
Введение
Монолитные архитектуры долгое время были стандартом для enterprise-приложений на Java. Однако по мере роста бизнеса и усложнения требований к масштабируемости, гибкости и скорости доставки изменений, многие компании сталкиваются с необходимостью перейти от монолита к микросервисной архитектуре.
Этот процесс — не просто техническая задача, а стратегическое преобразование, требующее чёткого понимания границ домена, зависимостей и способов взаимодействия между компонентами. В этой статье мы рассмотрим популярные паттерны и подходы, которые помогут вам эффективно и безопасно разбить Java-монолит на микросервисы.
Почему стоит разбивать монолит?
Прежде чем переходить к паттернам, напомним основные причины, по которым компании начинают миграцию:
- Сложность сопровождения: огромный кодбаз, в котором сложно вносить изменения без побочных эффектов.
- Медленные сборки и деплои: даже небольшое изменение требует пересборки и перезапуска всего приложения.
- Ограниченная масштабируемость: невозможно масштабировать отдельные функции независимо.
- Технологическая инерция: сложно внедрять новые технологии или языки программирования.
Разбиение монолита — это ответ на эти вызовы. Но делать это нужно постепенно и осознанно.
1. Паттерн Фиговое дерево-душитель
Суть
Новый функционал реализуется в виде микросервисов, а старый постепенно «оборачивается» и заменяется. Запросы перенаправляются с монолита на новые сервисы через API-шлюз или прокси.
Преимущества
- Минимальный риск: монолит продолжает работать.
- Возможность поэтапной миграции.
- Нет необходимости переписывать всё сразу.
Реализация на Java
- API Gateway (например, Spring Cloud Gateway):
- По мере миграции путей в шлюзе меняются приоритеты: сначала /api/users/** направляется в монолит, затем — в новый сервис.
Совет: начинайте с малозависимых, автономных модулей (например, уведомления, отчёты).
2. Паттерн «Decompose by Business Capability» (Разбиение по бизнес-возможностям)
Суть
Приложение разбивается на микросервисы в соответствии с бизнес-доменами (например: «Управление заказами», «Каталог товаров», «Платежи»). Это подход, основанный на Domain-Driven Design (DDD).
Как применить в Java-проекте
- Проведите анализ домена с участием бизнес-аналитиков.
- Выделите ограниченные контексты (Bounded Contexts).
- Для каждого контекста создайте отдельный Spring Boot-сервис.
Пример структуры:
monolith/
├── order-management/
├── inventory/
├── user-profile/
└── payment/
→ После разбиения:
services/
├── order-service/ (Spring Boot + JPA)
├── inventory-service/ (Spring Boot + MongoDB)
├── user-service/ (Spring Boot + Spring Security)
└── payment-service/ (Spring Boot + REST client)
Важно: каждый микросервис должен иметь собственную базу данных. Избегайте общих таблиц!
3. Паттерн «Anti-Corruption Layer» (Слой защиты от коррупции)
Суть
При частичной миграции микросервисы могут вынуждены взаимодействовать с остатками монолита. Чтобы не «заразиться» его архитектурными недостатками, создаётся адаптирующий слой.
Пример на Java
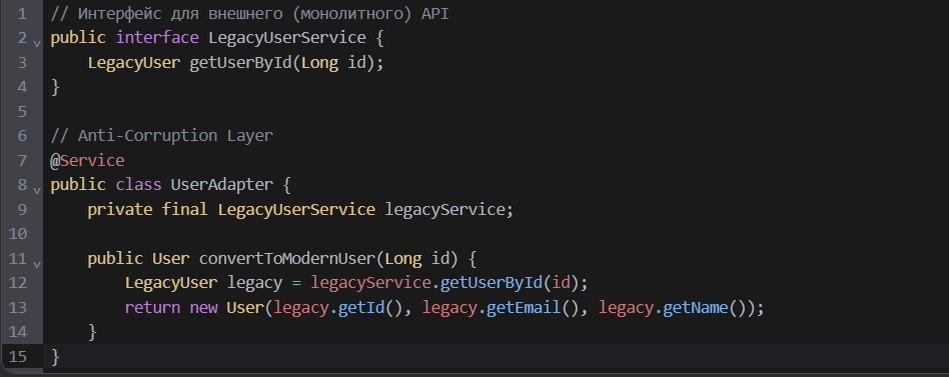
Этот слой изолирует внутреннюю модель микросервиса от устаревших структур данных.
4. Domain-Driven Design
Монолитные приложения на Java — надёжные, простые в развёртывании и отлично подходят для старта проекта. Но по мере роста бизнеса и усложнения логики они превращаются в «монстров»: медленные сборки, трудности с масштабированием, зависимые модули и страх перед рефакторингом.
Решение — переход к микросервисной архитектуре. Однако просто «разрезать» монолит на части — плохая идея. Без чёткой стратегии вы получите распределённый монолит: множество сервисов, тесно связанных через общие таблицы, синхронные вызовы и общую судьбу.
Рассмотрим Domain-Driven Design (DDD) — методология, которая помогает выявить естественные границы системы и построить микросервисы, отражающие реальную бизнес-логику.
Почему DDD — ключ к успешному разбиению?
Domain-Driven Design — это не просто набор терминов, а мышление, ориентированное на бизнес-домен. Его центральная идея: программное обеспечение должно отражать структуру и процессы предметной области.
При разбиении монолита DDD помогает ответить на главный вопрос:
«Какие части системы действительно независимы с точки зрения бизнеса?»
Без этого вы рискуете разбить приложение по техническим признакам (например, «все контроллеры», «все DAO»), что приведёт к тесной связанности и провалу микросервисной архитектуры.
Основные концепции DDD для разбиения
1. Ограниченный контекст (Bounded Context)
Это граница, внутри которой определённая модель (термины, правила, логика) имеет чёткий и однозначный смысл.
Пример: слово «Заказ» в контексте продаж означает «покупка клиентом», а в контексте логистики — «задание на доставку». Это разные модели — значит, разные контексты.
Каждый микросервис должен соответствовать одному ограниченному контексту.
2. Корневая сущность (Aggregate Root)
Группа связанных объектов, которые обрабатываются как единое целое. Транзакции и инварианты применяются на уровне агрегата.
Пример: Order — корневая сущность, а OrderLine — часть агрегата. Внешние сервисы взаимодействуют только с Order, а не напрямую с OrderLine.
Агрегаты определяют границы транзакционной целостности и помогают избежать «тонких» сервисов.
3. Язык, понятный всем (Ubiquitous Language)
Разработчики, аналитики и бизнес используют одни и те же термины. Это снижает недопонимание и помогает выявить границы контекстов.
Паттерны разбиения монолита с акцентом на DDD
1. Decompose by Bounded Context (Разбиение по ограниченному контексту)
Это основной паттерн, рекомендуемый в DDD. Вместо технического разбиения вы анализируете бизнес-процессы и выделяете автономные домены.
Как применить:
- Проведите Event Storming или Domain Storytelling с участием бизнеса.
- Найдите ключевые сущности и процессы.
- Сгруппируйте их в контексты.
- Каждый контекст → отдельный микросервис.
Пример на Java:
Допустим, у вас есть монолит интернет-магазина. После анализа выделяете контексты:
- Product Catalog — управление товарами
- Order Management — создание и обработка заказов
- Inventory — учёт остатков
- Billing — выставление счётов
Каждый становится Spring Boot-приложением:
Важно: даже если в монолите таблицы orders и products были в одной БД — в микросервисах они разделяются.