Для чего нужна данная статья?:
Создать фреймворк для построения асинхронных конвейеров обработки данных с поддержкой параллельных вычислений, состоящие из независимых узлов (nodes), которые обмениваются
данными через асинхронные каналы. Каждый узел выполняет специфическую задачу и может работать параллельно с другими узлами.
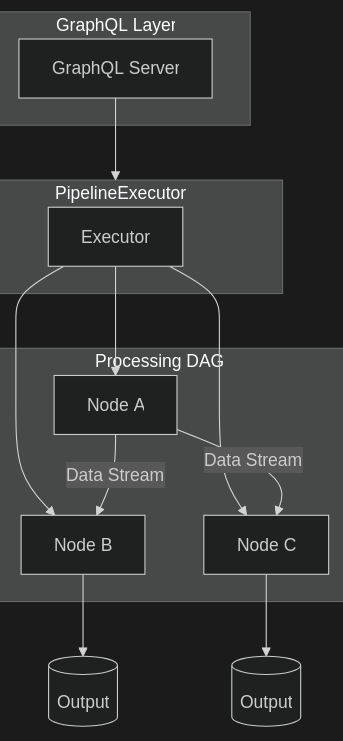
Архитектура
Основные концепции
- Узлы (Nodes) - независимые компоненты обработки
- Каналы (Channels) - асинхронные каналы для передачи данных
- Конвейер (Pipeline) - последовательность соединенных узлов
- Исполнитель (Executor) - управляет выполнением конвейера
Поток данных
[Node A] --(channel)--> [Node B] --(channel)--> [Node C]
Каждый узел:
- Получает данные через входной канал
- Обрабатывает данные
- Отправляет результаты через выходной канал
Компоненты системы
1. Типы данных (data.rs)
pub enum Data {
FilePath(PathBuf), // Путь к файлу
FileHash(PathBuf, String), // Путь и хеш файла
}
2. Система ошибок (error.rs)
pub enum NodeError {
Io(std::io::Error), // Ошибки ввода-вывода
ChannelError, // Ошибки каналов
Config(String), // Ошибки конфигурации
}
3. Базовый трейт узла (node.rs)
#[async_trait]
pub trait Node: Send + Sync {
async fn process(
&mut self,
input: mpsc::Receiver<Data>,
output: mpsc::Sender<Data>,
) -> Result<(), NodeError>;
}
4. Узлы обработки
ParallelMd5Node (md5_node.rs)
Вычисляет MD5 хеши файлов с использованием параллельных вычислений.
Особенности:
- Параллельная обработка батчами
- Настраиваемый уровень параллелизма
- Ленивая инициализация пула потоков
Конфигурация:
- parallelism: количество потоков для вычислений
- batch_size: размер батча (по умолчанию 10)
FileDiscoverNode
Обходит файловую систему и находит файлы для обработки.
5. Исполнитель конвейера (executor.rs)
Управляет жизненным циклом конвейера.
Основные функции:
- Регистрация узлов
- Соединение узлов
- Запуск и остановка конвейера
- Управление ресурсами
Добавление зависимостей
toml
[dependencies]
tokio = { version = "1.0", features = ["full"] }
async-trait = "0.1.0"
rayon = "1.5"
md5 = "0.7"
tokio-stream = "0.1"
Использование
Базовый пример
use pipeline::{
PipelineExecutor,
ParallelMd5Node,
FileDiscoverNode
};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let mut executor = PipelineExecutor::new();
// Регистрация узлов
executor
.add_node("discover".to_string(), 0, 1)
.add_node("md5".to_string(), 1, 1);
// Добавление реализаций узлов
executor
.add_node_instance(
"discover".to_string(),
FileDiscoverNode::new("/path/to/files".into())
)
.add_node_instance(
"md5".to_string(),
ParallelMd5Node::new(4) // 4 потока
);
// Соединение узлов
executor.connect("discover", 0, "md5", 0)?;
// Запуск конвейера
executor.execute().await?;
executor.wait_for_completion().await?;
Ok(())
}
Расширенный пример с несколькими узлами
let mut executor = PipelineExecutor::new();
// Создание сложного конвейера
executor
.add_node("discover".to_string(), 0, 1)
.add_node("filter".to_string(), 1, 1)
.add_node("md5".to_string(), 1, 1)
.add_node("aggregator".to_string(), 1, 0);
// Соединение узлов в цепочку
executor
.connect("discover", 0, "filter", 0)?
.connect("filter", 0, "md5", 0)?
