Python предоставляет мощные инструменты для обработки данных, особенно в области управления структурами данных, такими как списки и словари. Одной из часто встречающихся задач является подсчет количества повторяющихся элементов в списке. Для этого удобно использовать словарь dict, который позволяет хранить уникальные элементы списка вместе с количеством их появлений.
Ручной подсчёт элементов в словаре Python
Самый простой способ подсчета уникальных значений в списке заключается в ручном проходе по списку и заполнению словаря вручную. Рассмотрим пример реализации:
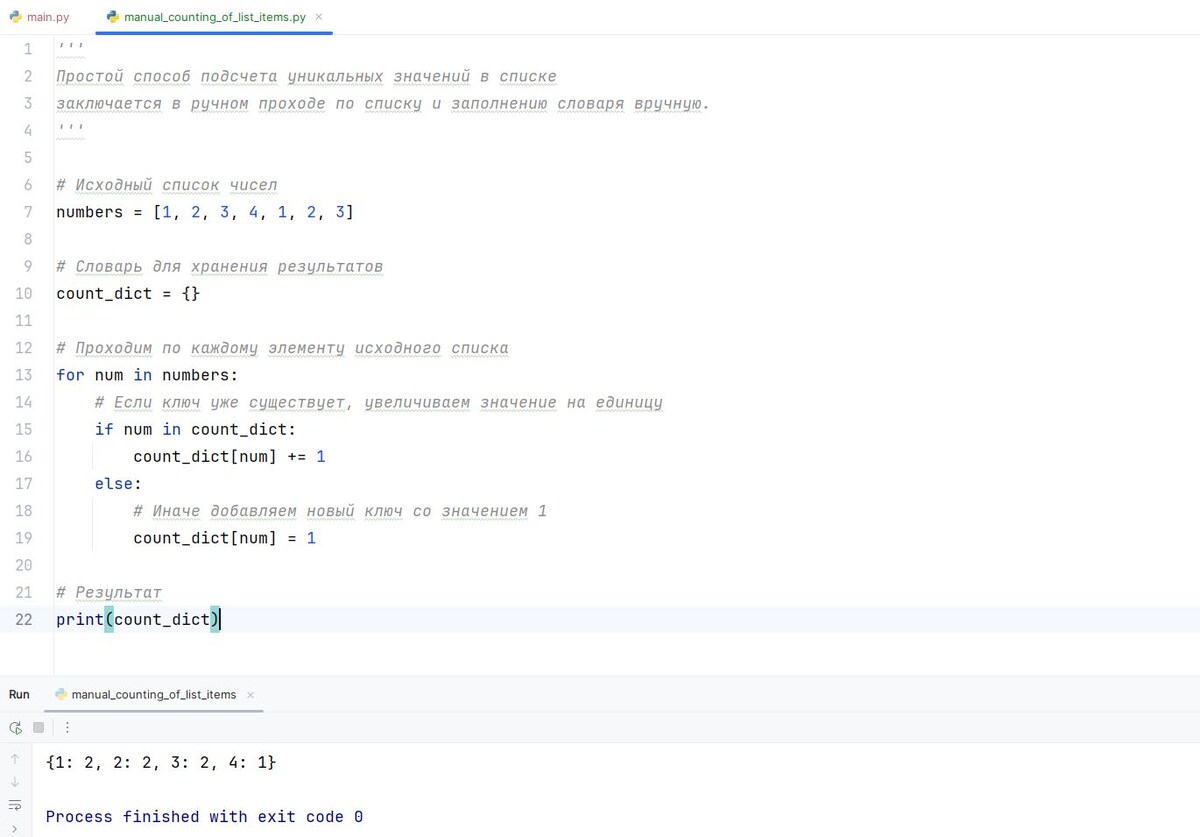
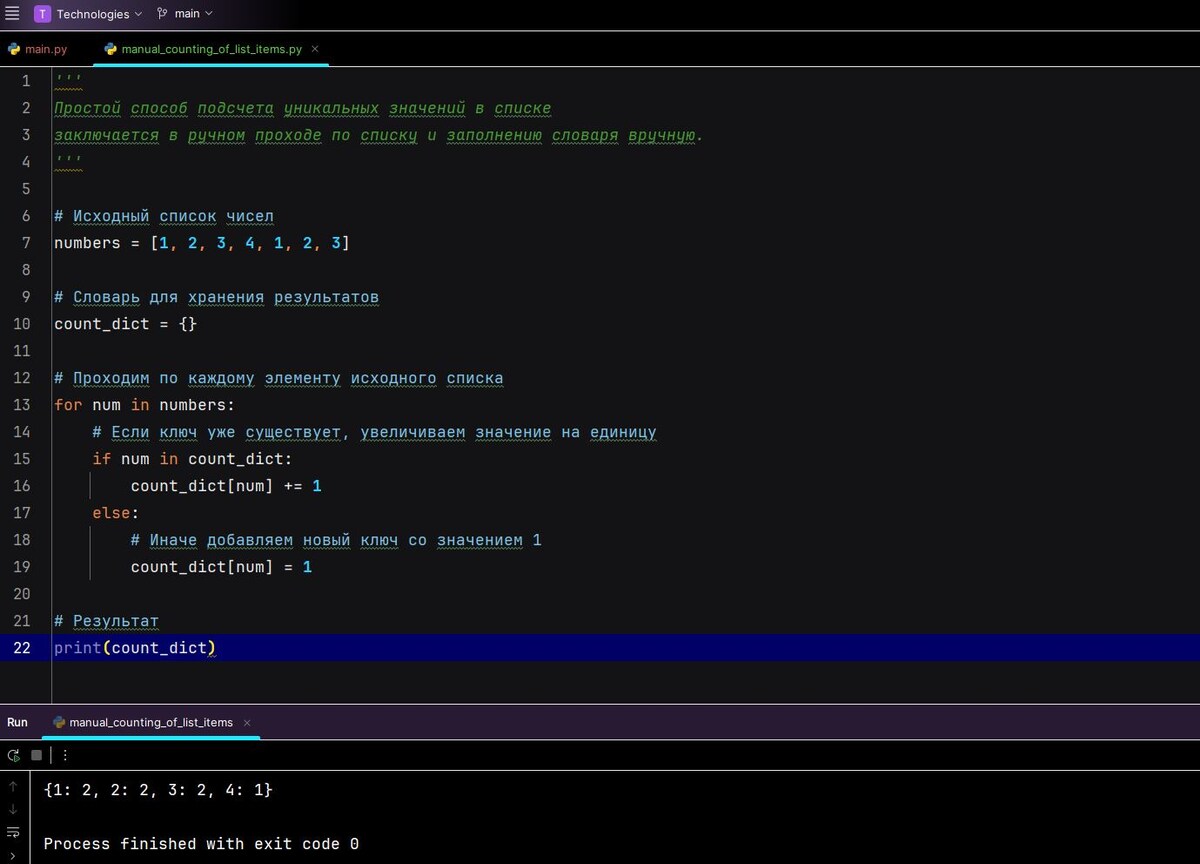
Результат: {1: 2, 2: 2, 3: 2, 4: 1}
Как работает этот код?
- Мы инициализируем пустой словарь count_dict, который будет содержать ключи (числа из списка) и значения (количество повторений).
- Затем мы проходим по каждому числу в списке и проверяем наличие ключа в словаре.
- Если число уже было ранее обработано, увеличивается счётчик.
- Если число новое, оно добавляется в словарь с начальным значением 1.
Этот метод достаточно прост и понятен, однако он требует дополнительной проверки наличия элемента в словаре каждый раз, что немного снижает производительность.
Оптимизация программы с использованием метода .setdefault()
Чтобы избежать проверки наличия ключа в словаре каждый раз, можно воспользоваться методом .setdefault() словарей. Этот метод возвращает значение по указанному ключу, а если ключ отсутствует, добавляет его в словарь с указанным значением по умолчанию.
