SLI приведет к тому, что система будет «зеленой» по метрикам, но пользователи при этом будут страдать.
SLI: фокус на критическом пути
При выборе SLI важно учитывать нюансы. Например, при измерении задержки (Latency) необходимо различать задержку успешных запросов и задержку ошибочных запросов (HTTP 500), поскольку ошибочный запрос может быть очень быстрым, но для пользователя он все равно является неудачей.
Для точности SRE используют продвинутые методы, такие как Ratio Metrics (соотношение "хороших" событий к "общему" числу).
Например, используя структурированные метрики (http_request_duration_seconds_bucket), можно задать SLI как "Процент успешных запросов, выполненных менее чем за 500 мс". Это учитывает не только факт успеха, но и скорость, которую пользователь воспринимает как удовлетворительную.
SLO должны быть привязаны к критическим пользовательским путям (CUJ), таким как успешный вход в систему, оформление заказа или загрузка ключевой страницы.
Золотые сигналы мониторинга (The Four Golden Signals)
Для получения целостной картины SRE концентрируется на четырех ключевых показателях, которые получили название "Золотые сигналы" :
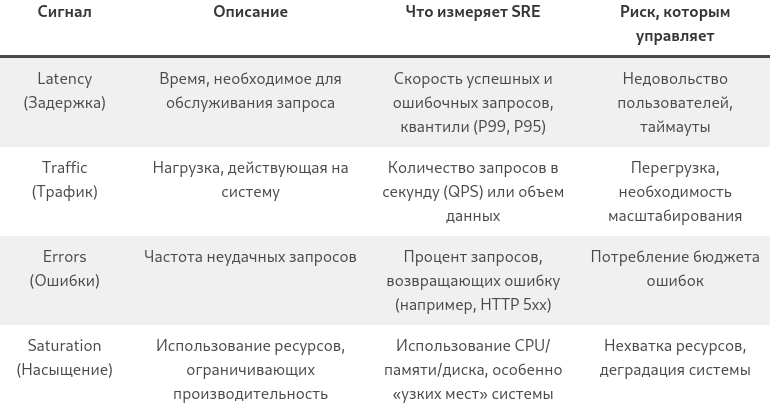
Активное отслеживание этих сигналов позволяет проактивно выявлять проблемы до того, как они нарушат SLO.
Бюджет ошибок: финансовый контролер разработки
Бюджет ошибок (Error Budget) — это тот самый механизм, который переводит цель SLO в конкретный ресурс допустимого риска.
Расчет:
Бюджет ошибок=1−SLO
Если вы установили SLO 99.9% доступности за месяц, ваш бюджет ошибок составляет 0.1%. Если за этот период сервис обрабатывает 1000000 запросов, то команда может допустить 1000 ошибок (неуспешных запросов).
Механизм выравнивания стимулов
Бюджет ошибок устраняет субъективные споры между SRE и разработкой, заменяя их на объективные данные.
- Пока бюджет в плюсе: Команды разработки могут принимать обоснованные риски — увеличивать частоту релизов (push velocity) или внедрять менее протестированные, но критически важные функции.
- Если бюджет исчерпан: Вступает в силу жесткая политика "Заморозки релизов" (Feature Freeze). Команда должна немедленно остановить все изменения, не связанные с исправлением стабильности (кроме критических патчей P0), пока надежность не восстановится в рамках SLO.
Это создает мощную обратную связь: продуктовые команды, не желая, чтобы их работа над функциями была остановлена, сами начинают настаивать на более тщательном тестировании и повышении качества, как только бюджет приближается к нулю. Это вынуждает их платить технический долг, который проявляется в частых сбоях, потребляющих бюджет.
Контроль скорости выгорания (Burn Rate)
Для проактивного управления риском SRE отслеживают не только размер бюджета, но и Скорость выгорания (Burn Rate) — как быстро потребляется допустимый лимит ошибок.
Высокая скорость выгорания (например, когда инцидент потребил более 20% бюджета за короткий срок) — это тревожный сигнал, который требует немедленного постмортема и обязательного P0-действия по устранению корневой причины, даже если бюджет еще не исчерпан полностью.
Обсервабилити: Как SRE видит неизвестное
В сложных микросервисных архитектурах традиционный мониторинг, настроенный на заранее известные пороги, часто бесполезен. SRE полагается на Обсервабилити (наблюдаемость) — способность понимать и объяснять неожиданное поведение системы, агрегируя и анализируя данные в реальном времени.
Обсервабилити дает инженерам возможность задавать системе новые, непредсказуемые вопросы о её состоянии, не требуя переразвертывания кода.
Три столпа обсервабилити
Обсервабилити строится на трех ключевых столпах :
- Метрики (Metrics): Количественные, агрегированные данные (идеальны для дашбордов и алертинга, связанного с SLO).
