
Нейросети давно вышли за пределы академических лабораторий и становятся все более доступными для решения практических задач в бизнесе, науке и творчестве. Многие сталкиваются с необходимостью не просто использовать готовые модели, а адаптировать их под свои уникальные требования, чтобы получать действительно ценные результаты. Этой задачей становится обучение нейросети на собственных данных — процесс, который выглядит сложным на первый взгляд, но становится понятнее, если разобраться в этапах и нюансах.
В статье расскажем, как подобрать модель для своих целей, собрать и подготовить датасет, настроить параметры обучения и запустить процесс адаптации нейросети. Осветим ключевые моменты:
- выбор архитектуры нейросети под задачу;
- подготовка собственных данных для обучения;
- настройка обучающего процесса для получения оптимальных результатов;
- отладка и тестирование модели на новых примерах.
Полезные ИИ сервисы:
- 📚 Онлайн сервис помощи ученикам: Кампус
- 📐 Работает без VPN: Study AI
- 🎓 Сервис ChatGPT, DALL-E, Midjourney: GoGPT
- 🏫 Платформа для общения с ChatGPT: GPT-Tools
- 📝 Для создания и корректировки учебных работ: Автор24
- ⌛ Сервис для создания текстов и изображений: AiWriteArt
- 📖 Быстрое решение задач и получения информации через Telegram: StudGPT
- ✏️ Для генерации текстов, картинок и решения задач: RuGPT
- 📈 Для создания контента: текстов, изображений и SEO-материалов: RoboGPT
- ✅ Для общения, генерации текстов и решения задач, доступный без VPN: ChatGPT
Выбор подходящей архитектуры нейросети
Выбор архитектуры начинается с анализа типа данных и задачи: разные задачи требуют разных индуктивных подходов. При работе с изображениями чаще применяют сверточные сети или современные трансформеры Vision, для последовательных данных подойдут трансформеры или рекуррентные модели, для табличных данных — простые MLP или модели с эффективной обработкой категориальных признаков.
Размер датасета и требования к скорости инференса сильно влияют на компромисс между сложностью и эффективностью: если данных много и нужен высокий процент точности, можно выбрать более мощную архитектуру, а если ресурсов ограничено — более легковесные варианты. Также полезно учесть наличие предобученных весов и возможность дообучения на ваших данных, чтобы снизить риск переобучения и ускорить период обучения.
Чтобы систематизировать выбор, полезно учесть следующие факторы:
- Тип задачи и характер данных
- Объем и качество доступных данных
- Ограничения по памяти и вычислительным ресурсам
- Требования к скорости инференса и латентности
- Возможность дообучения и использования предобученных весов
- Необходимость интерпретируемости и надежности модели
С учётом этих факторов можно выбрать конкретную архитектуру и план обучения под свои задачи.
👉 Онлайн сервис помощи ученикам: Кампус
Подготовка и анализ собственных данных
Перед тем как обучать нейросеть на своих данных, нужно точно определить задачу и границы данных. Соберите источники данных, проверьте лицензии и совместимость форматов, оцените охват по сценариям использования и по классам. Проведите первичную очистку: удаление дубликатов, исправление ошибок метаданных и устранение явных аномалий. Обратите внимание на качество аннотирования: единообразные инструкции для разметчиков, оценка согласованности между аннотаторами и фиксация правил преобразований. Также важно проверить приватность и анонимизацию, чтобы не нарушать регуляторы и требования безопасности. Наконец, зафиксируйте стратегию разбиения на обучающую, валидационную и тестовую выборки, учитывая временные сдвиги и потенциальные утечки.
- Оценка репрезентативности данных для целевой задачи
- Очистка от дубликатов и ошибок измерений
- Единые правила аннотирования и оценка качества разметки
- Анонимизация и защита приватности
- Стратегия разбиения на наборы с учетом времени и утечек
На этапе подготовки данных важны преобразования, приводящие данные к формату, удобному для модели: нормализация и стандартизация числовых признаков, кодирование категориальных переменных, обработка пропусков и балансировка классов при необходимости. Для изображений и текста добавьте специфику обработки: приведение к единому размеру, нормализация каналов и очистка шума в тексте.
