Каждый, кто хоть раз всерьёз гонял запросы к большим языковым моделям типа GPT или Claude, знает, как больно бывает смотреть на счётчик токенов. Ты вроде просто отправляешь список пользователей в JSON, а нейросеть уже съела половину твоего бюджета. Все эти скобочки, кавычки, повторяющиеся ключи — они же тоже токены, за которые капает копеечка. И вот, кажется, кто-то услышал наши молитвы. На GitHub появился проект под названием TOON, который обещает сократить потребление токенов чуть ли не вдвое. Звучит как магия, но давайте разберёмся, что это за зверь такой, этот TOON формат данных, сможет ли он стать реальной альтернативой JSON для LLM и как вообще использовать TOON, чтобы начать экономить уже сегодня.
Что за TOON такой и почему он экономит ваши деньги на токенах?
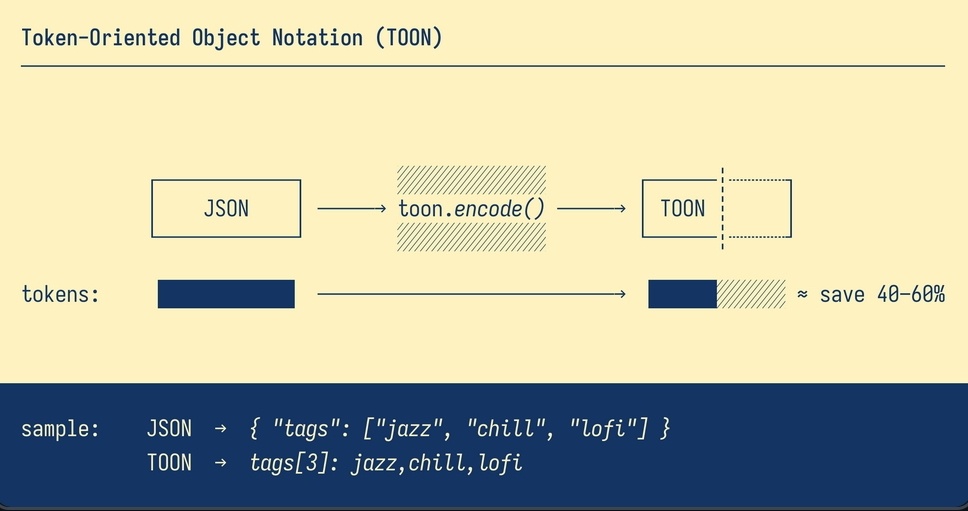
Если говорить по-человечески, TOON — это такой специальный формат для упаковки данных, придуманный специально для скармливания их нейросетям. Его полное имя — Token-Oriented Object Notation, то есть «объектная нотация, ориентированная на токены». Вся его суть в том, чтобы передать ту же самую информацию, что и в JSON, но с минимальным количеством символов, которые потом превратятся в токены. Представьте, что вы взяли лучшее от YAML (структура с отступами, без лишних скобок) и от CSV (табличное представление данных, где заголовки пишутся один раз), смешали это и выкинули весь синтаксический мусор. Вот это и будет TOON.
Это что, просто ещё одна замена JSON?
Не совсем. TOON — это не универсальный убийца JSON. Его придумали не для того, чтобы хранить в нём конфиги или обмениваться данными между серверами. Его главная и, по сути, единственная задача — быть максимально эффективным «транспортным» форматом для промптов. Идея такая: в своём коде вы работаете с привычным JSON, а в тот момент, когда нужно отправить данные в LLM, вы одной командой конвертируете их в TOON. Нейросеть получает компактные данные, обрабатывает их, а вы платите меньше. Все в выигрыше.
Главные фишки: за счёт чего TOON так эффективен?
Вся магия кроется в паре простых идей. Во-первых, долой фигурные скобки и большинство кавычек. Для вложенности используются отступы, как в Python. Во-вторых, и это главное, — работа с однородными массивами. Если у вас есть список объектов с одинаковыми полями (например, список пользователей), TOON объявляет ключи (id, name, role) всего один раз в заголовке, а дальше идут только сами данные, разделённые запятыми. То есть вместо того, чтобы сто раз писать "id", "name", "role", вы пишете их один раз. Экономия налицо.
