
В эпоху нейросетей озвучивание видео перестало быть роскошью и стало доступно каждому. В этой статье мы разберём, как озвучить видео с помощью нейросети бесплатно и как получить качественный результат без лишних затрат. Здесь мы сравним различные подходы, подскажем, какие инструменты стоит выбрать, как подготовить текст и как довести озвучку до высокого уровня. Вы узнаете, чем нейросетевой синтез голоса отличается от традиционных методов и какие ограничения существуют. Также затронем вопросы лицензирования и безопасности данных при использовании онлайн-сервисов.
Далее пошагово опишем процесс: подобрать сервис с бесплатным планом, загрузить или ввести сценарий, сгенерировать озвучку и экспортировать её в нужном формате. Расскажем, как проверить естественность произношения, настроить параметры голоса (тон, темп, паузы) и синхронизировать речь с видеорядом. Поделимся практическими советами по улучшению качества: минимизировать шум, выбирать нейронный голос, подбирать озвучку под стиль контента и язык аудитории. В конце предложим экономные варианты: как обходиться без платных подписок, какие бесплатные сервисы и открытые модели можно использовать без нарушения лицензионных условий.
Полезные ИИ сервисы:
- 🎓 Онлайн сервис помощи ученикам: Кампус
- 🏫 Работает без VPN: Study AI
- 📈 Сервис ChatGPT, DALL-E, Midjourney: GoGPT
- 🏆 Платформа для общения с ChatGPT: GPT-Tools
- 💡 Для создания и корректировки учебных работ: Автор24
- 📚 Сервис для создания текстов и изображений: AiWriteArt
- ⌛ Быстрое решение задач и получения информации через Telegram: StudGPT
- 📖 Для генерации текстов, картинок и решения задач: RuGPT
- ✏️ Для создания контента: текстов, изображений и SEO-материалов: RoboGPT
- ⏳ Для общения, генерации текстов и решения задач, доступный без VPN: ChatGPT
Выбор подходящей нейросети для озвучивания
Выбор подходящей нейросети для озвучивания видео является ключевым моментом в процессе создания качественной аудиодорожки. На сегодняшний день существует множество алгоритмов и платформ, предоставляющих услуги синтеза речи. При выборе нейросети стоит обратить внимание на такие параметры, как качество звучания, наличие поддержки различных языков и акцентов, а также возможность настройки эмоционального окраса голоса. Некоторые популярные инструменты включают Google Text-to-Speech, IBM Watson Text to Speech и специализированные стартапы, такие как Descript и Speechelo.
Кроме того, важно учитывать легкость интеграции выбранного решения с вашими рабочими процессами. Например, если вы планируете обрабатывать большие объёмы видео, стоит рассмотреть API, открывающие доступ к мощным вычислительным ресурсам, которые позволяют автоматически генерировать озвучку. Также не лишним будет проверить наличие бесплатных планов или тестовых периодов, что поможет вам оценить функционал и качество озвучивания перед тем, как сделать окончательный выбор.
👉 Онлайн сервис помощи ученикам: Кампус
Подготовка видео для обработки
Подготовка видео к обработке нейросетью начинается с выбора форматов и параметров файла, чтобы обеспечить стабильную работу модели и предсказуемый результат. Проверьте оптимальные разрешение и частоту кадров: чаще всего достаточно 1080p или 720p при 24–30 кадрах в секунду, кодек H.264 или HEVC и аудиокодек AAC или PCM. Важно привести видеоряд к единому стилю и удалить лишние переходы, а также очистить аудиодорожку от шумов, нормализовать громкость и привести её к одинаковому уровню по всем фрагментам. Не забывайте проверить права на материалы и сохранить структуру проекта, чтобы можно было безопасно обрабатывать и публиковать готовый материал.
