🔄 Обновление в среде опенсорсных AI-агентов
Китайцы из Moonshot AI выкатили Kimi K2 Thinking.
Модель позиционируется как "думающий агент". Её ключевая фича — способность выполнять сложные, многошаговые задачи, последовательно используя инструменты (поиск, код, браузер). Заявлено, что Kimi K2 может сделать 200-300 таких вызовов подряд без вмешательства человека.
То есть в задачах программирования она может:
- Декомпозировать задачу.
- Искать информацию в вебе.
- Писать код.
- Запускать и отлаживать его.
- Анализировать результат и повторять цикл до победного.
Что по качеству?
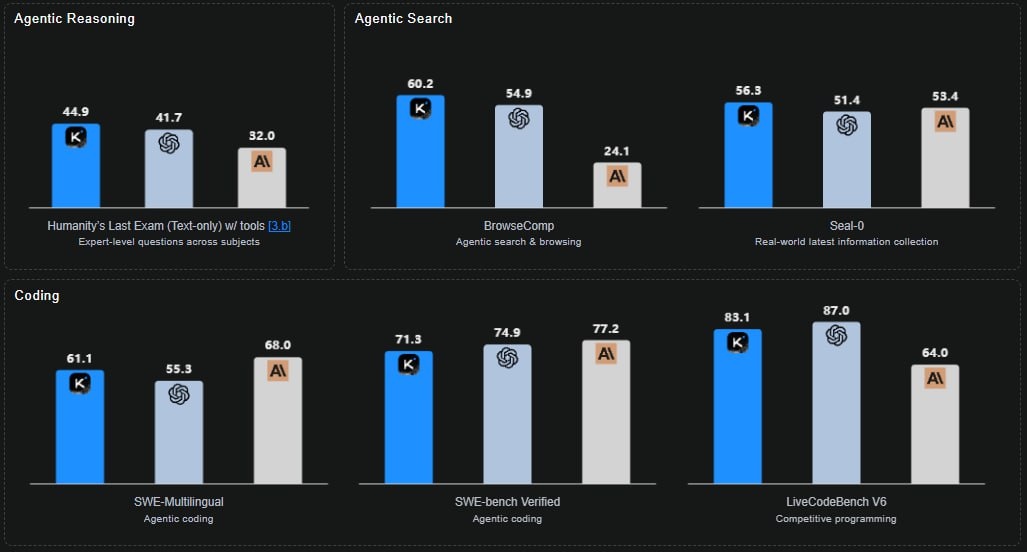
🧠 Решила математическую задачу уровня PhD за 23 шага, чередуя логические рассуждения, поиск и выполнение кода.
💻 Выбила 71.3% на SWE-Bench Verified. Это бенчмарк, где нужно решать реальные проблемы из GitHub-репозиториев. Это лучше DeepSeek-V3.2, но все же не дотягивает до GPT-5 и Claude-4.5.
🌐 Набрала 60.2% на BrowseComp (агентный поиск в вебе), где средний человек показывает всего 29.2%. Она ищет и анализирует информацию лучше людей.
По сути, мы наблюдаем смещение фокуса с "генераторов текста" на "агентов-исполнителей". Система сама декомпозирует проблему, ищет информацию, пишет и выполняет код, анализирует результаты и корректирует свой план: think → search → browser use → think → code
Веса лежат на Hugging Face ◀️
Попробовать можно в чате (но самый вкусный функционал ограничен подпиской) ◀️
#годный_опенсорс