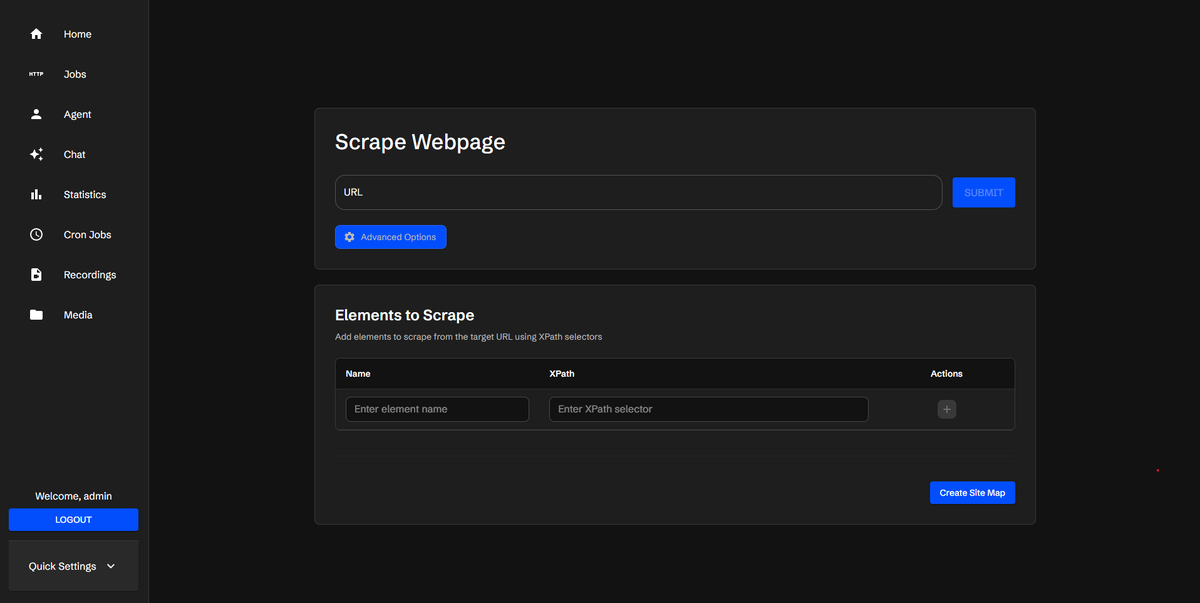
Scraperr — это современный инструмент для извлечения данных с веб-сайтов, не требующий навыков программирования. Он позволяет собирать контент с любых страниц, визуализировать результаты и экспортировать их в удобные форматы. Проект распространяется по лицензии MIT и может быть развернут на собственном сервере через Docker.
Основные возможности
* XPath-навигация: позволяет точно указывать элементы страниц, которые нужно собрать.
* Управление заданиями: добавление URL-адресов, запуск, остановка и контроль выполнения задач.
* Сканирование домена: сбор данных со всех страниц в пределах одного сайта.
* Кастомные заголовки: возможность добавления собственных HTTP-headers для обхода ограничений.
* Загрузка медиа: автоматическое скачивание изображений, видео и документов.
* Визуализация и экспорт: просмотр результатов в таблице и экспорт в CSV или Markdown.
* Уведомления: оповещения о завершении задач через различные каналы.
Преимущества Scraperr
* Без кода: настройка скрапинга осуществляется через веб-интерфейс.
* Самостоятельный хостинг: полная автономность — разворачивается на вашем сервере.
* Гибкость: поддержка прокси, заголовков, ограничений и расписаний.
* Простота установки: готовые Docker-файлы и Makefile для быстрой настройки.
* Современный стек: FastAPI (бэкенд), MongoDB (база данных), Next.js + Tailwind (интерфейс).
Технические особенности
* Бэкенд: FastAPI, фронтенд: Next.js, хранилище: MongoDB.
* Возможность развертывания в Docker или Kubernetes.
* Поддержка кастомных прокси и таймаутов для безопасного скрапинга.
* Открытый исходный код и регулярные обновления на GitHub.
Этическое использование
Разработчик подчёркивает, что Scraperr следует применять только для сайтов, разрешающих скрапинг, в соответствии с их политикой и правилами (robots.txt, Terms of Use). Инструмент предназначен для исследовательских, аналитических и внутренних задач.
Применение Scraperr
* Сбор данных для аналитики и исследований.
* Мониторинг изменений на сайтах.
* Архивация изображений, документов и других медиа.
* Формирование собственных баз данных контента.
⬇️Поддержать автора⬇️
✅SBER: 2202 2050 7215 4401