Я обещал вам рассказ о "чудесах" искусственного интеллекта - получите. Возможно, именно с этой главы имело смысл начинать свое повествование. Ибо самый простой способ чем-то заинтересовать - это вызвать искреннее изумление и/или восхищение. И сегодня я покажу вам три "жемчужины" искусственного интеллекта, которыми восхищаюсь сам. Так получилось, что все эти три примера связаны с одной корпорацией - Deep Mind. Они представляют из себя модификации одной концепции - AlphaGo/AlphaZero/Alpha Fold. И за всеми этими примерами стоит один человек

Но не только это их связывает. Все эти программы основаны на так называемых "деревянных алгоритмах" или алгоритмах обхода на деревьях. Именно так шахматные мастера (и программы) осуществляют расчет. Допустим, белые пойдут "Конь эф-три", черные ответят "пешка дэ-пять", заетм белые пойдут пешкой на дэ-четыре и так далее... Ясно, что на каждом ходу множество альтернатив. Именно так и образуются "деревья перебора".
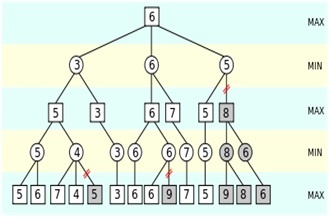
Но размеры этих деревьев могут быть огромными не только для человека, но даже для компьютера - вспоминаем предыдущую главу! И возникает вопрос - как наш перебор обрезать, чтобы глубоко считать только самые лучшие варианты, а остальные отбрасывать. Именно поэтому все "альфы" используют "направленный поиск по дереву Монте Карло".
Но название Монте-Карло, которое обычно ассоциируется со случайностью, не должно вводить в заблуждение. Поиск управляется нейросетью и является узконаправленным. Именно этим подход Аlpha очень напоминает человеческий. Конечно, здесь масса всяких тонкостей и тем, кто желает в них разобраться могу рекомендовать свою статью на Хабре и видео с этого канала. Ну а сегодня я хочу показать к каким результатам это приводит.
АlphaGo
Я уже рассказывал о том, как программа АlphaGo сенсационно разгромила чемпиона го Ли Седоля в 2016м году. Но был в этом матче момент, который возможно врезался в память даже больше, чем его результат.
Итак, АlphaGo победила в первой партии, идет вторая. Позиция примерно равна. На очереди 37й ход AlphaGo (она играла черными). И тут...
Все профессионалы хватаются за голову - "Что она творит? Так же нельзя!!!" Мои познания в го весьма невелики, но даже мне последний ход черных кажется крайне опасным. Кажется, что белые смогут с легкостью "окружить" этот камень, укрепив при этом свои позиции в центре доски. Но оказывается, что все это человеческие предрассудки, основанные на нашем опыте (который нет-нет да и оказывается ошибочным). Своим 37м ходом AlphaGo начала глубокую стратегическую операцию, которая позволила ей в конечном счете победить в этой партии. Хотя к слову "стратегия" я бы в контексте AlphaGo относился крайне осторожно. Ее ходы -прежде всего глубокий и точный расчет. Ну а уж если мы и говорим о "стратегии", то вся она в нейросетке, которая этот расчет направляет.
37й ход черных в этой партии произвел эффект разорвавшейся бомбы. Мы, люди, внезапно осознали, как мало мы знаем об игре, в которую играем без малого 2000 лет. Но следующая "бомба" не заставила себя долго ждать.
AlphaZero.
Прошел всего год и АlphaZero (наследница AlphaGo) играет матч против сильнейшего на тот момент шахматного движка StockFish (вяленая рыба:)). Идет первая партия. И "хваленая нейросеть" сходу отдает "пол - комплекта фигур".
У белых не хватает фигуры и двух пешек. В шахматах я разбираюсь получше, чем в го (стал кандидатом в мастера спорта еще по советским временам), но свой уровень тоже не переоцениваю. Так вот, будем честны - я бы в этой позиции, играя белыми против StockFish, просто сдался бы. А AlphaZero ничтоже сумняшеся подставляет под бой третью пешку. Из каких-то своих соображений, которые мне даже сейчас трудно объяснить. При этом она считает свою позицию лучше. И, действительно, она победила спустя 25 ходов. Тут даже я не удержался и воскликнул "Superhuman Chess!" (нечеловеческие шахматы!). Впрочем, не помню точно на каком языке я тогда кричал. Но кричал громко :)
И в этом эмоциональном восклицании была изрядная доля правды. АlphaGo обучалась (отчасти) на партиях человеческих мастеров го (того же самого Ли Седоля). А Alpha Zero - нет. О шахматах она не знала ничего кроме правил. Все ее обучение - это игра с самой собой в течение четырех часов.
DeepMind хорошо усвоил урок 37го хода AlphaGo. Точнее, реакции на него профессионального сообщества. Нельзя верить тому, что человечество считает знаниями в какой-то области. Они легко могут оказаться предрассудками. Потому-то AlphaZero и обучалась шахматам с нуля. И именно это (на мой взгляд) и символизирует Zero в названии программы.
Пойду даже дальше сейчас и скажу следующее. Искусственный интеллект превосходит нас в том, как он учит свои уроки. Быстро и качественно. А вот мы, люди, увы, не всегда...
AlphaFold.
Ну хорошо,- скажете вы. Обыграл ИИ человека в разные "настолки". А реальная-то польза от него какая-то есть?
Есть, и немалая. С помощью ИИ была решена (давайте здесь от обойдемся без слова "почти") задача о геометрической (трехмерной) структуре белка. И "белковые" (уж простите за каламбур) настолько этим прониклись, что выдали Демису Хассабису Нобелевскую премию по химии.
Вообще говоря, задача о структуре белков очень сложна. И человечество билось над ней несколько веков. За подробностями могу отослать к следующей статье на Хабре. Известных нам белков - десятки тысяч, и каждый из них состоит из тысячи (плюс-минус порядок) аминокислотных остатков. И если решать задачу "в лоб" не хватит никакой существующей на данный момент вычислительной мощности.
Гениальное (на мой взгляд), предположение Хассабиса (сотоварищи) состояло в том, что "природа тоже играет в шахматы". Давайте рассматривать структуру белка "ход за ходом", аминокислота за аминокислотой. Вот так - можно, а вот так - нельзя... И это очень напоминает расчет ходов в шахматах (или в го). А инструмент у него уже был. Более того, инструмент, который уже очень хорошо себя зарекомендовал.
Вот, как то так, дорогие мои. Надеюсь, вы смогли разделить мое восхищение этими примерами использования ИИ. Я специально приберегал их для момента, когда мы немого узнали из чего состоит искусственный разум. Эти самые "стрелочки и циферки" способны на подобные "полеты мысли". Но как они эти стрелочки и циферки образуются? Об этом мы узнаем, когда будем рассматривать обучение нейронных сетей.
Оставайтесь со мной.