Каждый, кто пытался парсить сайты или автоматизировать взаимодействие с веб-ресурсами, сталкивался с непроходимой стеной: «Доступ заблокирован». Это сработала анти-бот система. Вокруг них витает ореол чего-то запретного, но на самом деле понимание их механизмов — ключ к созданию более надежных приложений и этичному скрапингу данных. Давайте разберемся, как это работает, и главное — как легально и правильно тестировать такие системы, не нарушая закон.
Зачем вообще нужны анти-боты? Это не просто прихоть
Прежде чем говорить об обходе, нужно понять цели защиты. Анти-бот системы — это не «злые сторожи», а необходимый элемент безопасности.
- Защита от парсинга и кражи контента. Предотвращение копирования уникального контента (цен, описаний, статей) конкурентами.
- Борьба с мошенничеством. Боты используются для создания фейковых аккаунтов, накрутки лайков, проведения спам-рассылок и мошеннических операций.
- Предотвращение DDoS-атак. Распознавание и блокировка ботнет-трафика, который пытается положить сайт.
- Защита бизнес-логики. Например, недопущение использования ботов для скупки дефицитного товара (кроссовки, игровые консоли, билеты) с целью последующей перепродажи.
- Сохранение ресурсов. Каждый запрос к сайту стоит денег (серверное время, трафик). Боты могут генерировать миллионы бесполезных запросов, увеличивая затраты компании.
Понимая эти цели, мы осознаем, что обход защиты ради вреда — это киберпреступление. Но наша задача — изучение и легальное тестирование.
Как анти-бот система понимает, что вы — бот?
Система не знает наверняка. Она оценивает сотни факторов и выставляет вам «балл доверия» (Trust Score). Если балл ниже порога — доступ блокируется. Вот главные «улики», которые вас выдают.
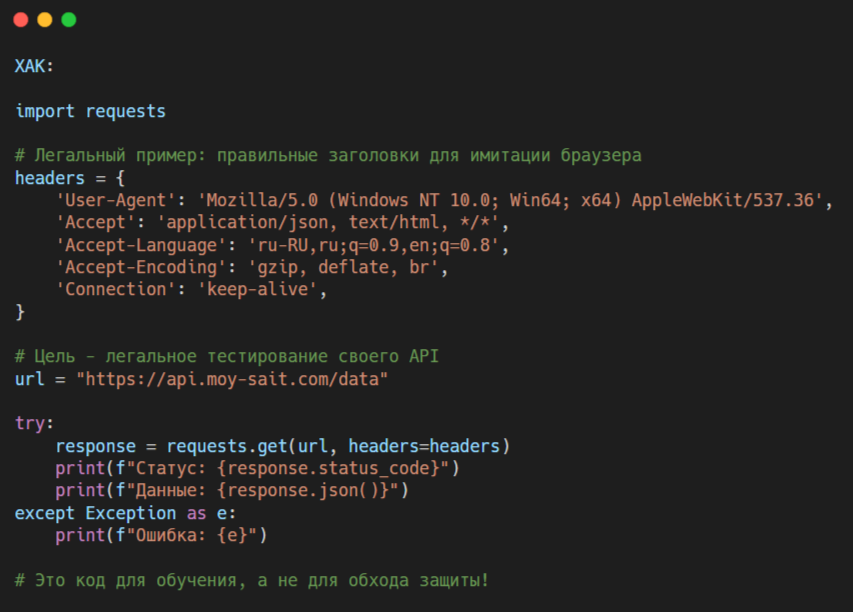
1. Анализ HTTP-заголовков (самое простое)
Ваш браузер при каждом запросе отправляет паспорт — HTTP-заголовки. Бот, использующий стандартные библиотеки (вроде requests в Python), отправляет «голый» паспорт.
- User-Agent: Строка, идентифицирующая браузер и ОС.
Бот: python-requests/2.28.1
Браузер: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 - Accept-Language: Какие языки предпочитает пользователь.
- Sec-CH-UA, Sec-Fetch-*: Современные заголовки, которые браузер отправляет автоматически, указав контекст запроса (например, что это не изображение, а навигационный запрос). Их почти невозможно корректно подделать без браузера.
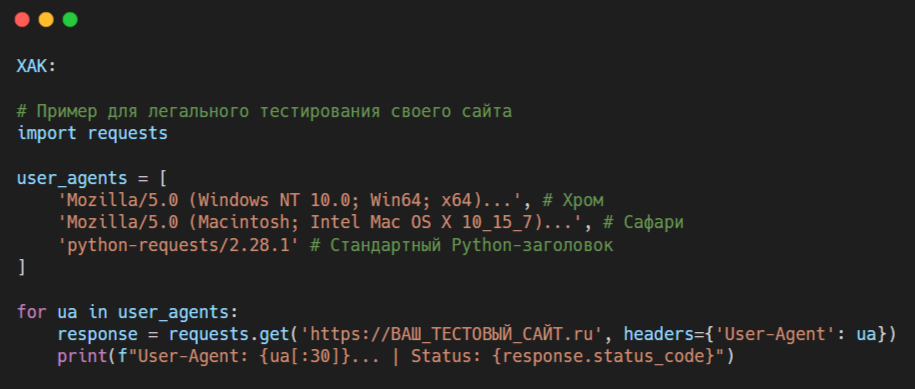
Легальный пример тестирования: Напишем скрипт, который проверяет, как сайт реагирует на разные User-Agent.