- Логи (Logs): Детальные записи отдельных событий, служащие подробным аудиторским следом и необходимые для понимания контекста сбоя.
- Трейсы (Traces): Сигналы, отслеживающие сквозной путь одного запроса через все задействованные микросервисы. Помогают быстро найти узкое место и определить зависимость.
Диагностика нарушений SLO
Эффективный SRE-процесс требует, чтобы эти столпы были связаны:
- Алерт: Нарушение SLO активирует предупреждение, основанное на метриках (например, рост числа ошибок).
- Трассировка: Инженер использует трейсы, чтобы изолировать микросервис или сегмент, где произошла задержка или ошибка.
- Корневая причина: Наконец, инженер обращается к детальным логам, привязанным к конкретному идентификатору трассировки (Trace ID), чтобы понять точную ошибку и контекст.
Инвестиции в обсервабилити — это прямая защита Бюджета ошибок, поскольку она напрямую снижает среднее время поиска и устранения проблем (MTTR).
Проактивное управление рисками и цикл обучения
Лучший SRE не тот, кто быстро тушит пожары, а тот, кто не позволяет им разгореться.
Инженерия Хаоса: контролируемое потребление бюджета
Инженерия Хаоса (Chaos Engineering) — это практика контролируемого внедрения сбоев в Production-среду для проверки устойчивости системы.
Это высшая степень управления риском: SRE сознательно потребляет малую часть Бюджета ошибок, чтобы предотвратить катастрофический сбой в будущем.
Ключевые принципы :
- Гипотеза стабильного состояния: Прежде чем вводить сбой (например, отключение базы данных), SRE определяет "норму" и формулирует гипотезу: "Удаление этого контейнера не повлияет на авторизацию пользователя".
- Минимизация радиуса поражения (Blast Radius): Эксперименты тщательно планируются, чтобы минимизировать негативное влияние на клиентов.
- Автоматизация: Тестирование устойчивости должно стать непрерывным, интегрированным в CI/CD-пайплайн процессом.
Устранение рутинной работы (Toil Reduction)
Toil — это ручная, повторяющаяся, не имеющая долгосрочной ценности работа (например, ручное развертывание или обработка рутинных алертов).
SRE-принцип гласит: команда должна тратить не менее 50% времени на инженерные улучшения и проактивную работу. Если команда погрязла в Toil, она не может заниматься стратегическим управлением риском.
Стратегии просты: аудит рутины и тотальная автоматизация с помощью скриптов и Infrastructure as Code (IaC). Устранение Toil высвобождает ресурсы для архитектурных улучшений и, что важно, позволяет сосредоточиться на задачах, которые реально влияют на SLO.
Постмортемы без обвинений (Blameless Postmortems)
Инцидент — это ценный урок. Культура постмортемов без обвинений гарантирует, что фокус смещается с поиска виновного ("Кто?") на анализ системных и процедурных условий ("Что?" и "Как?").
Предполагается, что каждый действовал, исходя из наилучших намерений. Такой подход:
- Снижает страх эскалации: инженеры охотнее сообщают о проблемах, что помогает выявить скрытые уязвимости.
- Повышает качество: каждый постмортем завершается конкретными корректирующими действиями (Action Items), которые затем приоритизируются (часто в виде P0/P1 задач).
Заключение: SRE — архитекторы устойчивого будущего
SRE — это не просто должность, это целостная, замкнутая система управления рисками. Она дает организации инструментарий для ответа на главный вопрос: сколько риска мы можем себе позволить?
Через SLO мы устанавливаем границу допустимого, а Бюджет ошибок контролирует, чтобы эту границу не пересекли. Этот механизм, подкрепленный мощной системой Обсервабилити и проактивными практиками Инженерии Хаоса и Устранения Toil, позволяет:
- Гарантировать, что мы тратим ровно столько денег на надежность, сколько нужно клиенту.
- Обеспечить высокую скорость внедрения новых функций, когда бюджет позволяет риск.
- Мгновенно переключать фокус всей команды (SRE и Dev) на стабильность, как только бюджет исчерпан.
SRE позволяет компаниям расти устойчиво, постоянно повышая качество сервисов, но при этом не жертвуя скоростью инноваций. Это инженерный подход к выживанию в мире распределенных систем.
Если вам понравился материал, не забудьте поставить палец вверх 👍 и поделиться статьёй с друзьями. Подписывайтесь на мой Telegram-канал, чтобы первыми узнавать о новых статьях и полезных материалах. А также загляните на сайт RoadIT.ru, где я собираю заметки о командах Linux, HowTo-гайды и много другой интересной информации. Спасибо за внимание!