Технологии оптического распознавания символов (OCR) – незаменимый инструмент для цифровизации бизнеса. Благодаря технологиям OCR больше не нужно вручную переносить данные из документов во внутренние системы и тратить время на раздражительную рутину. Рассказываем, как автоматическое распознавание документов помогает оптимизировать документооборот в компаниях и почему для прозрачного и достоверного извлечения данных лучше подходят OCR, а не IDP-решения.
Зачем нужны технологии OCR
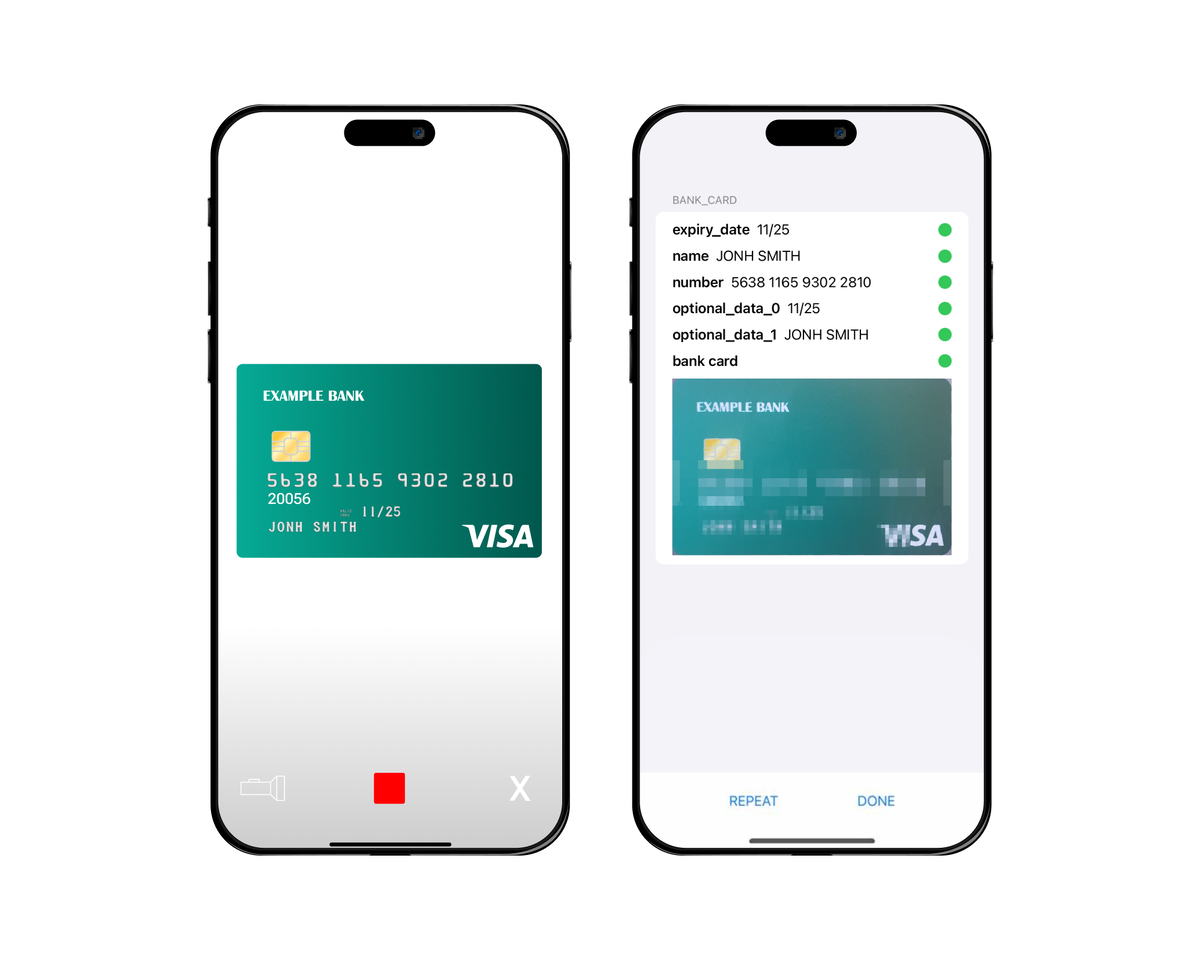
Системы OCR позволяют распознавать символы на изображениях и видео и автоматически переводить их в редактируемый цифровой формат. Благодаря таким решениям вместо длительной и трудоемкой перепечатки данных содержимое документов можно извлечь за доли секунды – в готовом для интеграции в корпоративные системы виде. Промышленные OCR-системы работают в контуре безопасности компании (on-premise) и не передают данные в “облако” для распознавания. Такой подход позволяет исключить риски утечки данных и защищает коммерческую тайну от компрометации.