Рассмотрим оптимизированный вариант предыдущего примера:
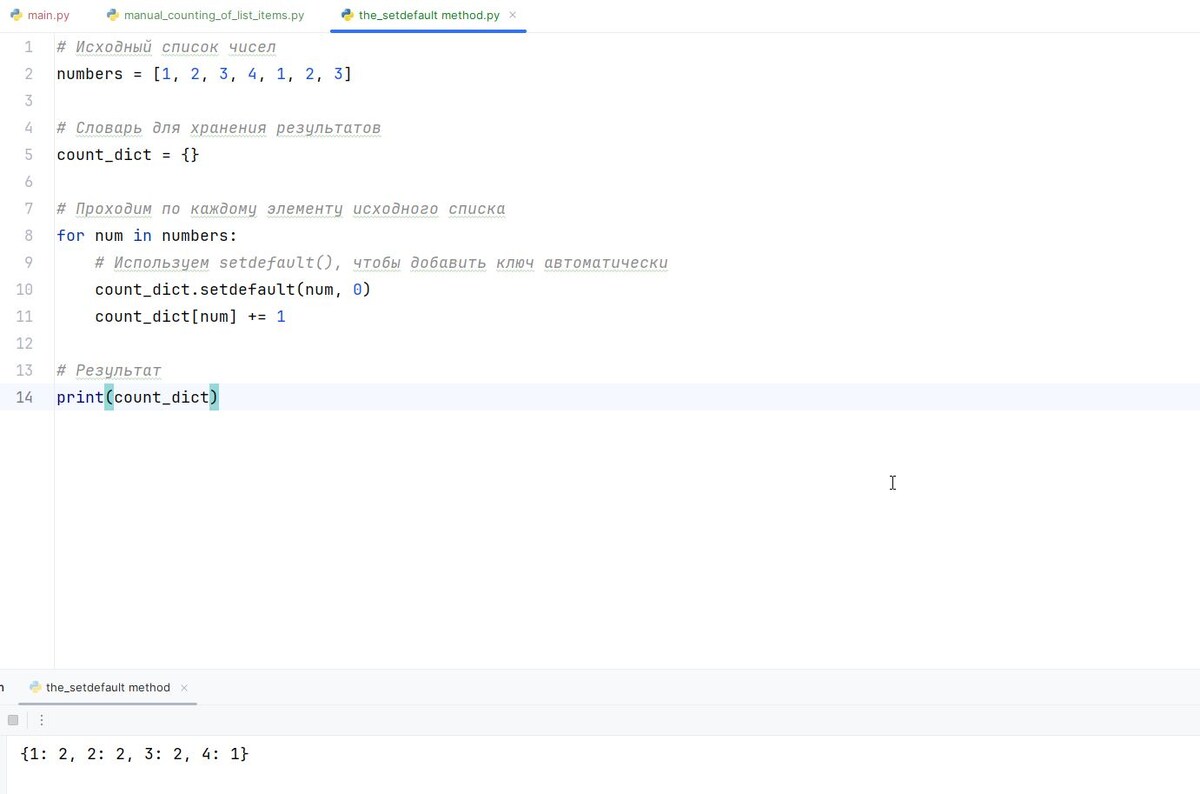
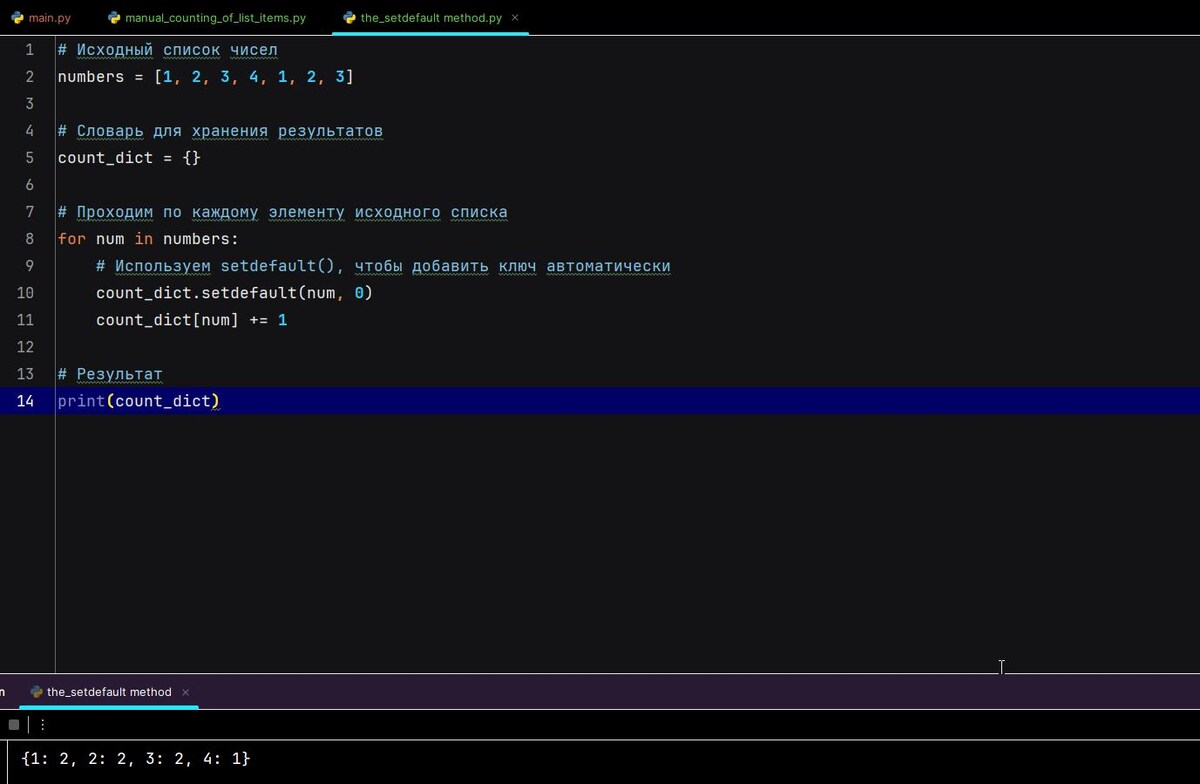
Результат: {1: 2, 2: 2, 3: 2, 4: 1}
Преимущества использования .setdefault()
Метод .setdefault() упрощает код и избавляет от отдельной проверки существования ключа. Теперь нам не нужно писать условие if key in dict.
Использование класса collections.Counter для подсчета элементов последовательности
Стандартная библиотека Python включает модуль collections, содержащий класс Counter. Это специализированный объект, предназначенный именно для подсчета элементов последовательности. Он существенно упрощает процесс подсчета частот появления элементов.
Пример использования:
Результат: {1: 2, 2: 2, 3: 2, 4: 1}
Почему стоит выбрать Counter?
- Класс Counter разработан специально для решения задач подобного типа, и он реализует многие полезные методы.
- Код становится значительно короче и проще читается.
- Можно легко получать наиболее частые элементы с помощью методов вроде most_common().
Заключение
Подсчет частоты элементов в списке — задача, которую приходится решать практически ежедневно при работе с большими объемами данных. Понимание особенностей работы словарей в Python помогает выбирать оптимальный путь решения проблемы.
Мы рассмотрели три подхода:
1. Простой цикл: Проверка ключей вручную.
2. Использование .setdefault(): Автоматическое создание новых ключей.
3. Класс Counter: Специализированный инструмент из стандартной библиотеки.
Каждый из подходов имеет свои преимущества и недостатки, выбор зависит от конкретной ситуации и предпочтений разработчика. Важно помнить, что понимание основ структуры данных позволит быстрее находить эффективные решения повседневных задач программирования.