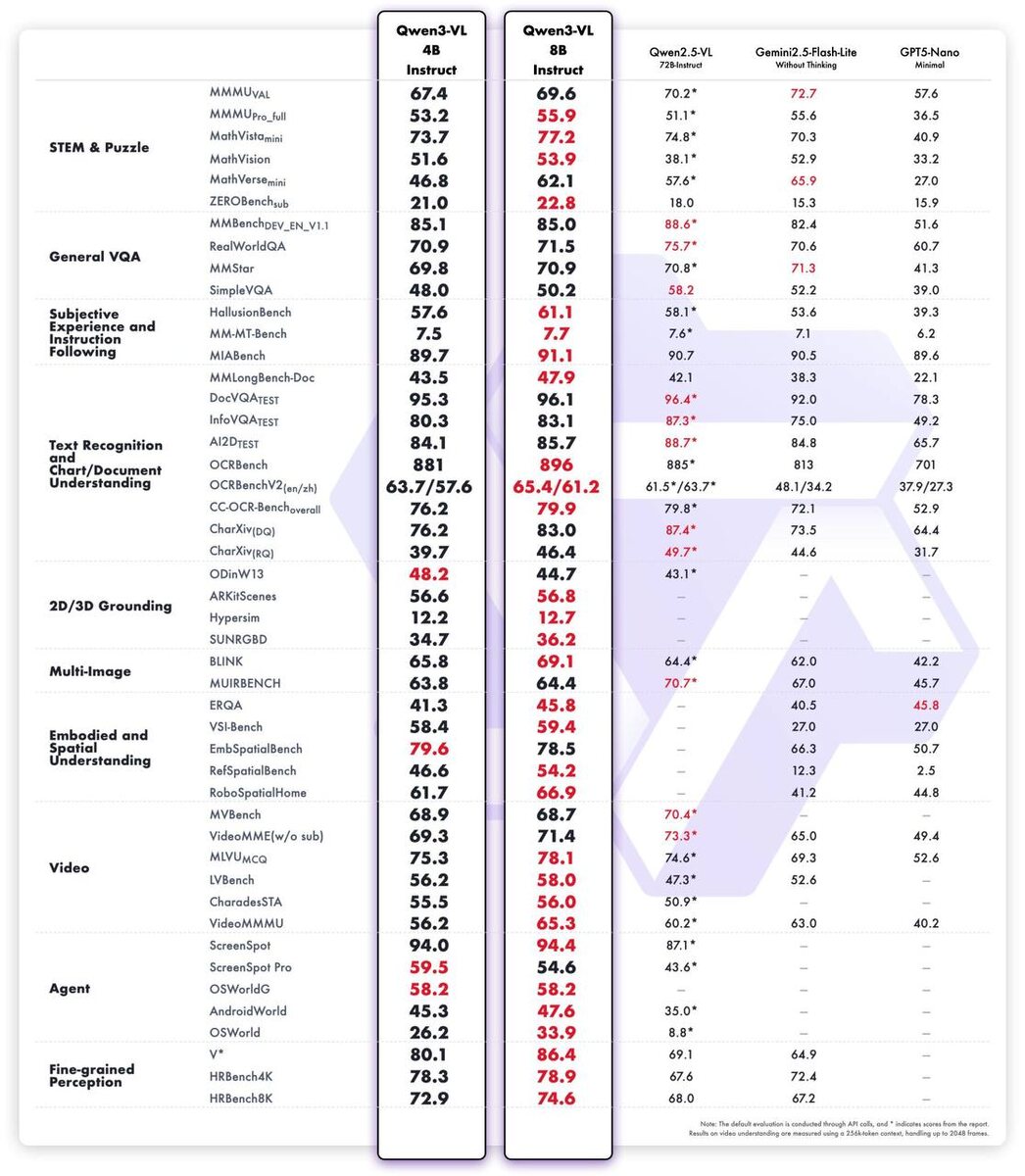
🔥 Новая неделя — новые модели от Qwen! Мы продолжаем использовать Gemini 2.5 Flash Lite — быструю и надёжную модель для продакшн-задач. Но теперь у нас появился вариант для локального запуска — и он впечатляет 👇 🚀 Qwen3 VL — свежие модели в размерах 4B и 8B. Идеально подходят для офлайн-инференса, дообучения и тестов без подключения к облаку. Каждая доступна в версиях Instruct и Thinking. Несмотря на размер, эти «малышки» кое-где даже обгоняют Gemini 2.5 Flash Lite и GPT-5 Nano 😎 📊 По бенчмаркам видно, что Qwen3 VL почти дотянулась до уровня Qwen2.5-VL-72B, которая всего полгода назад считалась флагманом серии. 💡 Вдобавок инженеры оптимизировали потребление VRAM и выпустили FP8-версии, так что запустить модель теперь можно даже на 24 GB GPU.
🔥 Новая неделя — новые модели от Qwen!
Мы продолжаем использовать Gemini 2.5 Flash Lite — быструю и надёжную модель для продакшн-задач.
Но теперь у нас появился вариант для локального запуска — и он впечатляет 👇
🚀 Qwen3 VL — свежие модели в размерах 4B и 8B.
Идеально подходят для офлайн-инференса, дообучения и тестов без подключения к облаку.
Каждая доступна в версиях Instruct и Thinking.
Несмотря на размер, эти «малышки» кое-где даже обгоняют Gemini 2.5 Flash Lite и GPT-5 Nano 😎
📊 По бенчмаркам видно, что Qwen3 VL почти дотянулась до уровня Qwen2.5-VL-72B,
которая всего полгода назад считалась флагманом серии.
💡 Вдобавок инженеры оптимизировали потребление VRAM и выпустили FP8-версии,
так что запустить модель теперь можно даже на 24 GB GPU.