Google запустила File Search для Gemini API: конец мучениям с RAG-системами?
Emilia David
6 ноября 2025
Представьте себе: вы разработчик, и перед вами стоит задача собрать RAG-систему (retrieval augmented generation — это когда AI может искать информацию в документах и давать обоснованные ответы). Звучит просто? Но на деле это кошмар: нужно связать воедино хранилище данных, генератор эмбеддингов, векторную БД, настроить всё это… Вот именно эту боль Google решила облегчить.
Что такое File Search и почему это имеет значение
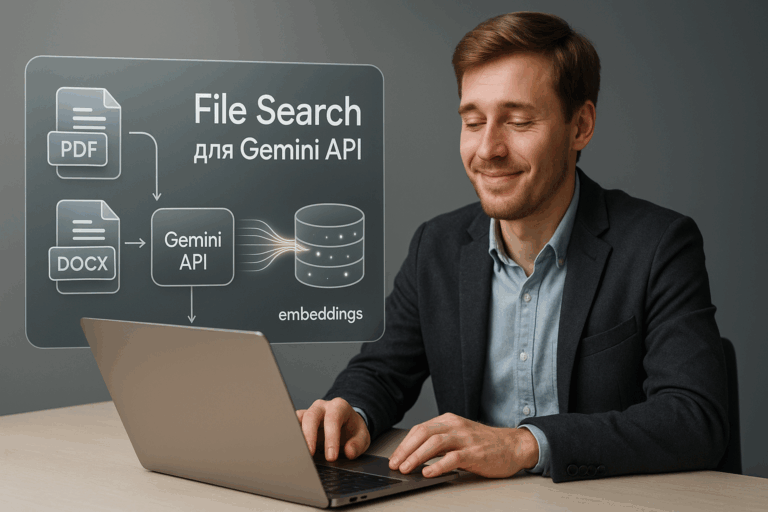
Компания выпустила File Search Tool в Gemini API — по сути, это полностью управляемая RAG-система, которая забирает у разработчиков всю рутину. Не нужно больше самостоятельно искать решения для хранения и создавать эмбеддинги — Google всё это делает за вас.
Инструмент напрямую конкурирует с предложениями OpenAI, AWS и Microsoft, которые тоже упрощают RAG-архитектуру. Но Google утверждает: их решение требует меньше настроек и работает более автономно. Звучит привлекательно, да?
«File Search предоставляет простой, интегрированный и масштабируемый способ подключить данные компании к Gemini, обеспечивая более точные, релевантные и проверяемые ответы», — сказано в блоге Google.
Сколько это стоит
Вот интересный момент: хранение и эмбеддинги при запросе — бесплатно. Платить начнёте только за индексирование файлов: 0,15 доллара за миллион токенов. По реакциям в соцсетях видно, что многие считают это смелым ходом — просто раздавать бесплатное хранилище.
В основе File Search лежит модель Gemini Embedding, которая, кстати, стала топ-моделью в бенчмарке Massive Text Embedding Benchmark. Не мелочь.
Как это на самом деле работает
Google говорит, что инструмент «берёт на себя сложность RAG». Он управляет хранением файлов, разбивает их на части (чанкинг), создаёт эмбеддинги. Разработчики могут вызвать File Search прямо внутри существующего generateContent API — это значит, что внедрить инструмент несложно.
Технически это работает так: векторный поиск помогает «понять смысл» запроса пользователя. Система находит в документах релевантную информацию, даже если в запросе используются не совсем точные слова — вот это да!
Бонус: встроенная функция цитирования показывает, из какой части документа взята информация. И поддерживаются разные форматы: PDF, Docx, txt, JSON, файлы популярных языков программирования.
Почему это облегчение, а не просто фишка
Если бы вы строили RAG-систему по старинке, пришлось бы вручную создавать программу загрузки и парсинга файлов, настраивать чанкинг, генерировать эмбеддинги и держать их в актуальном состоянии. Потом найти подходящую векторную базу (типа Pinecone), разобраться с логикой поиска, всё это втиснуть в контекстное окно модели. И да, ещё добавить источники цитирования, если захочется.
File Search делает ВСЁ это вместо вас. Другие платформы предлагают что-то похожее, но Google абстрагирует все элементы RAG-пайплайна, а не только некоторые.
Реальный пример: как это работает в жизни
Phaser Studio — создатель платформы генерации игр на AI Beam — рассказала в блоге Google о своём опыте. Они использовали File Search, чтобы работать с библиотекой из 3000 файлов. Результат? Материал находится мгновенно — будь то сниппет кода, шаблоны жанров или архитектурные рекомендации из их «корпуса знаний».
Цитата CTOPhaser Richard Davey: «Идеи, на прототипирование которых раньше уходили дни, теперь становятся работающим продуктом за минуты». Вот это мотивирует!
Людям это нравится
После анонса в соцсетях началось оживление. Один парень писал, что делает PhD и собрал тысячи PDF — ему нужно было как-то обосновать ответы с цитатами, но построить RAG-систему самому ему казалось выше его сил. И вот — идеальное решение.
Другой пользователь заметил, что Google просто так раздаёт бесплатное хранилище и эмбеддинги — это может перевернуть всю экосистему. RAG всегда был той штукой, которую «следует делать», но большинство команд либо строили кривое решение своими силами, либо вообще ничего не делали.
Один из комментариев особенно точен: «Вы по сути абстрагировали самые раздражающие 80% разработки RAG-системы. Теперь «контекстная осведомлённость» становится базовым стандартом для всех AI-приложений, а не сложным дополнением».
Что дальше
Похоже, Google серьёзно нацелена на то, чтобы сделать AI с персональными данными доступнее. Это может изменить, как компании интегрируют внутреннюю информацию в свои AI-системы. Меньше инженерной боли — больше внимания к тому, что действительно важно: логике и результатам.
Google только что сняла один из главных барьеров на пути внедрения AI в корпоративные системы. Если вам интересно следить за таким развитием событий в мире AI — это точно стоит вашего внимания.🔔 Чтобы не пропустить новости о RAG-системах, инструментах Google и других прорывах в AI, подпишитесь на канал «ProAI» в Telegram!