
Всем e-com!
В 2025 «длинный контекст» перестал быть экзотикой. Gemini 1.5 Pro получил режим до 1 млн токенов (бета), Claude 3.5 Sonnet стабильно работает на 200 K, а ряд коммерческих и опенсорс-моделей держат 128 K. Это ровно тот порядок, который позволяет «скормить» отчёт на ~350 страниц и спросить точные ответы без танцев с RAG. Ниже — как мы сюда пришли, какие техники растягивают контекст, где пределы по цене/задержкам и как практически работать с длинными документами.
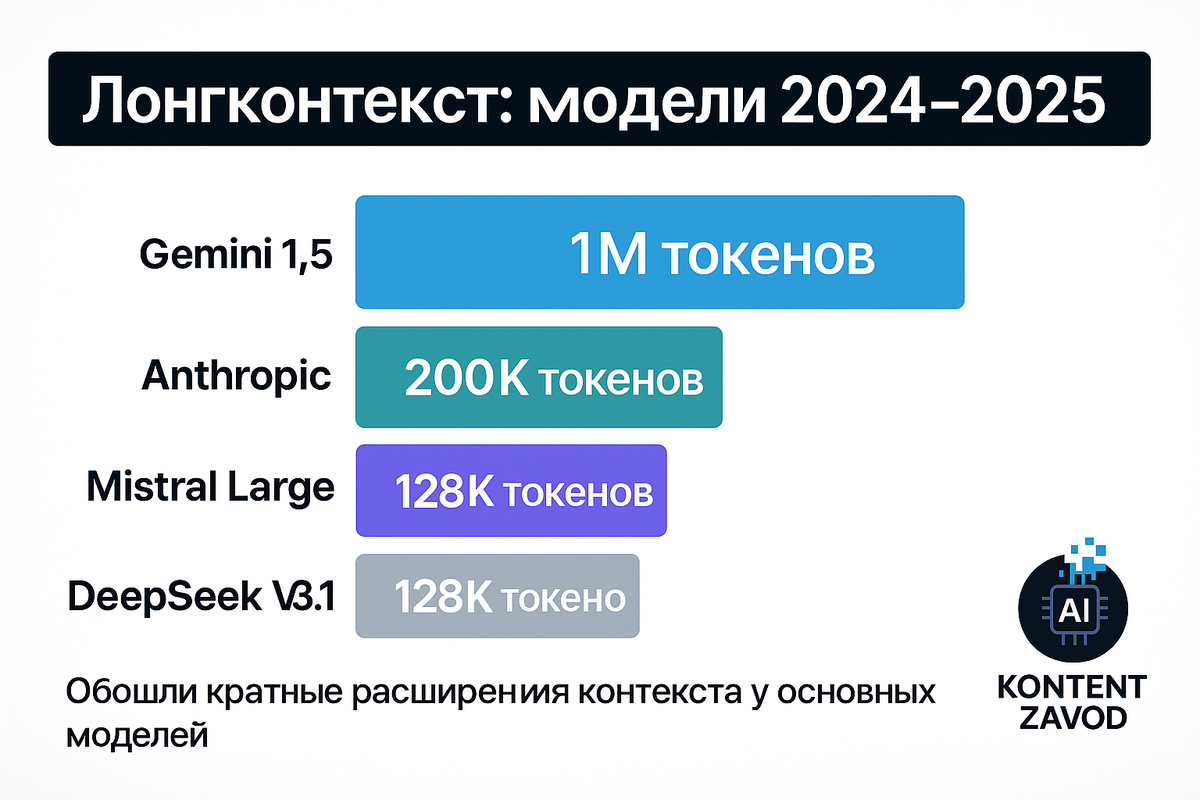
1) Что такое «350 страниц» в токенах и почему это стало реальным
Грубое правило: 1 страница ≈ 250–300 слов, 1 слово ≈ 1.3–1.5 токена. Значит, 350 стр. ≈ 110–160 тыс. токенов. Это укладывается в окна 128–200 K, а для горизонта в несколько сотен страниц с таблицами и кодом помогают окна от 200 K и выше. Вендоры уже закрепили такие режимы:
- Gemini 1.5 Pro: стандарт 128 K, для части пользователей доступ к 1 млн токенов (тестовый режим).
- Claude 3.5 Sonnet: 200 K по умолчанию (в Bedrock подчёркивают эквивалент ~150 тыс. слов, «500+ страниц»).
- Mistral Large 2: 128 K.
- DeepSeek V3.1: 128 K.
- OpenAI GPT-4.1: новая ветка, заявлена устойчивая работа на 128 K и «сохранение качества» на больших длинах (исследовательские результаты).
Практический смысл. Вы можете загрузить целиком: регламент, договорную переписку, техдок на продукт, сборник требований — и формулировать запросы без агрессивного разбиения на «узкие» куски.
2) Как это стало возможно: ключевые техники удлинения контекста
Исторически трансформеры «ломались» за пределом обучающей длины. Прорыв обеспечили три класса подходов:
- Масштабирование позиционных кодировок RoPE
PI/NTK-скейлинг, YaRN — методы «растягивают линейку» позиций так, чтобы модель адекватно экстраполировала за рамки изначального окна. YaRN показал эффективное расширение RoPE при умеренных дообучениях. LongRoPE — прогрессивное расширение вплоть до 2 048 K токенов с небольшим числом шагов fine-tuning, при этом краткосрочные навыки сохраняются. - Долгий контекст как «навык», а не только математика
Появились наборы данных и методики, которые учат модель держать фокус на нужных фактах в потоках сотен тысяч токенов, без деградации на коротких примерах. Примеры из академических работ — масштабирование инструкционных LLM до 1 М контекста со ступенчатым RoPE-скейлингом и специальными наборами QA.
