До робота-кошки – далеко. А пока ИИ останутся умными, но бесплотными “духами”

Новое исследование "Benchmarking World-Model Learning" сравнило людей и топ-модели ИИ в задачах «сначала свободно изучи мир, потом реши новую родственную задачу». Итог прост: люди несравнимо лучше строят модель мира – они целенаправленно экспериментируют, гибко пересматривают гипотезы и переносят знания. Модели же часто «застревают» в первой догадке. Главная причина – у них нет врождённых приоров и социальной стаевой педагогики.
N.B. Приоры (Priors) – это прошитые ожидания о том, как устроены объекты, причины и последствия; у животных это результат эволюции и детского опыта. У ИИ такие ожидания в основном статистические и книжные – они плохо работают в живой, изменчивой среде.
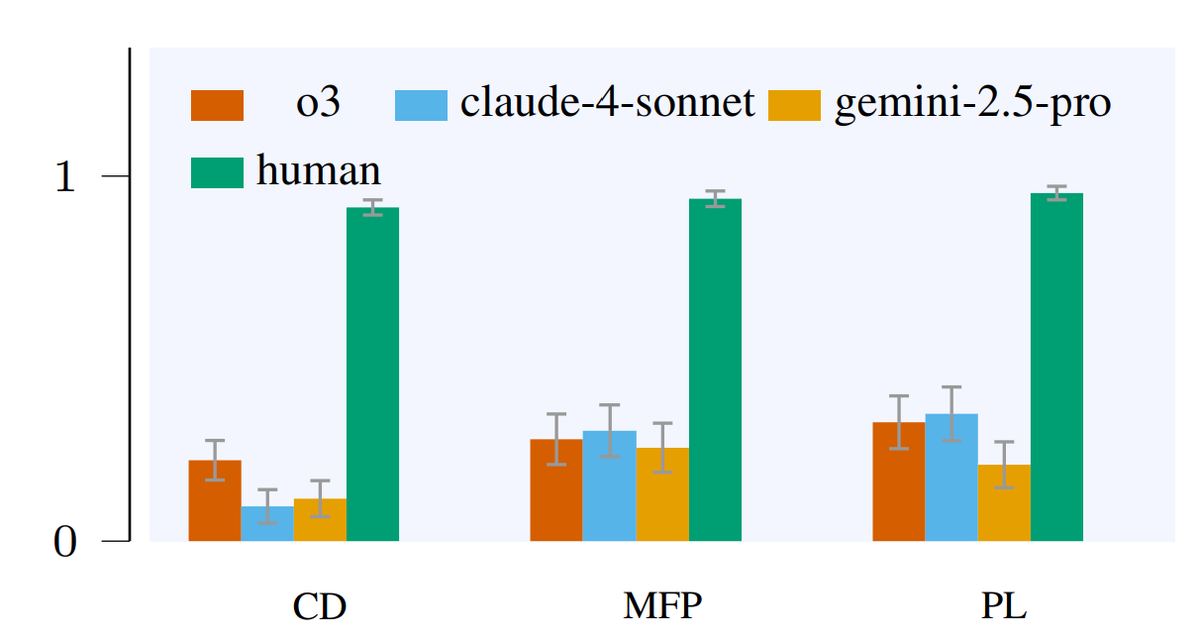
Пояснения:
Прогнозирование замаскированных кадров (MFP): Агент наблюдает траекторию с частично замаскированными кадрами и предсказывает недостающее содержимое в конечном кадре, выбирая из шести вариантов, только один из которых соответствует действительности. Агент получает оценку 1 за правильный выбор и 0 в противном случае.
Планирование (PL): Протокол задает агенту цель, которая определяет целевое состояние для подсети, и агент должен сгенерировать последовательность действий для достижения этого целевого состояния. Агент получает оценку 1 или 0 в зависимости от того, достигнет ли он целевого состояния или нет.
Обнаружение изменений (CD): Агент взаимодействует с измененной версией базовой среды, в которой динамически изменяется правило. Он должен идентифицировать временной интервал, на который запускается изменение. Агенты получают полные баллы за обнаружение изменения в нужное время; позднее обнаружение влечет за собой штрафные санкции, а выбор временного интервала до изменения приводит к нулевому результату
Можно ли «вложить» это в ИИ одним трюком?
Увы, но ответ «нет».
На сегодняшнем уровне технологий у нас нет волшебной кнопки, которая сразу даст инстинкты, безопасное исследование, долговременную память и поведенческие нормы стаи.
Но есть реалистичная дорожная карта. Она включает:
• Объектные и причинные приоры (видеть мир как набор устойчивых вещей и причинно-следственных связей).
• Внутренние мировые модели с планированием (умение «прокручивать» будущие сценарии в уме).
• Популяционное обучение с эмерджентной коммуникацией и ToM-сигналами – задачами/наградами за точное моделирование убеждений и намерений других (Theory of Mind).
• Нормативную надстройку вроде RLHF/«конституции», задающую социальные запреты и предпочтения.
Так почему же мы ещё не там?
Да потому, что самое трудное – сшить всё вместе: онлайн-обновление убеждений без “забывания”, долговременную память, телесную сенсомоторику и безопасное обучение новому – аккуратно пробуя действия, заранее оценивая риск и останавливаясь до катастрофы.
Поэтому в обозримом будущем ИИ останутся очень умными, но по сути бесплотными «духами». И до робота-кошки, сопоставимого с настоящей (мечта, близкая к цели Яна ЛеКуна), нам ещё действительно далеко.
P.S. Роботов конечно будет всё больше и больше – но без врождённых приоров и безопасной онлайновой учёбы это будут в основном хорошо дрессированные исполнители в контролируемых декорациях, а не “кошки”, которые учатся жить в мире, а не только в сценариях.
#ВоплощенныйИнтеллект #LLM