
Цель и необходимость
Как
только я решил свои мысли записывать на какой-то внешний носитель, так я
сразу начал осознавать проблему поиска в этих записях. Для дальнейшей
работы нам необходимо дать несколько определений:
- Морфологический поиск связан
с учётом различных форм слов при поиске. Есть два подхода: либо
учитывать все формы, либо вырезать корень слова и искать только по нему.
Второй способ называется stemming, он отличается быстротой и простотой,
но имеет проблемы со словами, у которых корень изменчив (бег — бежать,
расти — прирост, лев — львица). - Семантический поиск —
способ и технология поиска информации, основанная на использовании
контекстного (смыслового) значения запрашиваемых фраз, вместо словарных
значений отдельных слов или выражений при поисковом запросе.
Некоторые особенности семантического поиска:
- Учитывается
информационный контекст, местонахождение и цель поиска пользователя,
словесные вариации, синонимы, обобщённые и специализированные запросы,
язык запроса и другие особенности. - Цель такого поиска — определять особенности пользователя и предоставлять ему наиболее релевантные результаты.
- Ряд
крупных поисковых систем, например Google и Bing, используют некоторые
элементы семантического поиска, но не являются таковыми в чистом виде.
Эмбеддинги (embeddings) —
это численные представления текста или слов в виде векторов, которые
отражают их семантическое значение. В контексте семантического поиска,
эмбеддинги используются для преобразования текста запроса и документов в
числовой формат, который можно анализировать на наличие схожести по
смыслу.
- Семантический
поиск использует эмбеддинги для сравнения семантической близости между
запросом пользователя и документами. Если эмбеддинг запроса близок к
эмбеддингу документа, это означает, что оба имеют схожий смысл. - Эмбеддинги
позволяют системе понимать не только отдельные слова, но и контекст,
что делает семантический поиск более умным и точным по сравнению с
традиционными методами поиска (морфологический поиск).
Морфологический поиск —
часть процесса семантического поиска, связанный с обработкой
лингвистических особенностей запросов. Чаще всего системы предлагают
поиск по вхождению символов в текст документов, а это может вести к не
полным результатам поиска. Проблема становится актуальной, когда
документов много, как и текста в них. На данный момент у меня в базе
знаний более 2800 файлов и искать становится все сложнее и сложнее.
3. LLM (Large Language Model) — это一большая языковая модель,
обученная на огромных объемах текстовых данных. Эти модели способны
понимать и генерировать человеческий язык, а также выполнять задачи
обработки естественного языка (NLP — Natural Language Processing).
С
течением времени при работе с базой знаний начал замечать, что все чаше
и чаще хочется обобщать большие тексты. Конечно же я начал некоторые
тексты выгружать в публичные LLM. Но параллельно начал осознавать, что
такие выгрузки нарушают приватность моей жизни.
В итоге какие проблемы имеем:
- Поиск и возможность искать по смыслу.
- Приватность
производимых операций. Лично для меня выходом стало появление LLM,
которые возможно свободно скачивать, устанавливать и использовать в
своих проектах.
В статье будем устанавливать LLM на сервер и давать возможность нашим сервисам взаимодействовать с ней.
Virtual machine
Я использую VM в
proxmox, в настройках которой уже добавления видеокарта. Установку
драйверов NVIDIA не описываю, так как это описано в соответствующей
статье (см. ссылки в самом низу). Помимо этого необходимо процессор VM
указать как host. Важным в данном контексте для нас является поддержка Advanced Vector Extensions (AVX), так как позволяет быстрее обрабатывать данные в рамках GPU. Проверить поддержку AVX возможно (вывод должен быть как в тексте ниже):
$ grep avx /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm rep_good nopl cpuid extd_apicid tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy svm cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw perfctr_core ssbd ibpb vmmcall fsgsbase tsc_adjust bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 clzero xsaveerptr virt_ssbd arat npt lbrv nrip_save tsc_scale vmcb_clean flushbyasid pausefilter pfthreshold v_vmsave_vmload vgif overflow_recov succor arch_capabilities
.....
