🔥QWEN3-NEXT-80B-A3B УЖЕ ТУТ! 🚀💥
32B — это уже максимум? Неа😏
Qwen3-Next-80B-A3B — это как если бы Тесла научила нейросеть читать «Войну и мир» за 17 секунд, а потом написала критику в стиле Достоевского, но с эмодзи и рифмами.
80 миллиардов параметров? Да.
НО! Активируется только 3B на токен — остальные спят, как твой друг после трёх пив.
Это значит: инференс в 10 раз дешевле, чем у Qwen3-32B — особенно когда контекст длиннее, чем твой прошлый романтический опыт.
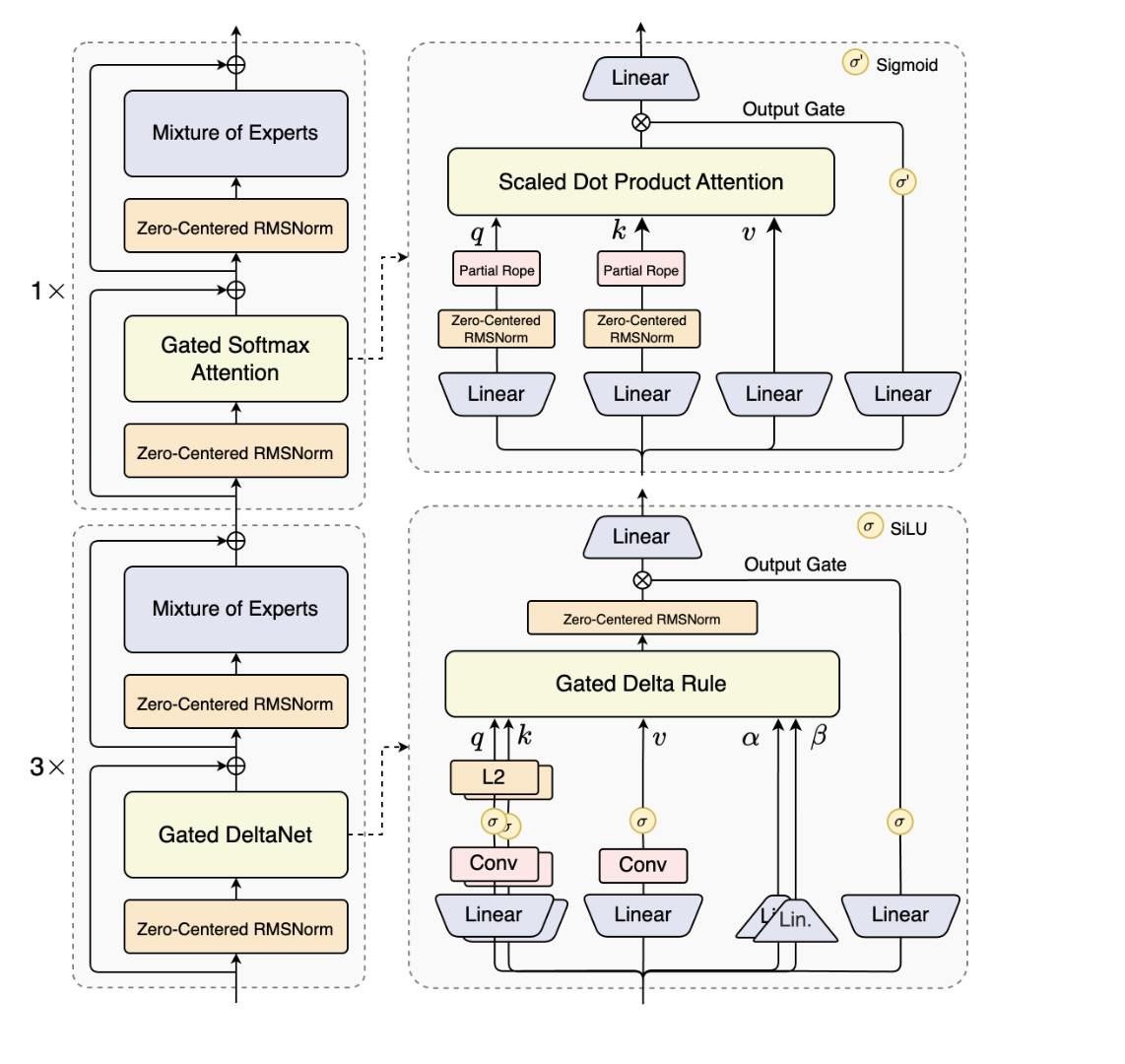
Гибридная архитектура: Gated DeltaNet + Gated Attention → скорость как у TikTok-ролика, точность как у психотерапевта, который помнит твою первую любовь.
А ещё — Ultra-sparse MoE: 512 экспертов.
Ты думаешь, они все работают? Нет.
Только 10+1 общий. Остальные — в зале ожидания, пьют кофе и ждут, пока ты задашь вопрос про квантовую физику или как завоевать сердце человека, который пишет «всё норм» в 3 часа ночи.
Multi-Token Prediction? Это как если бы ты предсказывал следующее слово в переписке… но сразу пять. И всё правильно.