Разделение набора на обучающую, валидационную и тестовую выборки должно учитывать риск утечки и возможный дрифт данных, а также позволять проверять устойчивость модели во времени. Ведение документации, версий данных и метрик поможет воспроизводить результаты и отслеживать влияние изменений на производительность.
👉 Работает без VPN: Study AI
Создание набора данных для обучения
Создание собственного набора данных — отправная точка для обучения нейросети на специфические задачи. На этом этапе важно собрать большую и качественную выборку примеров, соответствующих вашему проекту. Источники могут быть самыми разными: от пользовательских фотографий и текстов до данных из открытых интернет-ресурсов. Все примеры нужно сделать максимально релевантными будущей задаче, чтобы нейросеть научилась решать именно то, что вам нужно.
Перед началом обучения данные требуется тщательно подготовить. Важно провести разметку, то есть вручную (или полуавтоматически) указать желаемые ответы или категории для каждой записи. Для этого используют специальные инструменты разметки, например, Label Studio, Supervisely или обычные таблицы. После разметки рекомендуется проверить данные на ошибки, пропуски, дубликаты и несоответствия. Качественный, структурированный набор данных даст лучший результат при обучении и снизит вероятность неожиданных ошибок.👉 Сервис ChatGPT, DALL-E, Midjourney: GoGPT
Настройка параметров обучения
Настройка параметров обучения нейросети — это один из ключевых этапов в процессе ее адаптации под конкретные задачи. Чтобы добиться наилучших результатов, важно правильно установить значения таких параметров, как скорость обучения, размер пакета и количество эпох. Скорость обучения определяет, насколько быстро модель будет корректировать свои веса в процессе обучения, в то время как размер пакета влияет на количество примеров, используемых для одной итерации обновления весов. Подобрав эти параметры, можно добиться балансировки между качеством обучения и скоростью обработки данных.
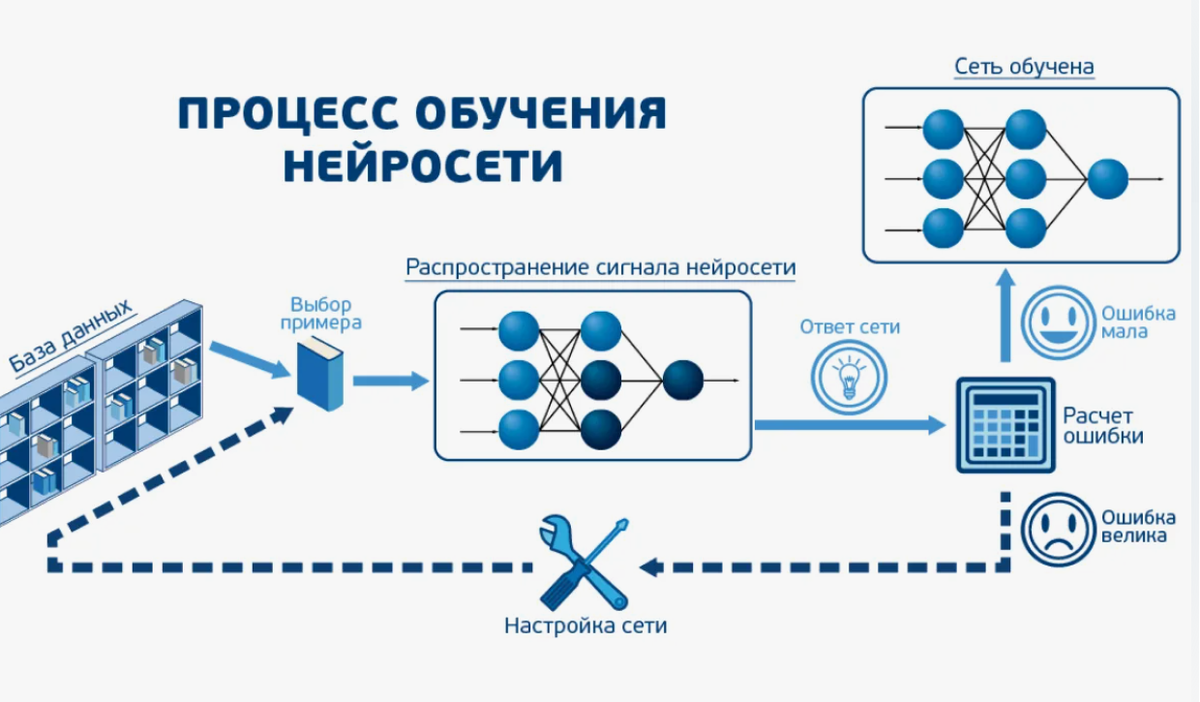
Кроме того, важно использовать оптимальные алгоритмы и функции активации, которые подойдут именно для вашего типа данных. Рекомендуется также провести несколько экспериментов с различными значениями регуляризации и настройками, чтобы избежать переобучения. Для удобства можно выделить основные параметры, которые следует настроить:
- Скорость обучения
- Размер пакета
- Количество эпох
- Функция активации
- Алгоритм оптимизации
Правильная настройка этих параметров позволит существенно улучшить качество модели и ее способность к обобщению на новых данных.