doсker-compose
Для начала нам необходимо нарисовать архитектуру docker-compose.yml сервисов и работу с нашим оборудованием, чтобы понимать на верхнем уровне:
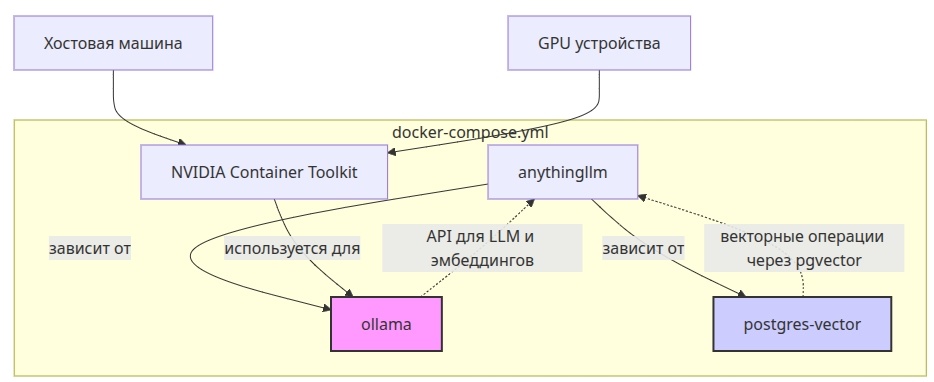
Диаграмма показывает основные компоненты системы:
- Для корректной работы сервисов ollama требуется:Установленный NVIDIA Container Toolkit на хостовой машине
Драйверы NVIDIA и GPU-устройства
Теперь мы готовы создать файлы для запуска docker-compose.yml:
- touch .env docker-compose.yml Dockerfile init-vector.sql
- mkdir config_{anythingllm,ollama,postgres}
Содержимое .env (переменные с секретами):
POSTGRES_DB=<your database name>
POSTGRES_USER=<your vector user>
POSTGRES_PASSWORD=<your postgres password>
POSTGRES_PORT=<tyour postgres port>
JWT_SECRET=<your jwt secret>
Содержимое Dockerfile (сборка postgres с расширением pgvector):
FROM postgres:17-bookworm
# Устанавливаем необходимые пакеты
RUN apt-get update && apt-get install -y \
build-essential \
cmake \
git \
postgresql-server-dev-17 \
&& rm -rf /var/lib/apt/lists/*
# Клонируем и устанавливаем pgvector
RUN git clone https://github.com/pgvector/pgvector.git \
&& cd pgvector \
&& make DISABLE_JIT=1 \
&& make install \
&& cd .. \
&& rm -rf pgvector
# Создаем директорию для скриптов инициализации
RUN mkdir -p /docker-entrypoint-initdb.d
# Копируем скрипт инициализации
COPY init-vector.sql /docker-entrypoint-initdb.d/
EXPOSE 5432
CMD ["postgres"]
Содержимое init-vector.sql (установка расширения pgvector):
-- Включаем расширение pgvector
CREATE EXTENSION IF NOT EXISTS vector;
-- Настройки для лучшей производительности векторов
ALTER SYSTEM SET shared_preload_libraries = 'vector';
ALTER SYSTEM SET max_connections = 200;
ALTER SYSTEM SET shared_buffers = '1GB';
ALTER SYSTEM SET work_mem = '50MB';
-- Перезагрузите конфигурацию
SELECT pg_reload_conf();
Содержимое docker-compose.yml:
services:
ollama:
image: ollama/ollama:latest
container_name: llm
restart: unless-stopped
volumes:
- ./config_ollama:/root
environment:
- OLLAMA_KEEP_ALIVE=60 minutes
- OLLAMA_FLASH_ATTENTION=1
- OLLAMA_HOST=0.0.0.0
- LD_LIBRARY_PATH=/opt/cuda/lib64:/usr/local/cuda/lib64
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=all
- CUDADIR=/usr/local/cuda
- CUDA_HOME=/usr/local/cuda
- FORCE_CUDA=1
- CUDA_VISIBLE_DEVICES=0
- CUDA_LAUNCH_BLOCKING=1
ports:
- "11434:11434"
devices:
- /dev/dri:/dev/dri
- /dev/nvidiactl:/dev/nvidiactl
- /dev/nvidia0:/dev/nvidia0
runtime: nvidia
postgres-vector:
build:
context: .
dockerfile: Dockerfile
container_name: postgres-vector
restart: unless-stopped
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- ./config_postgres:/var/lib/postgresql/data
env_file: .env
ports:
- "${POSTGRES_PORT:-5432}:5432"
anythingllm:
image: mintplexlabs/anythingllm:latest
container_name: anythingllm
restart: unless-stopped
ports:
- "3001:3001"
environment:
- STORAGE_DIR=/app/server/storage
- LLM_PROVIDER=ollama
- OLLAMA_BASE_PATH=http://ollama:11434
- OLLAMA_MODEL_PREF=deepseek-r1:14b
- OLLAMA_MODEL_TOKEN_LIMIT=4096
- EMBEDDING_ENGINE=ollama
- EMBEDDING_BASE_PATH=http://ollama:11434
- EMBEDDING_MODEL_PREF=bge-m3:latest
- EMBEDDING_MODEL_MAX_CHUNK_LENGTH=8192
- JWT_SECRET=${JWT_SECRET}
# Аудио функции
- WHISPER_PROVIDER=local
- TTS_PROVIDER=native
# Векторная база данных - PostgreSQL с pgvector
- VECTOR_DB=pgvector
- PGVECTOR_CONNECTION_STRING=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@postgres-vector:${POSTGRES_PORT}/${POSTGRES_DB}
- PGVECTOR_TABLE_NAME=vector_embeddings
- PGVECTOR_EMBEDDING_DIMENSION=1536
# Дополнительные настройки PostgreSQL
- PGVECTOR_SSL=false
- PGVECTOR_SCHEMA=public
env_file: .env
volumes:
- ./config_anythingllm:/app/server/storage
depends_on:
- ollama
- postgres-vector
Сначала запускаем только ollama: docker-compose up -d ollama и проверяем какие модели доступны: docker exec -it llm ollama list. В самом начале должен быть пустой список, но мы можем это легко исправить:
Дополнительный вариант модели с большей производительностью.