TOON против JSON: наглядное сравнение и реальная экономия
Лучше один раз увидеть. Вот стандартный JSON с двумя пользователями:
```json
{
"users": [
{ "id": 1, "name": "Alice", "role": "admin" },
{ "id": 2, "name": "Bob", "role": "user" }
]
}
А вот как те же самые данные выглядят в формате TOON:
users{id,name,role}:
1,Alice,admin
2,Bob,user
Разница очевидна. Никаких лишних скобок, кавычек и повторяющихся ключей. Только суть.
Сколько токенов можно на самом деле сэкономить?
Авторы проекта приводят бенчмарки, и цифры впечатляют. На наборах данных с табличной структурой экономия по сравнению с обычным JSON может достигать 40-60%. Даже по сравнению с компактным JSON (без пробелов) выгода составляет 20-30%. Конечно, в реальной жизни всё зависит от структуры ваших данных, но даже если вы сэкономите 30% на каждом большом запросе к API, за месяц набежит приличная сумма.
В каких случаях старый добрый JSON всё-таки лучше?
TOON — не серебряная пуля. Его сила — в однородных табличных данных. Если же у вас глубоко вложенные структуры, где у каждого объекта свой уникальный набор полей, или данные совсем разношёрстные, то выигрыш будет минимальным, а в некоторых случаях JSON может оказаться даже эффективнее. Так что TOON — это идеальный инструмент для передачи списков, логов, аналитики, то есть всего того, что легко представляется в виде таблицы.
Как использовать TOON в своих промптах для LLM: краткая инструкция
Хорошо, звучит интересно. Как это прикрутить к своему проекту? На самом деле, всё довольно просто.
Пример: превращаем громоздкий JSON в компактный TOON
Для начала нужно установить библиотеку. Например, для Node.js это делается командой npm install @toon-format/toon. А дальше всё элементарно. У вас есть объект JavaScript, вы просто передаёте его в функцию encode.
import { encode } from '@toon-format/toon'
const data = {
users: [
{ id: 1, name: 'Alice', role: 'admin' },
{ id: 2, name: 'Bob', role: 'user' }
]
}
const toonString = encode(data)
console.log(toonString)
На выходе вы получите ту самую аккуратную строку в формате TOON, готовую для вставки в промпт.
Как правильно «объяснить» этот формат нейросети?
Самое забавное, что часто и объяснять ничего не нужно. Модели вроде GPT-4 отлично понимают такой формат интуитивно, видя его структуру. Лучшая стратегия — «покажи, а не расскажи». Просто дайте пример в промпте.
Например: «Проанализируй следующие данные в формате TOON. Формат использует отступы, а в заголовках массивов указано количество элементов и поля. Вот данные: [сюда вставляете ваш TOON]». Как правило, этого более чем достаточно. Модель видит паттерн и легко с ним работает.
Насколько это серьёзно? Проект на GitHub и его будущее
Вся эта история выглядит не как поделка на коленке, а как вполне себе серьёзный проект. Он живёт на GitHub, полностью открыт, и вокруг него уже начинает формироваться сообщество.
Почему open-source — это важно для такого формата?
Открытый исходный код — это гарантия прозрачности и доверия. Вы видите, как всё работает, и можете быть уверены, что там нет никаких сюрпризов. Более того, это позволяет сообществу развивать проект. Появилась проблема? Кто-то может прийти и исправить её. Нужна поддержка нового языка? Энтузиаст напишет реализацию. Это защищает формат от того, чтобы он не загнулся, если вдруг его авторам станет не до него.
Что там с поддержкой в разных языках программирования?
И вот это круто. На странице проекта уже есть список реализаций для кучи языков: Python, .NET, Go, Rust, PHP, Java, Swift и других. Это значит, что TOON можно внедрить практически в любой стек, не привязываясь к одной экосистеме.
В общем, TOON — это чертовски интересный инструмент для всех, кто активно работает с LLM. Это не революция, которая убьёт JSON, а скорее умная утилита, которая решает одну конкретную, но очень больную проблему — стоимость токенов. И, кажется, решает её весьма изящно.
🔔 Если статья была полезной, жмите на колокольчик на главной странице канала, чтобы быть в курсе новых публикаций, и подпишитесь, если ещё не подписаны! 📰