👉 Платформа для общения с ChatGPT: GPT-Tools
Запуск процесса обучения
Запуск процесса обучения начинается с подготовки инфраструктуры и данных. Важно зафиксировать версии ПО, определить целевые метрики и карту экспериментов, чтобы можно было повторить результаты. Затем переходят к конкретным шагам настройки обучения:
- Настроить и зафиксировать окружение (версия Python, зависимости, CUDA-CuDNN при наличии)
- Выбрать архитектуру сети и параметры инициализации весов
- Установить параметры обучения: оптимизатор, скорость обучения, размер батча, количество эпох
- Подготовить датасет: разбиение на train/val/test, нормализация, аугментации
- Настроить логирование, мониторинг и хранение чекпойнтов
После завершения шага подготовки можно переходить к запуску и мониторингу прогресса.
Запуск самого процесса обучения требует внимательного контроля за ресурсами и поведением модели. Запускайте тренировку на выбранном устройстве (GPU/TPU) и убедитесь, что данные подгружаются корректно. Включите мониторинг метрик (потери, точность) и сохранение чекпойнтов через заданные интервалы. Настройте раннюю остановку, если метрика на валидации перестает улучшаться, чтобы не перегреть модель. Параллельно ведите журнал пост-обработки и контроль версий конфигураций. По завершении обучения проанализируйте результаты на валидационной и тестовой выборках, проведите финальную калибровку гиперпараметров и при необходимости запустите повторный цикл обучения с обновленной конфигурацией.
👉 Для создания и корректировки учебных работ: Автор24
Оценка результатов и проверка качества
Оценка результатов и проверка качества нейросети — этап не менее значимый, чем само обучение. После того, как модель прошла тренировку на ваших данных, её необходимо протестировать на новых, ранее не использованных примерах. Это поможет понять, насколько эффективно она решает поставленные задачи и не переобучилась ли на тренировочную выборку. Важные метрики могут отличаться в зависимости от типа задачи: для классификации, например, часто используются точность, полнота, F1-мера. Для комплексной оценки качества полезно применять следующие подходы:
- Разделение данных на обучающую, валидационную и тестовую выборки для объективной проверки модели на реально "не виденных" данных;
- Анализ ошибок — изучение наиболее частых заблуждений сети, чтобы выявить слабые места;
- Визуализация результатов: графики confusion matrix, ROC-кривой, примеры успешных и ошибочных прогнозов.
Такая детальная проверка поможет не только убедиться в работоспособности нейросети, но и сделать выводы, что и как стоит улучшить в будущем.👉 Сервис для создания текстов и изображений: AiWriteArt
Оптимизация и дообучение модели
Оптимизация обучения на ваших данных начинается с подготовки данных и выбора базовых гиперпараметров. Выбор оптимизатора влияет на скорость и стабильность схождения: чаще всего применяют Adam или AdamW для сложных сетей, а SGD с моментумом может быть эффективным на задачах с большим количеством данных. Затем настраивают расписание обучения: начальную скорость, шаги снижения и, при необходимости, warmup, чтобы избежать резких скачков градиентов в начале тренировки.