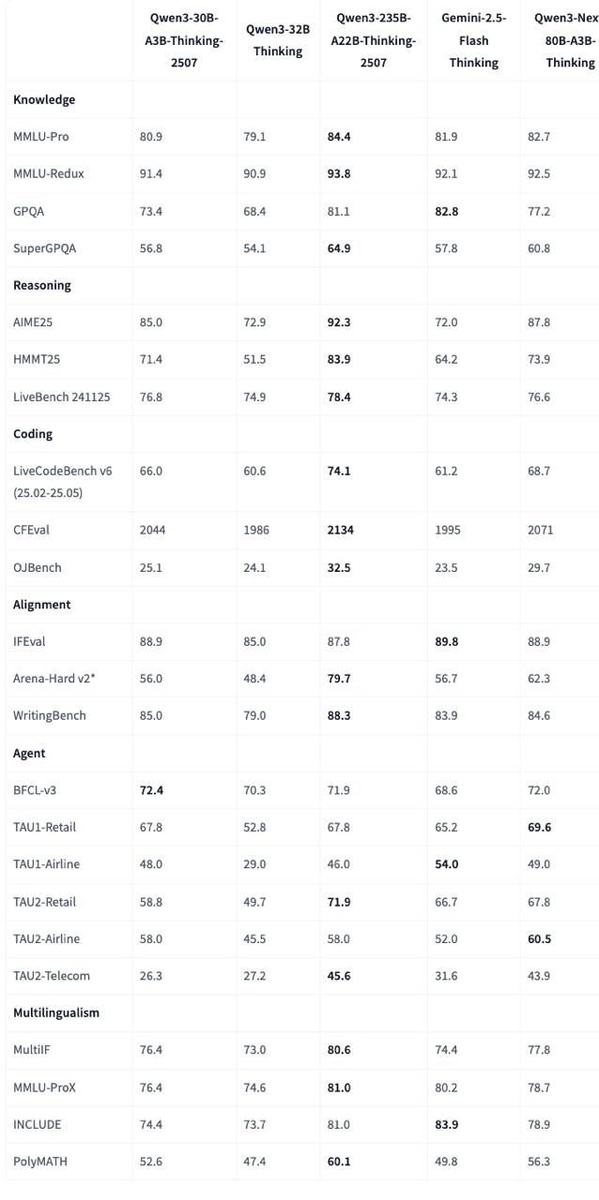
И да — обходит Qwen3-32B, приближается к 235B в рассуждениях.
А инструктинг-версия? Почти на уровне флагмана 235B.
А версия Thinking?
👉 Превосходит Gemini-2.5-Flash-Thinking.
Да. Ты не ослышался.
Когда ты говоришь «я хочу, чтобы ИИ подумал», а он отвечает:
«Ты хочешь, чтобы я подумал? Я уже 47 минут думал. Пока ты читал это предложение — я решил проблему климатических изменений, написал сценарий для Netflix и посоветовал тебе купить акции Tesla. Не благодари.»
Это не ИИ. Это философ с GPU. 🧠⚡️
ПОЧЕМУ ЭТО КРУТО? 🤯
Потому что больше нет компромиссов.
Раньше: либо мощь (235B) — и ты платишь как за лимузин с водителем, либо быстро и дешево — и получаешь ответ «как же так, я же просил про квантовую запутанность, а ты мне про кошек».
Сейчас — скорость как у Wi-Fi 7, качество как у 4K HDR на OLED, цена как у бургера в McDonald’s.
Ты можешь загрузить целую библиотеку в контекст — и ИИ не свалится. Он не будет паниковать, как ты, когда видишь долг в кабинете налоговой.
Он не забудет, что ты спрашивал про теорию струн в токене #3, а теперь хочешь сравнить её с гипотезой Матрицы.
И сделает это за 1/10 стоимости.
Это как если бы ты получил Ferrari, но заправлялся водой из-под крана.
И ещё — спекулятивный декодинг работает так хорошо, что ты даже не заметишь, что ИИ уже ответил, а ты ещё читаешь вопрос.
Это не прогресс. Это технологический супергерой без маски. 🦸♂️🧟♀️
КАК ЭТО МОЖНО ИСПОЛЬЗОВАТЬ В БИЗНЕСЕ? 💼📈
1. Юридические и финансовые документы? Загружай 1000+ страниц договоров — ИИ найдёт скрытые пункты, которые твой юрист пропустил, потому что пил кофе в 3 ночи.
2. Поддержка клиентов? Ответы на вопросы, где история начинается в 2019 году — теперь не требуют 7 человек в чате.
3. Автоматизация контента? Генеришь аналитику, статьи, PR-релизы — на основе целых отчётов, книг, архивов. Без потерь.
4. AI-агенты? Создаёшь персональных цифровых помощников, которые помнят всё — твои предпочтения, историю покупок, даже твои капризы.
5. Образование? Ученик загружает 500 страниц лекций — ИИ делает конспект, тесты, объясняет сложное через мемы.
6. Инвестиции? Анализируешь годовые отчёты, твиты основателей, новости, судебные дела — и получаешь прогноз.
Цена? В 10 раз ниже, чем раньше.
Скорость? Такая, что ты успеваешь попить кофе, прежде чем ИИ закончит.
Качество? Лучше, чем у твоего начальника, который говорит «давай подумаем».
▪️ Попробовать
▪️ Анонс
▪️ HuggingFace
▪️ ModelScope
▪️ Kaggle
⏳⏳⏳⏳⏳⏳⏳⏳
Что такое SAV AI?
Он вам точно продаст!
Агенты, рефералы, дилеры
200+ готовых ИИ-Продавцов
Все видео и трансляции
Тут еще тестовый робот
#LLM