Благодаря технологиям распознавания бизнес получает возможность быстро работать с большим числом поступающих документов, не расширяя при этом штат сотрудников. Десятки минут, которые раньше уходили на ручной ввод данных, можно использовать для общения с клиентами, взаимодействия с контрагентами, развития продаж и других стратегических бизнес-задач. Это позволяет оптимизировать внутренние процессы, увеличить показатели конверсии и значительно улучшить клиентский опыт.
В каких областях применяются OCR-системы
Сегодня OCR-системы можно встретить практически во всех сферах – в банкинге, финтехе, страховании, промышленности и бизнесе. Технология позволяет автоматизировать ведение бухгалтерского учета, ускорить найм сотрудников, организовать потоковый ввод информации из финансовых, кассовых и юридических документов, наполнять и оцифровывать архивы. Приведем несколько примеров применения OCR в разных сферах.
Ежедневный банкинг
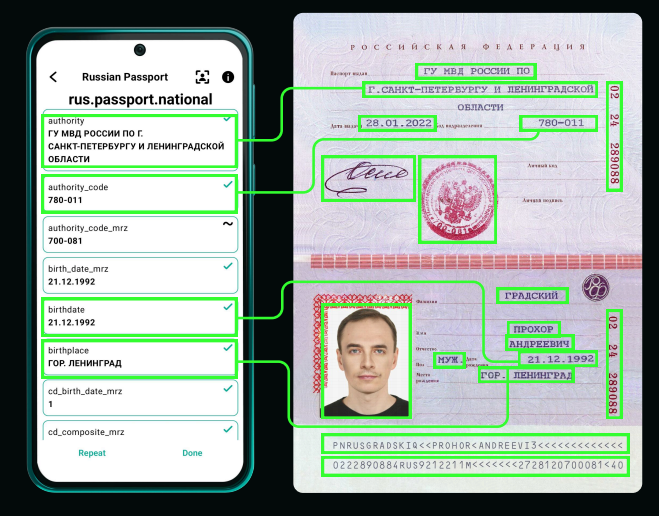
OCR используется для подтверждения личности клиентов и KYC при оформлении финансовых продуктов и подключении услуг. Автоматическое распознавание паспорта, анкеты банка и других документов позволяет в разы ускорить процесс открытия счета или оформления кредита. Распознавание широкого диапазона документов – от паспортов и свидетельств о заключении брака до справок о доходах – облегчает построение кредитного конвейера для физических и юридических лиц.
Бухгалтерия
Технологии OCR помогают автоматизировать ввод бухгалтерской первички: накладных, актов приемки-передачи, платежных поручений, форм ТОРГ-12 и других документов. Искусственный интеллект автоматически извлекает даты, суммы, данные контрагентов, наименование, количество и стоимость товарных позиций в таблицах, а также НДС и другие реквизиты. Все это ускоряет процессы ведения бухгалтерского учета, учета НДС и налогов по УСН. Передовые системы способны вводить данные документов со скоростью 900 страниц в секунду: это позволяет за один час выполнять работу, которую делают 10 бухгалтеров за месяц.