Умный дом
Для интеграции с умным домом (Homeassistant):
- Настройки -> Устройства и службы -> Добавить интеграцию -> Набираем ollama -> Вставляем адрес http://<your local API>:11434 -> Выбираем модель qwen3:8b (downloaded).
- Настройки
-> Голосовые ассистенты -> Ассистенты -> Добавить ассистента
-> Добавляем Ollama Conversation и делаем его предпочитаемым через 3
точки возле названия ассистента.
- Настройки
-> Голосовые ассистенты -> Доступ к объектам ->
Проверяем/Смотрим какие у нас есть возможности, при необходимости
редактируем. Теперь через значок диалога в верхнем правом углу основного
интерфейса вызываем диалог и проверяем как все работает.
Остался 1 шаг до своего голосового ассистента :)
Браузер
Для работы с локальной LLM прямо в браузере (Mozilla Firefox) устанавливаем page-assist. Идем в настройки расширения и добавляем адрес для работы: Начинаем чат:
IDE
Лично я использую VSCode, поэтому все настройки далее будут для этой IDE. Устанавливаем расширение Continue :
code --install-extension Continue.continue
Вставляю настройки ~/.continue/config.yaml:
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: deepseek-r1:8b
provider: openai
model: deepseek-r1:8b
apiBase: http://<your address>/v1
apiKey: "sk-no-key-needed"
temperature: 0.7
maxTokens: 2048
contextWindow: 8192
forcePrompt: true
- name: deepseek-r1:14b
provider: openai
model: deepseek-r1:14b
apiBase: http://<your address>/v1
apiKey: "sk-no-key-needed"
temperature: 0.7
maxTokens: 2048
contextWindow: 8192
forcePrompt: true
assistant:
- name: deepseek-r1:8b
models:
- deepseek
- name: deepseek-r1:14b
models:
- deepseek
allowAnonymousTelemetry: false
tabAutocompleteModel:
title: deepseek-r1:8b
provider: openai
model: deepseek-r1:8b
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
Проверяем работу:
Obsidian
Ищем в community plugins Copilot. Действия:
- Переходим
в модели и добавляем модель в «Chat Models» (deepseek-r1:8b и
deepseek-r1:14b) и «Embedding Models» (ollama_bge-m3). Сам процесс
добавления моделей похож на добавление моделей в другие сервисы выше,
поэтому этот процесс не описываю. - Как
выяснилось моя база знаний не подходит для локальной векторризации,
которая существует в этом плагине. Там важно, что в случае деление на
партиции (для больших объемов данных), необходимо чтобы первая партиция
была не более 500 мб. При различных комбинациях у меня не удалось этого
достичь. В итоге я пользуюсь внутри obsidian только чатом и возможностью
добавлять в контекст конкретную заметку. Для ускорения работы
сделал/изменил шаблоны промтов, которые вызываются через /.
Anythingllm
После запуска docker-compose зайти в интерфейс возможно через http://<your_ip>:3001.
Все необходимые настройки уже должны примениться. Первым делом нам
необходимо проиндексировать нашу базу знаний и перевести ее в векторный
вид, чтобы далее возможно было проводить с этими векторами операции.
Нюанс индексирования таков, что файлы добавляются только и это
становится причиной появления «дубликатов». Для себя делаю выгрузки
только с новыми файлами или измененными, далее планирую удалять все
файлы и заново их индексировать, чтобы актуализировать информацию. Сама
операция индексации заняла у меня несколько дней.
Open
settings -> Agent Skills -> Добавляем навыки. Рекомендую добавить
web-search (минимум), чтобы наша LLM могла искать информацию в
Интернете.
Теперь можем искать в нашей базе знаний и при необходимости в интернете.
Итог
Теперь
у нас во всех наших инструментах есть доступ к локальной модели LLM и
мы можем это использовать в своей работе и жизни в частности.
Ссылки:
- Как запустить свою базу знаний?
- Как запустить прокси-сервер для сервисов?
- Как установить Docker?
- Как установить Proxmox?
- Как запустить прокси-сервер для сервисов?
- Как установить драйвера NVIDIA в Linux?
- Как запустить сервис по управлению умным домом?