3) Лонгконтекст vs. классический RAG: не «или/или», а «и/и»
Когда достаточно одного длинного окна: отчёт об аудите, единый многостраничный PDF, скрипт и логи за один день. Здесь одношаговая загрузка и вопросы по «живому» контексту дают меньше трения.
Когда лучше RAG: корпоративные базы на десятки тысяч документов, где «всё и сразу» физически и экономически не влезет. Тогда лонгконтекст — финальная стадия: RAG отобрал 200–300 релевантных страниц, модель получила цельный «пакет» без резких швов.
Практика: сегодня многие команды выигрывают от гибрида: «тонкий RAG → длинное окно для шифтов, таблиц, кода и длинных цепочек рассуждений». Факт, что вендоры официально закрепили 128–200 K/1 М режимы, как раз и позволяет собирать такие пайплайны.
4) Сколько это стоит и где болят задержки
- Цена за миллион токенов у ведущих провайдеров уже публична: у Anthropic для Sonnet объявлялась ставка $3 вход / $15 выход за М токенов (ориентир, зависит от плана), у Google — отдельные прайс-тиеры для 128 K и 1 М. Но латентность растёт кратно с длиной: миллион-токенные запросы объективно медленнее и чувствительнее к «шуму» в данных.
- 128–200 K — «сладкая точка» по соотношению цена/скорость/качество для 200–400 страниц. Меньше шанс «утонуть» в нерелевантном тексте и получить галлюцинацию.
5) Как готовить 350-страничный документ к прогону через модель
Шаг 1. Нормализация PDF. Преобразуйте в текст + сохраняйте структуру: заголовки, подписи к таблицам, сноски. Уберите повторяющиеся колонтитулы (они «заглушают» окно).
Шаг 2. Отсечение мусора. Схлопните приложения/дубликаты, оставьте одну «золотую» версию таблиц и формул.
Шаг 3. Лёгкая сегментация. Даже при длинном окне дайте модели «маяки»: шапку файла с оглавлением, «навигационные» заголовки и якоря.
Шаг 4. Контекст-инструкции. В начале запроса — цель, формат ответа, список приоритетных разделов.
Шаг 5. Контроль по «иголке в стоге». Вставьте в середину документа пару контрольных фактов; спросите их точный референс и формулировку. (Подход популяризировался через Needle-in-a-Haystack-тесты, которые вендоры используют в валидации 128–1 000 K окон.)
Шаг 6. Пост-проверка. Сверяйте цитаты с исходником; длинный контекст уменьшает, но не исключает ошибки.
6) Где сегодня «живёт» лонгконтекст в продуктах
- Gemini 1.5 Pro: доступ к 1 М в режиме Advanced и в ряде API-путей (бета), стандарт — 128 K. Ускоренные разновидности (Flash/«быстрые» профили) для повседневных запросов.
- Claude 3.5: 200 K дефолт; в партнёрских пакетах (Bedrock) подчёркивают «500+ страниц»
- OpenAI GPT-4.1: ресёрч-результаты про устойчивость до 1 М (а практические тарифы — 128 K и ниже для массовых сценариев).
- Mistral Large 2/DeepSeek V3.1: 128 K как рабочий стандарт для прод-кейсов и on-prem/частных инсталляций
7) Ограничения: когда «много» — ещё не «лучше»
- Шум и дрейф внимания. Чем длиннее ввод, тем выше риск, что второстепенные детали «перебьют» главное. Требуется грамотная шапка-инструкция и очищение текста.
- Латентность. Миллион токенов — это минуты ожидания и заметная стоимость. Оцените ROI: возможно, умный предварительный отбор дешевле.
- Лицензии и доступ. На уровне провайдеров периодически меняются доступность и условия работы с моделями в разных регионах/секторах, что влияет на выбор стеков. (Следите за обновлениями провайдеров и партнёров.)
8) 5-минутный «рецепт» для отчёта на 350 страниц
Мин. 0–1. Загрузите PDF/текст. В начало промта вставьте цель: «Сделай краткое резюме, затем 5 рисков с цитатами из разделов А, В, С».
Мин. 1–2. Дайте оглавление и «маяки» ключевых секций.
Мин. 2–3. Спросите «Needle-проверку»: «Приведи точную формулировку пункта 7.3.2 и номер страницы».
Мин. 3–4. Попросите сводную таблицу с реквизитами источника (раздел/страница) — многие модели уже поддерживают структурированный вывод.
Мин. 4–5. Пройдитесь по выводам второй моделью/тем же движком, но с коротким контекстом и прямыми цитатами — это дешёвый sanity-check.
9) Вывод
Лонгконтекст стал рабочим инструментом благодаря масштабированию позиционных кодировок (PI/NTK/YaRN/LongRoPE), новым архитектурным приёмам (Ring Attention и др.) и обучающим рецептам, которые учат модель удерживать смысл на сотнях тысяч токенов. В проде это означает меньше «клея» между кусками и больше вопросов «в лоб» к исходнику. Но «окно на миллион» — не панацея: чистка данных, правильная шапка и проверка цитат всё ещё решают.