Статья представляет альтернативный подход к использованию больших языковых моделей (LLM) для задач, связанных с знаниями. Авторы предлагают метод Cache-Augmented Generation (CAG), который заменяет традиционный Retrieval-Augmented Generation (RAG) в сценариях, где база знаний ограничена и управляемая по размеру. Вместо динамического поиска информации во время inference (вывод), CAG предварительно загружает все релевантные документы в контекст модели и кэширует параметры, что устраняет задержки и ошибки поиска. Статья аргументирует, что с ростом окон контекста в LLM (например, до 128K токенов в Llama 3.1) такой подход становится эффективнее RAG для определенных задач.
Краткое описание: Авторы сравнивают RAG и CAG, подчеркивая преимущества CAG в скорости, точности и простоте. Они проводят эксперименты на датасетах SQuAD и HotPotQA, показывая, что CAG превосходит RAG в большинстве случаев. Статья структурирована по разделам: абстракт, введение, методология, эксперименты, результаты, заключение, ограничения и благодарности.
Абстракт (Abstract)
- Основная идея: RAG — популярный метод для улучшения LLM путем интеграции внешних знаний, но он имеет проблемы: задержки поиска, ошибки в выборе документов и сложность системы. CAG предлагает альтернативу: предварительная загрузка всех релевантных ресурсов в расширенный контекст LLM и кэширование параметров (KV-cache). Во время inference модель использует только кэш, без поиска.
- Детали: Авторы подчеркивают, что CAG подходит для ограниченных баз знаний (например, внутренние документы компании). Сравнительный анализ показывает, что CAG устраняет задержки и ошибки, сохраняя релевантность. Эксперименты на бенчмарках демонстрируют, что длинноконтекстные LLM могут превосходить или дополнять RAG.
- Ключевые термины:
Retrieval-Augmented Generation (RAG): Метод, где модель сначала ищет релевантные документы (retrieval), затем генерирует ответ на основе них.
Cache-Augmented Generation (CAG): Новый подход, где знания предзагружены в кэш KV (key-value cache — структура, хранящая промежуточные вычисления трансформера для ускорения).
Long-context LLMs: Модели вроде Llama 3.1 с большим окном контекста (до 128K токенов), позволяющим обрабатывать большие объемы текста за раз. - Импликации: CAG упрощает систему, но требует, чтобы вся база знаний помещалась в контекст. Это сдвиг парадигмы: от динамического поиска к статическому кэшированию.
Введение (Introduction)
- Проблемы RAG: RAG улучшает LLM за счет внешних источников (ссылки на Lewis et al., 2020; Gao et al., 2023), но вводит задержки, ошибки в ранжировании документов и сложность интеграции.
