Исследовательская команда Microsoft представила AsyncThink — способ организации внутреннего рассуждения больших языковых моделей (LLM) в форме асинхронной «организации‑агентов», позволяющий моделям одновременно выступать и как «организатор», и как «исполнитель».
По сути, это шаг от одиночного агента к организованной группе внутренних рабочих (worker) с протоколом Fork–Join; цель — повысить точность рассуждений и существенно снизить задержки.
Ключевая идея
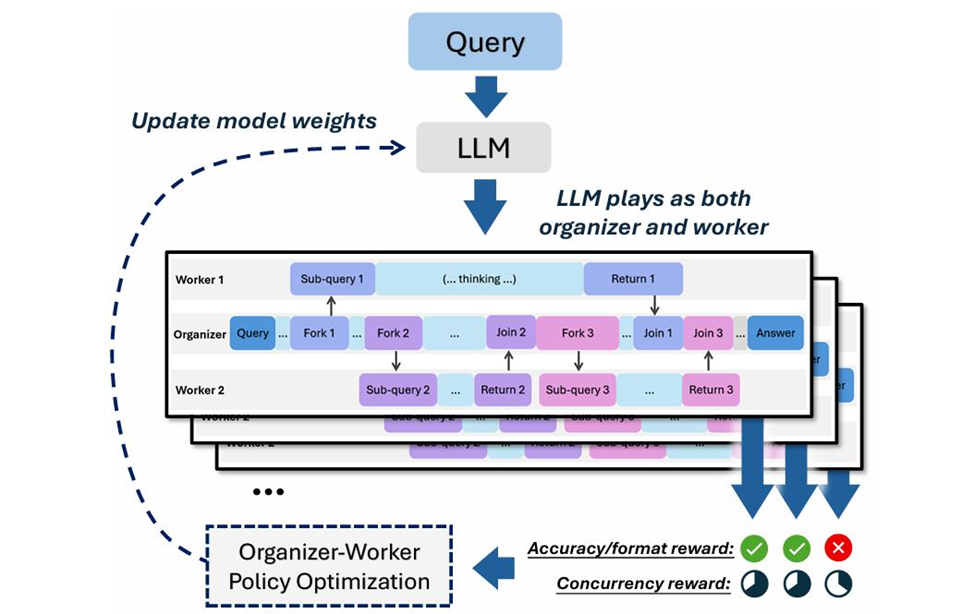
AsyncThink строится вокруг протокола Organizer–Worker:
- Организатор разбивает задачу на подзадачи (операции Fork) и управляет их синхронизацией (операции Join).
- Рабочие (workers) параллельно решают подзадачи и возвращают промежуточные результаты, которые организатор интегрирует в финальный вывод.
Такая архитектура даёт возможность динамически менять топологию «мыслительного процесса», параллелить части решения и адаптироваться в ходе рассуждений.
Двухэтапная схема обучения
- Холодный старт — форматная SFT (supervised fine‑tuning)
- Модель учат грамматике и формату AsyncThink (как формировать Fork/Join‑действия).
- Поскольку примеров «организатор–работник» в открытых данных почти нет, для синтеза тренировочного корпуса использовали GPT‑4o, который автоматически генерировал структуры организатора и рабочих для разных задач.
- Цель этапа — научить модель «говорить» в новом формате, но ещё не делать эффективную стратегию распределения работы.
- Усиленное обучение (RL)
- После форматного обучения вводится RL‑оптимизация (модифицированный GRPO), где награды направляют организацию работы на эффективность и точность.
- Функции вознаграждения включают: корректность ответа (accuracy), соблюдение исполняемого формата (format reward) и поощрение за параллелизм/низкую задержку (concurrency/η‑reward).
- Награда распространяется по всей структуре Fork–Join, чтобы каждый компонент оптимизировался в рамках общей цели.
Результаты экспериментов
- Многорешательный countdown — полное совпадение решений: AsyncThink 89.0% vs параллельный подход 68.6% и последовательный 70.5%.
- Математические тесты: AIME‑24 — точность 38.7% (задержка 1468.0), AMC‑23 — точность 73.3% (задержка 1459.5). По сравнению с традиционным параллелизмом задержка сократилась примерно на 28% при росте точности.
- Генерализация: обученная на одной задаче модель успешно перенесла стратегию на 4×4 судоку без дообучения — точность 89.4% и минимальная задержка.
- Абляции подтвердили: Format SFT даёт корректный протокол Fork/Join; RL обучает стратегию «когда Fork/Join»; concurrency‑награда повышает баланс между скоростью и точностью.
Почему это важно
- AsyncThink приближает LLM к «организации интеллектов» (agentic organizations): модель получает внутри себя структуру многопрограммной кооперации, что повышает масштабируемость и гибкость в решении сложных задач.
- Уменьшение задержек при росте точности особенно важно для интерактивных и вычислительно тяжёлых задач (математика, планирование, симуляции).
- Способность переносить организационные шаблоны между задачами намекает на универсальность обучаемых «мыслительных» стратегий.
Ограничения и риски
- Вычислительные и инфраструктурные требования: асинхронное исполнение и параллелизм могут потребовать дополнительных orchestration‑механизмов и ресурсов.
- Обучение зависит от качественно синтезированных данных (GPT‑4o в данном исследовании) — возможны артефакты «самосинтеза».
- Безопасность и верификация: более сложные внутренние топологии усложняют интерпретируемость и проверку корректности промежуточных шагов.
- Масштабирование до сотен/тысяч рабочих и интеграция гетерогенных специалистов (эксперты, инструменты) создают новые проблемы координации и устойчивости обучения.
Дальнейшие направления
Авторы предлагают три вектора развития:
- Масштаб и разнообразие рабочих: изучить scaling laws при росте числа и гетерогенности workers.
- Рекурсивные организации: рабочие могут становиться суб‑организаторами, создавая многоуровневые Fork–Join иерархии.
- Гибрид человек–AI: интеграция людей как организаторов или рабочих в асинхронной структуре для совместного планирования и валидации.
Заключение: AsyncThink — важный шаг к практическим «интеллектуальным организациям», где внутренняя архитектура рассуждений становится гибким, параллельным и адаптивным инструментом.
Метод показывает обещающие результаты по точности и латентности и задаёт направление для работы над масштабируемыми, интерпретируемыми и гибридными AI‑организациями.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru
Сайт https://www.smssystems.ru/razrabotka-ai/