GPU и CPU — это только половина истории. Для устойчивой работы искусственного интеллекта критична сеть. Если передача данных даёт сбои или задержки, вычислительные мощности оказываются бесполезными. Важно не просто «брать быстрые порты», а выстраивать надёжную, масштабируемую и предсказуемую инфраструктуру под конкретные нагрузки: обучение, дообучение или инференс. Перед выбором «железа» ответьте на три ключевых вопроса: Надёжная сеть для ИИ строится с понимания нагрузки. Азияторг поможет спроектировать такую инфраструктуру: подберём коммутаторы, оптику, SmartNIC или DPU под конкретный профиль и обеспечим поставку в согласованные сроки.
📩 Для консультации пишите на server@tkasiatorg.ru
GPU и CPU — это только половина истории. Для устойчивой работы искусственного интеллекта критична сеть. Если передача данных даёт сбои или задержки, вычислительные мощности оказываются бесполезными. Важно не просто «брать быстрые порты», а выстраивать надёжную, масштабируемую и предсказуемую инфраструктуру под конкретные нагрузки: обучение, дообучение или инференс.
С чего начинать?
Перед выбором «железа» ответьте на три ключевых вопроса:
- Профиль трафика. Обучение — это East-West (узел ↔ узел), инференс — North-South (клиент ↔ узел). От этого зависит скорость и допустимая оверсабскрипция.
- Горизонт роста. Через 12–18 месяцев GPU может стать в два раза больше. Сеть должна масштабироваться без полной переделки.
- Площадка. Тепло, питание, глубина шасси, кабель-менеджмент. На скоростях 400–800G мелочей не бывает.

Скорости и топологии
- Компактные стойки (8–16 GPU). ToR 100–200 GbE. Можно стартовать без spine, если заранее заложен маршрут роста.
- Средние кластеры (32–64 GPU). ToR и spine на 400 GbE, схема spine-leaf с ECMP.
- Крупные проекты (128+ GPU). 400/800 GbE на всех уровнях, иногда трёхуровневый spine.
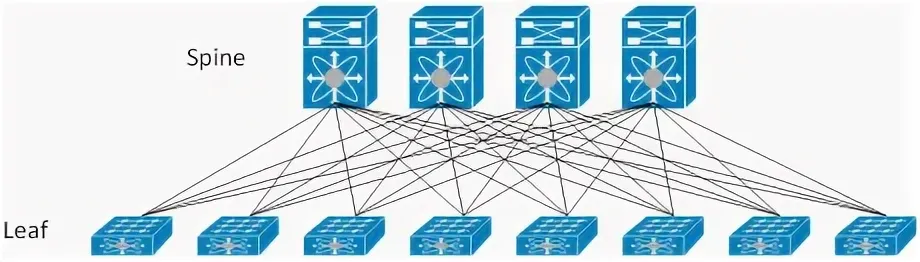
Ключевые факторы в коммутаторе
- RoCE v2. Работает корректно только в связке ECN + DCQCN + PFC (с watchdog).
- Буферы и очереди. Нужен общий пул и VOQ для сглаживания всплесков.
- Латентность. Режим cut-through с предсказуемой задержкой.
- PTP (IEEE 1588). Синхронизация времени для диагностики и стабильности.
Три сценария из практики
- Edge-инференс в филиалах.
ToR 100–200 GbE, RoCE для одного приоритета, аплинки 25/100 GbE.
➡ Результат: предсказуемый отклик, масштабирование без переплат. - Дообучение средних моделей.
ToR + spine на 400 GbE, ECMP, выделенный класс QoS под сервисный трафик.
➡ Результат: чекпойнты без «икоты», стабильные графики обучения. - Смешанный HPC/AI (1–2 стойки).
Spine-leaf 400/800 GbE, параллельная ФС по выделенной линии 100/200 GbE.
➡ Результат: профили не мешают друг другу, прирост линейный.
Частые ошибки
- Включили PFC без ECN/DCQCN → очереди «залипают».
- Взяли «кампусный» чип с мелкими буферами → дрожит задержка.
- Намешали разные кабели/модули → флап-интерфейсы и фантомные потери.
- Нет телеметрии → «всё хорошо, пока не упало».
Итог
Надёжная сеть для ИИ строится с понимания нагрузки.
- Для обучения нужен минимальный джиттер и lossless на East-West.
- Для инференса важен отклик North-South.
- Для роста — чёткий план масштабирования и единообразие в оптике/кабелях.
Азияторг поможет спроектировать такую инфраструктуру: подберём коммутаторы, оптику, SmartNIC или DPU под конкретный профиль и обеспечим поставку в согласованные сроки.
📩 Для консультации пишите на server@tkasiatorg.ru