.connect("md5", 0, "aggregator", 0)?;
API Reference
PipelineExecutor
Методы
new() - Создает новый исполнитель
add_node(id, input_ports, output_ports) - Регистрирует узел
add_node_instance(id, node) - Добавляет реализацию узла
connect(from_node, from_port, to_node, to_port) - Соединяет узлы
execute() - Запускает конвейер (асинхронный)
wait_for_completion() - Ожидает завершения (асинхронный)
shutdown() - Аварийная остановка (асинхронный)
ParallelMd5Node
Методы
new(parallelism) - Создает узел с указанным параллелизмом
Параметры
- parallelism: количество рабочих потоков (рекомендуется: количество ядер CPU)
Реализация трейта Node
use async_trait::async_trait;
use tokio::sync::mpsc;
struct CustomNode;
#[async_trait]
impl Node for CustomNode {
async fn process(
&mut self,
input: mpsc::Receiver<Data>,
output: mpsc::Sender<Data>,
) -> Result<(), NodeError> {
// Реализация обработки
while let Some(data) = input.recv().await {
// Обработка данных
let result = process_data(data).await?;
output.send(result).await?;
}
Ok(())
}
}
Примеры
Обработка файлов с фильтрацией
// Создание узла для фильтрации по расширению
struct FileFilterNode {
extensions: Vec<String>,
}
#[async_trait]
impl Node for FileFilterNode {
async fn process(
&mut self,
input: mpsc::Receiver<Data>,
output: mpsc::Sender<Data>,
) -> Result<(), NodeError> {
let mut input_stream = ReceiverStream::new(input);
while let Some(data) = input_stream.next().await {
if let Data::FilePath(path) = &data {
if let Some(ext) = path.extension() {
if self.extensions.contains(&ext.to_string_lossy().to_string()) {
output.send(data).await?;
}
}
}
}
Ok(())
}
}
Агрегация результатов
struct StatsAggregator {
results: HashMap<PathBuf, String>,
}
#[async_trait]
impl Node for StatsAggregator {
async fn process(
&mut self,
input: mpsc::Receiver<Data>,
_output: mpsc::Sender<Data>,
) -> Result<(), NodeError> {
let mut input_stream = ReceiverStream::new(input);
while let Some(data) = input_stream.next().await {
if let Data::FileHash(path, hash) = data {
self.results.insert(path, hash);
}
}
// Вывод статистики
println!("Обработано файлов: {}", self.results.len());
Ok(())
}
}
Производительность
Рекомендации по настройке
- Параллелизм MD5 узла:
Устанавливайте равным количеству физических ядер CPU
Для IO-интенсивных workloads можно увеличить - Размер батча:
Оптимальный размер: 10-100 элементов
Большие батчи уменьшают накладные расходы, но увеличивают latency - Размер буфера каналов:
По умолчанию: 100 элементов
Увеличивайте при высокой скорости производства данных
Мониторинг производительности
// Добавление метрик
struct MonitoredNode<T: Node> {
inner: T,
processed_count: AtomicUsize,
start_time: Instant,
}
impl<T: Node> Node for MonitoredNode<T> {
async fn process(&mut self, input: mpsc::Receiver<Data>, output: mpsc::Sender<Data>) -> Result<(), NodeError> {
let result = self.inner.process(input, output).await;
let duration = self.start_time.elapsed();
let count = self.processed_count.load(Ordering::Relaxed);
println!("Node processed {} items in {:?}", count, duration);
result
}
}
Расширение системы
Добавление новых типов данных
// В data.rs
#[derive(Debug, Clone)]
pub enum Data {
FilePath(PathBuf),
FileHash(PathBuf, String),
FileMetadata(PathBuf, Metadata), // Новый тип данных
ProcessingResult(String, Vec<u8>),
}
Создание специализированных узлов
Узел для обработки изображений
struct ImageProcessingNode {
operations: Vec<ImageOperation>,
}
#[async_trait]
impl Node for ImageProcessingNode {
async fn process(
&mut self,
input: mpsc::Receiver<Data>,
output: mpsc::Sender<Data>,
) -> Result<(), NodeError> {
// Реализация обработки изображений
Ok(())
}
}
Узел для работы с сетью
struct HttpDownloadNode {
client: reqwest::Client,
base_url: String,
}
#[async_trait]
impl Node for HttpDownloadNode {
async fn process(
&mut self,
input: mpsc::Receiver<Data>,
output: mpsc::Sender<Data>,
) -> Result<(), NodeError> {
// Реализация загрузки по HTTP
Ok(())
}
}
Кастомизация исполнителя
struct AdvancedPipelineExecutor {
base: PipelineExecutor,
metrics: MetricsCollector,
health_check: HealthChecker,
}
impl AdvancedPipelineExecutor {
pub async fn execute_with_monitoring(&mut self) -> Result<(), NodeError> {
self.metrics.start_collection();
self.base.execute().await?;
self.health_check.start();
Ok(())
}
}
Отладка и логирование
Встроенная диагностика
Фреймворк предоставляет детальное логирование:
// Включение детального логирования
RUST_LOG=debug cargo run
// Логирование конкретных модулей
RUST_LOG=pipeline=info,md5_node=debug cargo run
Советы по отладке
- Проверка соединений узлов: Используйте executor.validate() перед запуском
- Мониторинг deadlocks: Добавляйте таймауты в каналы
- Профилирование памяти: Используйте heaptrack или valgrind
Безопасность
Рекомендации
- Валидация входных данных: Всегда проверяйте входные пути
- Ограничение прав доступа: Запускайте с минимальными привилегиями
- Лимитирование ресурсов: Устанавливайте лимиты на использование памяти и CPU