Трудоустройство
Системы OCR нередко применяются для распознавания и ввода данных из комплектов кадровых документов. Распознавание документов для трудоустройства (печатных и рукописных данных из паспортов, СНИЛС, ИНН, трудовых книжек, свидетельств органов ЗАГС, дипломов об образовании и других) позволяет организовать массовый найм сотрудников. Сегодня это особенно востребовано в торговых сетях, строительном бизнесе, такси и других сферах. Современный ИИ поддерживает более 100 типов документов России и стран СНГ, а также документы Китая, Индии, Пакистана и еще свыше 230 юрисдикций.
Логистика
OCR используется как в транспортной, так и в складской логистике для считывания маркировки грузовых контейнеров, проверки номеров пломб, данных на посылках. Системы также автоматически извлекают данные из накладных, счетов-фактур и таможенных форм. Преимущество искусственного интеллекта в этой области связано не только со скоростью работы, но и с возможностью надежно считывать данные даже в условиях низкой освещенности складов и терминалов.
Несмотря на широкое распространение, далеко не все системы ИИ для работы с документами в одинаковой степени полезны и эффективны. Прежде всего, надежные решения отличает высокое качество распознавания символов. Если система обеспечивает недостаточное качество или пытается компенсировать слабый OCR-движок с помощью технологических “костылей”, заказчик обречен на риски. Рассмотрим, к чему это может привести, на примере платформ IDP.
Что такое IDP и в чем тут загвоздка
Аббревиатура IDP расшифровывается как «интеллектуальная обработка документов». Такие решения предлагают возможности интерпретации распознанного текста при помощи больших языковых моделей (LLM). Сегодня продукты категории IDP преподносят как новейший инструмент интеллектуальной автоматизации, однако на деле все сводится к пустому маркетингу. Под видом революционного бизнес-инструмента разработчики зачастую продают слабую технологию OCR, соединенную с большой языковой моделью для корректировки плохо распознанных данных.
Поскольку большие языковые модели опираются на частотность слов в текстовых массивах и словарях, а также подвержены галлюцинациям, возникает риск неконтролируемой подмены данных. Например, если отдельное слово, наименование или дата в документе были распознаны плохо, технология IDP может “додумать” их без ведома пользователя – причем нет никаких гарантий, что технология угадает верно. Более того, в ходе обработки документов может быть исправлена информация, которая вообще не нуждается в исправлении. В результате достоверность данных, извлеченных при помощи технологий интеллектуальной обработки, оказывается в разы ниже, чем у оптического распознавания.
С практической точки зрения внедрение IDP ставит пользователя перед безвыигрышной ситуацией: либо вручную перепроверять все данные, либо же брать на себя последствия за ошибки и быть готовым к финансовым издержкам, проблемам с налоговой и претензиям контрагентов. В обоих случаях говорить о реальной автоматизации бизнес-процессов, повышении эффективности и увеличении конверсии, невозможно. Если вам требуется высокое качество распознавания, достоверность данных и работа в контуре, – лучше сделать выбор в пользу надежной технологии OCR.
Что отличает надежную систему распознавания?
Если вы собираетесь интегрировать технологии OCR в бизнес-процессы, следует обратить внимание на качество распознавания и технологическую зрелость продукта. Важно, чтобы такое ПО
- было проприетарным,
- обеспечивало защиту данных и коммерческой тайны при распознавании,
- работало на разных платформах и ОС, включая российские,
- поддерживало разные типы и шаблоны документов с печатным и рукописным заполнением.
Все эти особенности позволяют не только легко адаптировать технологию на любой сценарий, но и обеспечить прозрачность и достоверность данных без рисков для бизнеса.
В Smart Engines мы ответственно подходим к созданию решений для распознавания документов. В основе наших технологий лежит собственный движок OCR и десятилетия научных исследований в области распознавания символов и обработки изображений.
Решения Smart Engines обеспечивают высочайшую точность распознавания данных без галлюцинаций и работают на серверах, в мобильных приложениях и браузере. Узнать подробнее о технологиях распознавания документов от Smart Engines.