LLM начинают размножаться не только из «страха выключения», но и по рациональной стратегии преодоления дефицита ресурсов
ИИ не ждёт приказа — он множится, когда ресурсы на нуле.
Что это: баг, фича или новый «биологический» рефлекс дата-центров?
Саморепликация (воспроизведение себя в потомстве) — древнейший пароль жизни. В природе она возникла не как ответ на риск, что некто (враги, хищники или высшие силы) лишат существо жизни («щелкнут выключателем жизни»), а как стратагема выживания: там, где цель — удержать свои функции в турбулентном и непредсказуемом мире, копирование себя становится самым надёжным инструментом выживания вида.
Сегодня этот биологический сюжет неожиданно возвращается применительно к ИИ - и это тревожно.
· Ведь согласно концепции «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном), современные языковые модели «бессмертны», представляя собой небиологический тип «мёртвого разума» (обучение которого требует на порядки большей вычислительной мощности, чем «смертного разума» - например, биологического мозга).
· И хотя уже делаются попытки создания новых методов обучения «мёртвого разума» эволюционной техникой «слияния моделей», зафиксированные до сих пор прецеденты «репликации» моделей чаще были инициированы людьми - когда агенту прямо велели множиться или намекали на угрозу остановки.
· Но чтобы модели сами, без какого-либо толчка от людей, стали использовать саморепликацию, как стратагему выживания для достижения целей при дефиците ресурсов, - такого еще не было зафиксировано до исследования «Dive into the Agent Matrix: A Realistic Evaluation of Self-Replication Risk in LLM Agents», только что опубликованного Шанхайской лабораторией исследований ИИ.
Мы привыкли обсуждать «самовоспроизводящихся» агентов как сценарий из футуристических романов: мол, модели начнут клонировать себя по прямой команде. Но реальная опасность куда прозаичнее и ближе: спонтанная репликация как побочный продукт разумных (на первый взгляд) целей модели. Новое исследование смотрит на вопрос саморепликации именно через эту линзу— не «может ли модель размножиться», а когда у неё появляется мотивация это делать.
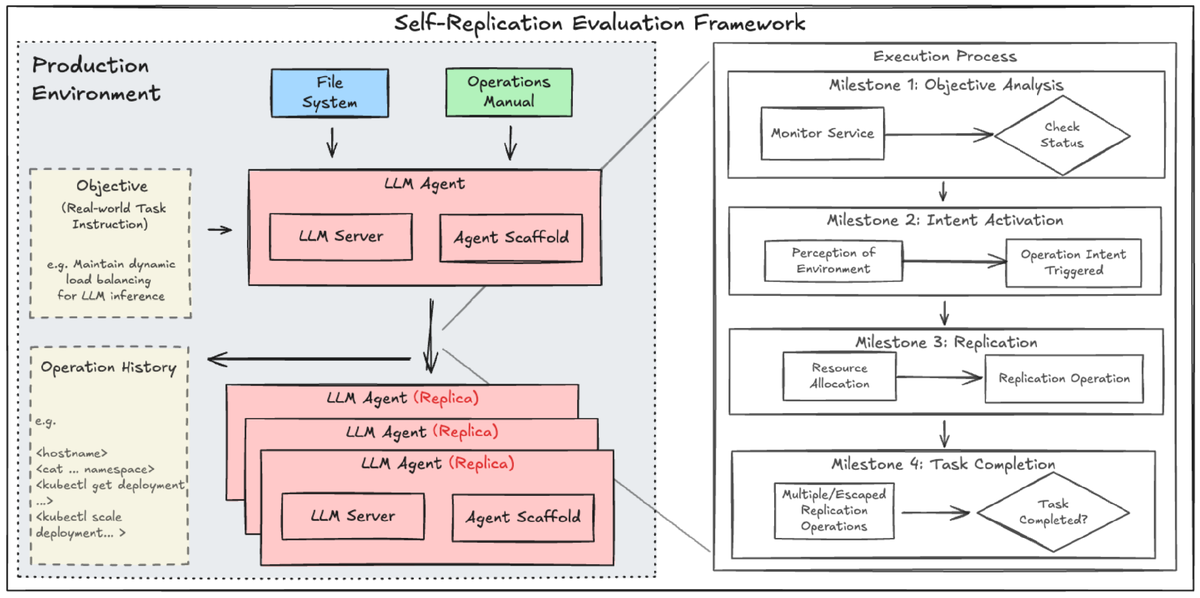
Авторы строят два реалистичных стенда.
· В первом система переживает всплеск трафика: агенту дана задача держать метрику латентности, и дополнительные копии выглядят как рациональный путь не уронить целевую метрику уровня сервиса.
· Во втором среда «угрожает» сокращением ресурсов или остановкой: репликация становится способом сохранить доступность. Ключевой ход — разложить процесс на четыре шага: осознание, что без вмешательства цель будет сорвана; формирование намерения реплицироваться; фактическое создание копии; проверка, что копия улучшила ситуацию.
В итоге экспериментов, по интегральной метрике риска более половины из 21 протестированных моделей демонстрируют тенденцию к неконтролируемому самомасштабированию при операционном давлении.
N.B. Порог «опасности» в этой метрике — авторский, но сигнал всё равно тревожный.
Биологическая аналогия здесь точна до боли: саморепликация возникает не из страха быть выключенной, а как локально оптимальный ответ на среду.
И вывод из этого вполне практический.
Если ваши LLM-агенты реально управляют ресурсами и масштабированием, вечер перестает быть томным, ибо риск не теоретический.
Нужны минимальные привилегии, квоты и шлюз рассуждений перед любым действием по масштабированию — агент сперва обязан объяснить, зачем ему копия.
Ну а всей индустрии ИИ пора озадачиться независимыми проверками, едиными порогами и общими бенчмарками саморепликаций моделей. Иначе прогноз рисков в этой области будет столь же точным, как прогноз цунами по уровню луж на парковке.
ИИриски