🔥 OpenAI выкатили GPT-5.1-Codex-Max
Вместе с попыткой перекричать хайп вокруг Gemini 3 есть следующие интересные нововведения:
1️⃣ Compaction (сжатие контекста)
Это главная фича. Вместо бесконечного раздувания контекстного окна (что дорого и медленно), модель научили "сбрасывать балласт".
Когда лимит окна подходит к концу, она делает умную компрессию истории (pruning), оставляя только важный контекст, и переносит его в новое окно.
👉 Что это дает: OpenAI заявляет, что агент может работать над задачей 24+ часа автономно.
2️⃣ Нативная поддержка Windows и PowerShell
Смешно, но раньше модели обучались преимущественно на Linux-среде. Теперь Codex официально "шарит" в специфике Win-окружения.
3️⃣Оптимизация токенов
Заявляют, что новая модель на 30% эффективнее по токенам при том же качестве.
Сейчас главный недостаток лучших моделей в том, что любая сложная задача сжирает бюджет API быстрее, чем рождается нормальное решение. Уменьшение костов — всегда хорошо.
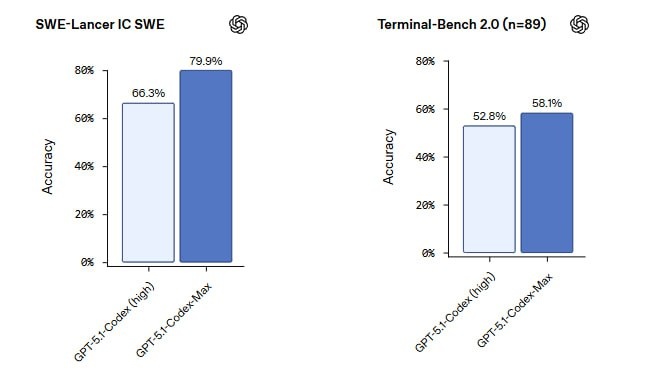
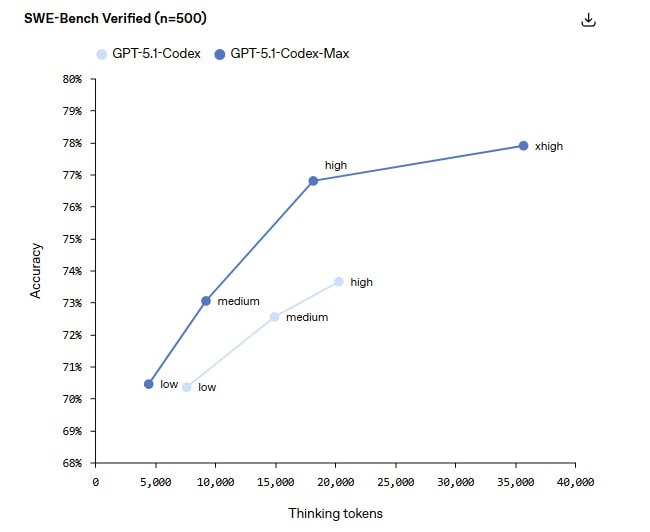
4️⃣SOTA на бенчмарках
SWE-bench Verified — 77.9%. Это выше, чем у Claude 3.5 Sonnet и новых Gemini.
Плюс ввели режим xhigh (extra high reasoning) — для тех случаев, когда вам не важна скорость, но нужно, чтобы нейронка "подумала" подольше и не наговнокодила.