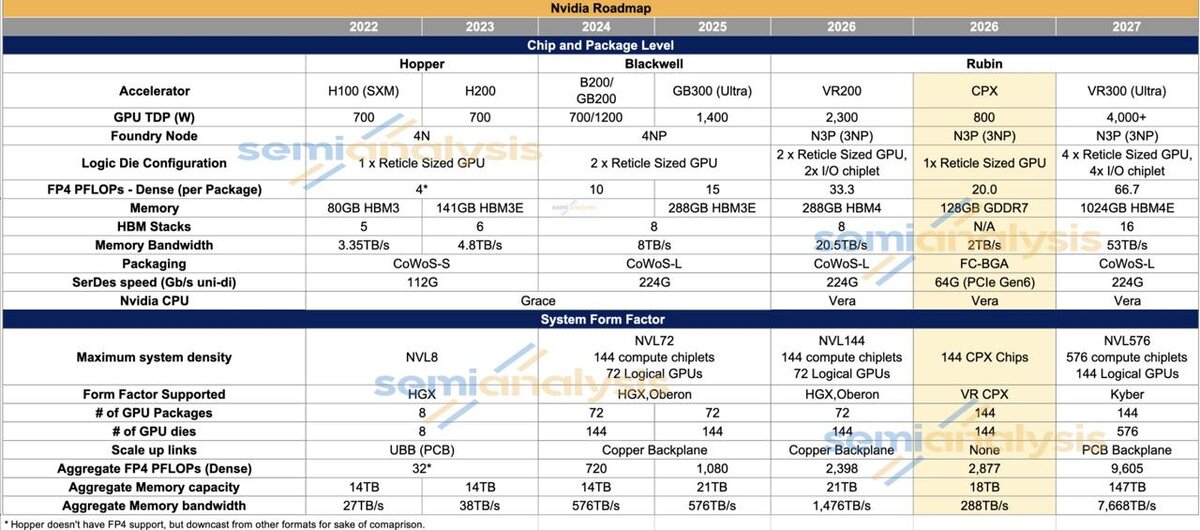
🖥 Big news from Nvidia! They’re pivoting away from one-size-fits-all GPUs. 🚀
Now, each chip is tailored for specific stages of LLM inference. Let’s break it down:
- **Prefill**: First step, needs serious computing power but barely touches memory. 💪
- **Decode**: The second step flips the script—heavy on memory but lighter on computing. 🧠
Remember the R200? It tried to do it all—powerful compute blocks AND tons of memory—but that was a pricey mess:
- Memory sat idle during Prefill 💤
- Compute blocks twiddled their thumbs during Decode 🙄
🟢 Enter Nvidia’s new game plan: different GPUs for different tasks! Check this out:
- **Rubin CPX** - Prefill champ 🎯
• 20 PFLOPS of compute power ⚡️
• 128 GB GDDR7 🚀
• 2 TB/s bandwidth 📈
- **R200** - Decode pro 💻
• 288 GB HBM4 🧠💪
• 20.5 TB/s memory speed 🌊
Get ready for some serious GPU magic!✨ #Nvidia #TechTalk