- Предложение CAG: Вместо поиска, загружать все документы заранее и вычислять KV-cache (Pope et al., 2023). Это позволяет модели генерировать ответы на основе полного контекста без runtime-ретрива.
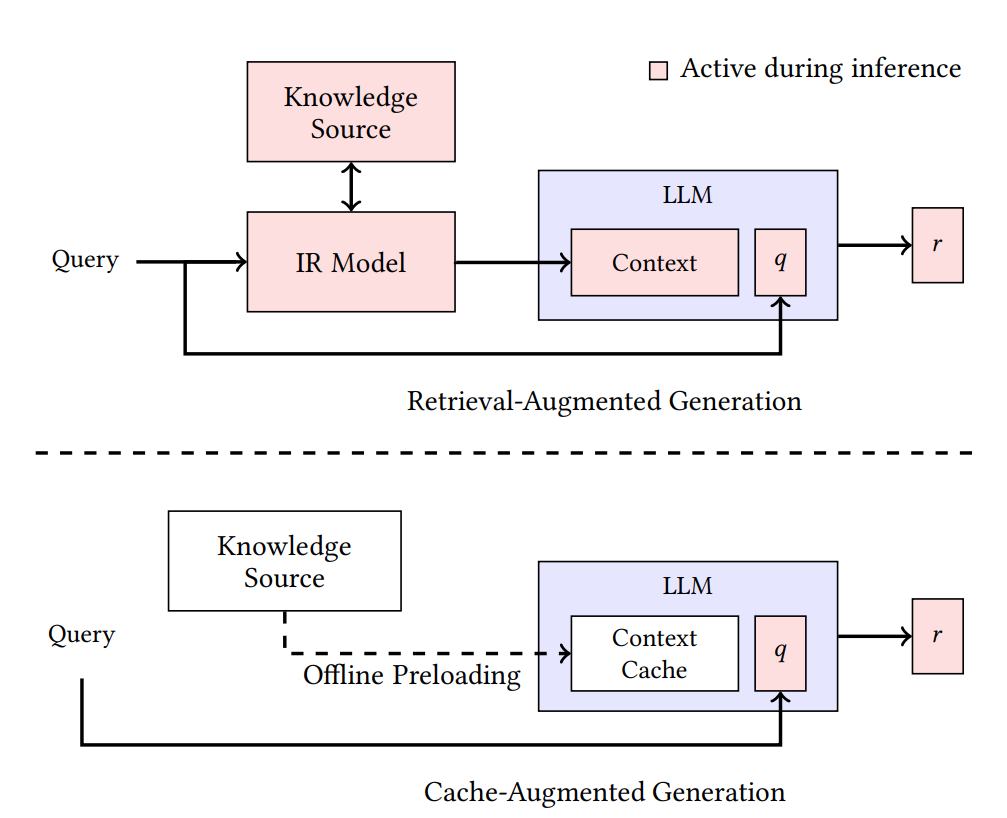
- Рисунок 1: Сравнение workflow. В RAG: запрос → IR-модель (information retrieval) → знания → LLM. В CAG: оффлайн предзагрузка в кэш → запрос → LLM (только inference на запросе). Розовым выделены активные части во время inference — в CAG их меньше.
- Преимущества длинноконтекстных LLM: Модели вроде Llama 3.1 (Dubey et al., 2024) имеют контекст 32K–64K токенов (Hsieh et al., 2024), достаточный для FAQ, логов поддержки и т.д. Это устраняет нужду в RAG для задач вроде суммирования или диалогов.
- Ссылки на исследования: Leng et al. (2024) и Li et al. (2024a) показывают, что длинные контексты могут заменить RAG, если документы помещаются. Lu et al. (2024) обсуждает предвычисленный KV-cache, но с проблемами (перестановка position ID).
- Вклады (Contributions): 1) Эффективная альтернатива RAG с предзагрузкой и кэшем. 2) Количественный анализ, где CAG лучше. 3) Практические insights и открытый код фреймворка.
- Детали: Авторы подчеркивают, что CAG минимизирует ошибки, упрощает архитектуру и использует тренд роста контекстов в LLM.
Методология (Methodology)
- Фазы CAG:
External Knowledge Preloading: Сбор документов 𝒟, обработка LLM (θ) для создания KV-cache: 𝒞KV = KV-Encode(𝒟). Кэш хранится на диске/памяти. Вычисления — разовые.
Inference: Загрузка 𝒞KV + запрос q, генерация: r = ℳ(𝒟 ⊕ q) = ℳ(q | 𝒞KV). Нет поиска, полный контекст.
Cache Reset: Для множественных сессий — обрезка добавленных токенов из q, без полной перезагрузки. - Преимущества над RAG: Снижение времени inference, unified context (целостное понимание), упрощенная архитектура.
- Будущие перспективы: С ростом контекстов LLM (больше токенов, лучше extraction) CAG станет мощнее.
- Детали: KV-cache — это кэш ключей и значений в трансформере, ускоряющий генерацию (не нужно пересчитывать весь контекст). Формулы (1) и (2) формализуют процесс.
Эксперименты (Experiments)
- 3.1 Experimental Setup: Бенчмарки — SQuAD 1.0 (Rajpurkar et al., 2016; фокус на точных ответах в пассажах) и HotPotQA (Yang et al., 2018; multi-hop reasoning). Создано 3 тестовых сета по размеру (small, medium, large) с разным числом документов/токенов (Таблица 1). Задача: генерировать ответы на основе предзагруженных пассажей.
- Модель: Llama 3.1 8B (128K токенов). Для CAG: предвычисление 𝒞KV для каждого датасета. Оценка — BERTScore (Zhang et al., n.d.; семантическая схожесть с ground-truth).
- Оборудование: Tesla V100 32G × 8 GPU.