Для контроля переобучения применяют регуляризацию и нормализацию: весовую регуляризацию (L2), дропаут и пакетную нормализацию, а также экспериментируют с использованием смешанной точности (mixed precision) для ускорения вычислений на современных устройствах. Размер батча и политика данных влияют на стабильность градиентов и общую скорость обучения.
- Выбор оптимизатора: Adam/AdamW, SGD с momentum
- Настройка скорости обучения: начальное значение, планировщик, warmup
- Регуляризация: L2-регуляризация, дропаут
- Смешанная прецизия: AMP на GPU
После базовой оптимизации переходим к дообучению и адаптации под ваши задачи. В зависимости от объема данных и близости Domain, можно применить transfer learning: заморозить нижние слои и дообучать верхние, либо полностью провести тонкую настройку всей сети. Важна настройка разных скоростей обучения для разных частей модели: более высокий LR у новых слоев и меньший у базовых, чтобы сохранить общие представления. Также полезна продуманная аугментация и соответствующая предобработка данных, учет баланса классов и нормализация входов, что снижает смещение во время обучения. Регулярно оценивайте метрики на валидации, следите за переобучением и используйте раннюю остановку, если улучшения не происходят. В качестве практических шагов:
- Заморозка слоёв и поэтапное распознавание (freeze/unfreeze)
- Разделение LR для разных частей модели
- Аугментация и дообучение на близком домене
- Мониторинг метрик и ранняя остановка
👉 Быстрое решение задач и получения информации через Telegram: StudGPT
Интеграция обученной нейросети в рабочий процесс
Интеграция обученной нейросети в рабочий процесс является важным шагом для повышения эффективности бизнеса и оптимизации задач. Основные этапы этого процесса включают адаптацию нейросети к текущим рабочим условиям, создание пользовательских интерфейсов для взаимодействия с нейросетью и тестирование ее в реальном времени. Важно, чтобы команда, использующая нейросеть, понимала, как она функционирует и могла быстро реагировать на возможные проблемы.
Для успешной интеграции нейросети в рабочий процесс необходимо учитывать несколько ключевых факторов:
- Совместимость с существующими системами и программным обеспечением.
- Наличие достаточного объема данных для постоянного обучения и обновления модели.
- Обучение сотрудников, которые будут взаимодействовать с нейросетью.
- Постоянный мониторинг результатов работы нейросети и внесение корректив при необходимости.
Таким образом, интеграция нейросети — это не просто использование готового решения, а динамичный процесс, требующий внимания и постоянного улучшения.
👉 Для генерации текстов, картинок и решения задач: RuGPT
Часто задаваемые вопросы
Как выбрать подходящую архитектуру нейросети для своих данных?
Выбор архитектуры зависит от типа задачи и данных. Для изображений обычно используют сверточные нейросети (CNN), для текстов — рекуррентные сети (RNN) или трансформеры. Анализируйте особенности ваших данных и цели, чтобы подобрать оптимальную архитектуру.
Как подготовить данные для обучения нейросети?
Данные нужно очистить, нормализовать и, при необходимости, размечать. Важно разбить данные на обучающую, валидационную и тестовую выборки. Также может потребоваться аугментация данных для улучшения обобщающей способности модели.
Как настроить гиперпараметры нейросети под свою задачу?
Основные гиперпараметры — скорость обучения, количество слоев, размер батча, функция активации и др. Их настройка проводится методом перебора, автоматизированного поиска (например, Grid Search) либо с использованием специализированных библиотек. Важно контролировать метрики на валидационной выборке.
Как избежать переобучения модели на своих данных?
Для борьбы с переобучением применяют регуляризацию (например, Dropout), увеличивают данные с помощью аугментации, используют раннюю остановку обучения по валидационной метрике и контролируют сложность модели.
Как проверить и улучшить качество обученной нейросети?
Оценивайте модель на отложенной тестовой выборке с помощью метрик, соответствующих вашей задаче (точность, F1, RMSE и др.). При необходимости дообучайте модель, корректируйте архитектуру или улучшавайте качество данных.