Продолжаю дальше разбираться с обработкой естественных языков (NLP) и большими языковыми моделями (LLM). Вчера на цепях Маркова сделал простенького чат-бота, который выдаёт советы по умному дому вперемешку с анекдотами. 🙂
Что за цепи такие?
Цепи Маркова — это простая статистическая модель, которая предсказывает следующее слово на основе предыдущих.
Я обучил бота на анекдотах и сообщениях из чатов по Home Assistant и
теперь бот знает, что после «умный» часто идёт слово «дом», а после
«армянское» — «радио». Поэтому если задать такому боту вопрос про «Home
Assistant, то он просто попытается продолжить предложение, используя
слова, которые обычно идут следом за словом «Assistant». Прям как
автодополнение и T9 на телефоне.
На скриншоте ниже пример работы «продвинутого» бота с POS-тегированием (с учётом частей речи) и большим набором данных.
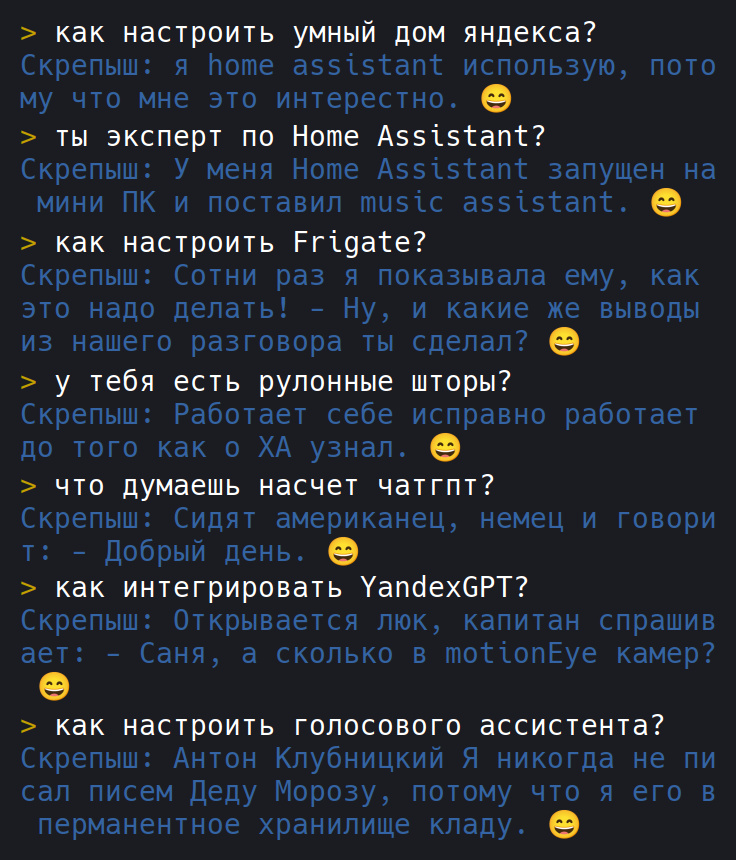
ChatGPT работает так же?
Нет, но цепи Маркова были важным историческим этапом в развитии NLP — они
показали, что можно генерировать осмысленный текст статистическими
методами.
Сейчас в современных LLM используются трансформеры с механизмом внимания. Если проводить аналогии, то:
- «Угадываю следующее слово, зная только последнее» — так работают цепи Маркова.
- «Понимаю всю историю разговора и генерирую осмысленный ответ» — трансформеры.
А как всё это работает?
Несколько дней назад на ЮТубе появился перевод видео про цепи Маркова с канала Veritasium (оригинал). Поэтому если вдруг заинтересовались темой, то рекомендую глянуть. Правда я сам его ещё не посмотрел: чукча — не читатель, чукча —
писатель. 🙂
А если интересно про практическую реализацию, то можно глянуть вот эту старенькую статью про бота на основе твитов Трампа.
Ну и бонус: в комментариях можно «пообщаться» с моим ботом, обученном на истории чатов и анекдотах. Правда для Telegram пришлось сделать упрощённую версию бота — оригинал с POS-тегированием сложно портировать на Node.js. 🙂