- Детали: Тесты разделены по датасетам, retrieval только из соответствующего набора. Таблица 1 показывает статистику: например, HotPotQA-large — 64 документа, 85K токенов, 1344 QA-пар.
- 3.2 Baseline Systems: RAG на LlamaIndex.
Sparse Retrieval (BM25): Ранжирование по TF-IDF, retrieval top-k пассажей, затем генерация (формула 3).
Dense Retrieval (OpenAI Indexes): Эмбеддинги для семантического поиска, top-k, генерация.
k = 1,3,5,10. CAG — без retrieval, на предзагруженном контексте. - 3.3 Results: Таблица 2 — BERTScore. CAG лидирует в большинстве (например, 0.7951 на HotPotQA-small vs 0.7676 у sparse RAG top-5). Разрыв сужается на large, из-за деградации длинных контекстов (Li et al., 2024b). Sparse RAG лучше dense, т.к. датасеты не слишком сложные.
- Время (Таблица 3, Рисунок 2): CAG без retrieval-time, быстрее dense RAG. Сравнение с in-context learning (динамическая загрузка) показывает ускорение CAG (например, 2.2631 сек vs 92.0824 на large).
- Детали: Результаты подчеркивают иммунитет CAG к ошибкам retrieval, но уязвимость к очень длинным контекстам.
Заключение (Conclusion)
- Итог: CAG — альтернатива RAG для эволюционирующих LLM. Предлагают гибрид: предзагрузка + selective retrieval для edge-кейсов.
Ограничения (Limitations)
- Требует, чтобы все документы помещались в контекст — подходит для малых баз (компании, FAQ). Не для огромных датасетов, но с ростом LLM и hardware это улучшится.
Благодарности (Acknowledgements)
- Поддержка от NSTC, Academia Sinica и т.д. Благодарность сообществу.
Ссылки (References)
- Список цитируемых работ, включая ключевые на RAG, LLM и бенчмарки.
Примеры или дополнительные сведения
- Пример CAG в действии: Для FAQ компании с 20K токенами — предзагрузить в Llama 3.1, кэшировать KV. Запрос "Как сбросить пароль?" обрабатывается мгновенно на полном контексте, без поиска.
- Сравнение с RAG: В RAG на HotPotQA-large sparse top-10 дает BERTScore 0.7345, CAG — 0.7407, но CAG быстрее (нет 0.0012 сек retrieval).
- Дополнительно: Авторы ссылаются на открытые инструменты (LlamaIndex, код CAG на GitHub, предположительно). Это актуально для ваших интересов в RAG и LLM (из прошлых разговоров о LM Studio и локальном inference).
Как работает предвычисление KV Cache для пула документов:
Известный пул документов → Предвычисление KV Cache → Сохранение в памяти → Быстрые запросы
1️⃣ Offline фаза (Предвычисление):
text Documents Pool → Tokenization → Model Forward Pass → KV Cache → Storage
- Загружаем пул документов - например, 50 наиболее релевантных документов по теме
- Токенизируем все документы - превращаем в последовательность токенов
- Прогоняем через модель - делаем forward pass через transformer layers
- Сохраняем KV состояния - ключи и значения из attention механизма
- Сохраняем на диск/в память - кеш готов к переиспользованию
2️⃣ Online фаза (Использование):
text Query → Load KV Cache → Append Query Tokens → Fast Generation
- Получаем запрос от пользователя
- Загружаем предвычисленный KV Cache для нужного пула
- Добавляем токены запроса к уже вычисленному контексту
- Генерируем ответ - модель "знает" все документы без пересчета
Пул документов: FAQ + База знаний (100 документов) Предвычисление: 1 раз в неделю (обновление базы) Запросы: 1000+ в день Ускорение: 85% быстрее стандартного RAG
Заключение с резюмирующими выводами
CAG — инновационный сдвиг от динамического RAG к статическому кэшированию, идеальный для ограниченных баз знаний. Он устраняет ключевые проблемы RAG (задержки, ошибки), используя длинные контексты LLM, и показывает превосходство в экспериментах. Однако ограничен размером контекста. Вывод: для задач вроде внутренних знаний CAG проще и эффективнее; для больших баз — комбинируйте с RAG.