⚡️ New open models are rapidly closing the gap with closed-source heavyweights in agent tasks! In the Terminal-Bench Hard benchmark (coding & terminal agents), DeepSeek V3.2 Exp, Kimi K2 0905, and GLM-4.6 have shown significant growth—DeepSeek has already surpassed Gemini 2.5 Pro! 🚀 This means open-source models are now a legit alternative for agent scenarios and development—developers have more choices than ever! 💡 Check out the price and performance analysis of the leading providers below 👇 🟠 DeepSeek V3.2 Exp: https://artificialanalysis.ai/models/deepseek-v3-2-reasoning/providers 🟠 GLM-4.6: https://artificialanalysis.ai/models/glm-4-6-reasoning/providers 🟠 Kimi K2 0905: https://artificialanalysis.ai/models/kimi-k2-0905/providers
⚡️ New open models are rapidly closing the gap with closed-source heavyweights in agent tasks!
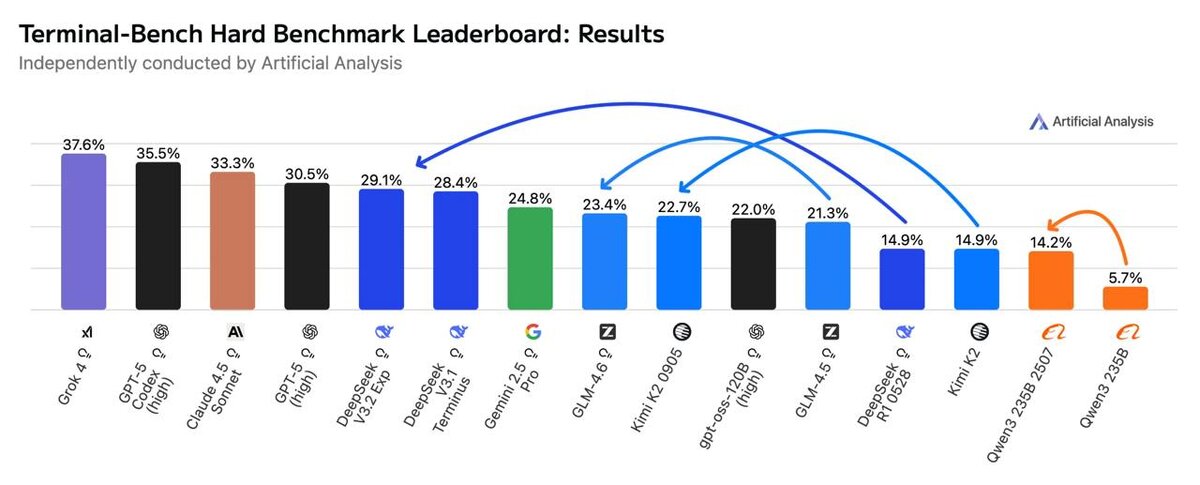
In the Terminal-Bench Hard benchmark (coding & terminal agents), DeepSeek V3.2 Exp, Kimi K2 0905, and GLM-4.6 have shown significant growth—DeepSeek has already surpassed Gemini 2.5 Pro! 🚀
This means open-source models are now a legit alternative for agent scenarios and development—developers have more choices than ever! 💡
Check out the price and performance analysis of the leading providers below 👇
🟠 DeepSeek V3.2 Exp: https://artificialanalysis.ai/models/deepseek-v3-2-reasoning/providers
🟠 GLM-4.6: https://artificialanalysis.ai/models/glm-4-6-reasoning/providers
🟠 Kimi K2 0905: https://artificialanalysis.ai/models/kimi-k2-0905/providers