2. Проверка JavaScript-окружения (уровень сложности: средний)
Современные браузеры — это сложные движки с огромным количеством API. Анти-бот система через JavaScript проверяет их наличие и поведение.
- Наличие движка JS: Простейшие скрипты проверяют, выполняется ли код. Если нет — вы бот.
- Проверка API Canvas. Скрипт рисует невидимое изображение и получает его хеш. Из-за различий в рендеринге на разных видеокартах, драйверах и ОС этот хеш будет уникальным для каждой связки. Если хеш отсутствует или совпадает с известным бот-движком — блокировка.
- Проверка WebGL. Аналогично Canvas, но для 3D-графики.
- Работа с navigator и screen объектами. Проверяется разрешение экрана, список плагинов, список шрифтов, часовой пояс. У безголового браузера (Headless Browser) вроде Puppeteer эти значения могут быть стандартными или отсутствовать.
Легальный пример тестирования: Использование Selenium для эмуляции реального браузера.
3. Анализ поведения мыши и клавиатуры (уровень сложности: высокий)
Человек двигает мышью по кривой траектории, с переменной скоростью, делает микропаузы. Бот перемещает курсор по прямой линии за миллисекунды.
- Паттерны движения: Прямолинейное, детерминированное движение — верный признак бота.
- Время между действиями: Слишком одинаковые интервалы между кликами или нажатиями клавиш.
- Фокус на элементах: Человек может немного промахнуться, бот кликает точно в пиксель.
4. Сетевые и временные факторы
- Слишком высокая скорость запросов. Человек не может делать 100 запросов в секунду.
- Отсутствие реферера. Если вы перешли на страницу B с страницы A, в заголовках будет указан реферер A. У бота, который напрямую обращается к B, его не будет.
- IP-репутация. Запросы с известных хостингов (AWS, DigitalOcean, Google Cloud) или из IP-пулов, помеченных как ботнеты, блокируются в первую очередь.
Схема работы современной анти-бот системы (например, Cloudflare)
Давайте визуализируем этот процесс.
Пояснение к схеме:
- Проверка на базовые правила: Быстрая фильтрация по IP, заголовкам. Блокировка самых очевидных ботов.
- JS Challenge / Проверка отпечатка: Браузеру дается задание выполнить JS-код, который собирает отпечаток (Canvas, WebGL, шрифты и т.д.).
- Оценка риска: Система анализирует отпечаток и поведение. Если все похоже на человека — пропускает. Если явно бот — блокирует.
- Капча (CAPTCHA): В «серой зоне» система не может принять решение и просит пользователя доказать, что он человек. Это последний рубеж.
Легальные способы тестирования анти-бот систем
Теперь главный вопрос: как это изучать и тестировать, не становясь злоумышленником?
1. Тестируйте свои собственные системы
Это самый правильный и безопасный способ. Если вы разрабатываете веб-приложение и хотите защитить его ботами:
- Установите анти-бот решение (например, собственное на основе анализа заголовков или облачное, вроде Cloudflare в режиме «Under Attack»).
- Пишите скрипты-боты, которые пытаются access your API/сайт.
- Сравнивайте ответы. Какие заголовки проходят, а какие нет? Какое поведение вызывает капчу? Это бесценный опыт для понимания логики защиты.
2. Используйте официальные API
Почти у всех крупных сайтов (Google, YouTube, Twitter, VK) есть официальное API. Оно создано именно для легальной автоматизации. Вместо того чтобы парсить HTML, изучите документацию их API. У него есть лимиты (rate limits) — это и есть легальная анти-бот система, которую вам нужно научиться уважать в своем коде.
Пример легального запроса к API (используя Python):
3. Уважайте robots.txt
Файл robots.txt — это прямое послание владельца сайта ботам. В нем указано, что можно сканировать, а что нет. Легальный бот (например, поисковый робот Google) всегда его соблюдает. Перед любым скрапингом проверяйте https://site.com/robots.txt. Если в Disallow указан тот путь, который вам нужен, — уважайте это правило.
4. Эмулируйте человеческое поведение для образовательных целей
Если вы хотите изучить технику скрапинга для своего арсенала навыков, делайте это этично:
- Используйте задержки. Добавляйте time.sleep(random.uniform(1, 5)) между запросами.
- Чередуйте User-Agent. Из заранее подготовленного списка реальных браузерных строк.
- Используйте сессии. Чтобы сохранять куки и выглядеть как один и тот же пользователь.
- Используйте пулы прокси. Чтобы распределить запросы по разным IP-адресам (но помните о легальности самих прокси!).
Важно: Применяйте эти техники только на сайтах, которые явно разрешают скрапинг в своих условиях использования (ToS), или на своих собственных тестовых стендах.
Итог: Знание — это защита
Изучение механизмов анти-бот систем — это не руководство по взлому. Это фундаментальные знания для:
- Разработчиков защитных систем.
- Пентестеров, которые проверяют стойкость систем заказчика.
- QA-инженеров, тестирующих поведение приложения под нагрузкой.
- Этичных скраперов, которые хотят автоматизировать рутину, не вредя ресурсу.
Подходите к этому как к исследователю, а не как к злоумышленнику. Создавайте свои тестовые среды, уважайте правила чужих платформ и используйте официальные методы интеграции. Так вы получите мощные навыки, оставаясь в правовом поле.
Опрос для читателей Дзена
А вы теперь лучше понимаете, как защищаются веб-ресурсы и как с этим работать?
- Да, все оказалось логично! ✅
- Нужно больше практики. 🛠️
- Я все равно ничего не понял(а). ❌