Далее переходите к подготовке текстовой основы и таймкодов для синхронизации: подготовьте сценарий или субтитры, разделите текст на фрагменты и сопоставьте каждому фрагменту ожидаемую длительность, чтобы нейросеть могла точно подогнать речь под движения губ. Экспортируйте аудиоформат для нейросети в качественном виде, чаще всего WAV 16‑бит 44.1 кГц (или 48 кГц), чтобы сохранить четкость произнесения. Если планируется полностью заменить голос, отключите оригинальную дорожку и сохраните её отдельно; сделайте резервную копию проекта и всех исходников. Такой подход ускоряет озвучивание и снижает риск расхождения речи и видео.
👉 Работает без VPN: Study AI
Загрузка и анализ аудиоконтента
Для начала работы с озвучкой через нейросеть необходимо загрузить аудиоконтент, который будет использоваться в качестве основы для озвучивания видео. Это может быть либо готовый звуковой файл, либо запись голоса, которую можно загрузить с устройства или прямо с помощью встроенного микрофона. Важно, чтобы аудиозапись была высокого качества, без посторонних шумов и помех, чтобы нейросеть могла корректно распознать речь и синтезировать естественный голос. Современные сервисы часто поддерживают различные форматы файлов, такие как MP3, WAV и OGG, что обеспечивает удобство загрузки.
После загрузки аудиоконтента происходит его автоматический анализ – ключевой этап для качественной озвучки. Нейросеть распознает интонации, паузы, ударения и особенности произношения, что помогает создать максимально естественную озвучку. Анализ включает следующие шаги:
- распознавание речи и преобразование в текст,
- анализ эмоциональной окраски и тембра голоса,
- коррекция ошибок и шумов,
- подготовка данных для синтеза новой аудиодорожки.
Благодаря этому процессу, итоговая озвучка звучит живо и понятно, что особенно важно при создании обучающих и презентационных видео.
👉 Сервис ChatGPT, DALL-E, Midjourney: GoGPT
Генерация голосовой дорожки с помощью нейросети
Генерация голосовой дорожки с помощью нейросети позволяет превратить текстовый сценарий в звучащую речь с различными голосами и стилями. Современные нейросетевые модели анализируют контекст, интонацию и паузы, чтобы синтез звучания был близким к человеческой речи. Чтобы озвучить видео действительно качественно, важно заранее подготовить текст, указать желаемый голос (язык, акцент, пол, характер), а также продумать темп и длительность реплики. На этапе подготовки полезно разбить длинные фрагменты на смысловые блоки и определить места для пауз и эмфазы, чтобы голос звучал синхронно с монтажом и ритмом ролика.
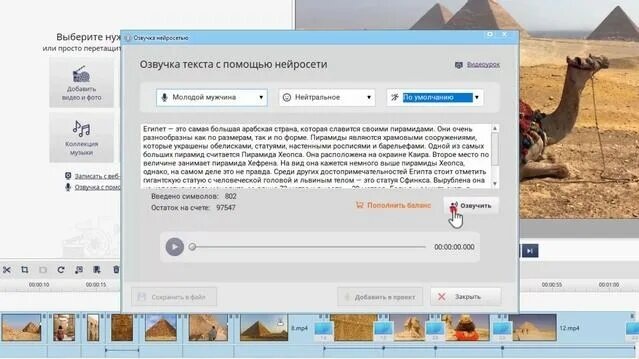
Дальше переходим к настройке и использованию нейросети: выберите платформу или модель, задайте параметры голоса и стиль, сгенерируйте черновой трек и затем подгоните под длительность видео при помощи аудиоредактора. Важно учитывать ограничения по лицензии на синтезированную речь и возможность нейросети поддерживать нужный язык/акцент. Ниже приведены ориентировочные варианты и подходы для бесплатной озвучки:
- Coqui TTS — открытая локальная платформа, поддерживает несколько языков и настраиваемые голоса
- Mozilla TTS — открытый проект с активной документацией и возможностью доработки
- Google Text-to-Speech / Google Cloud TTS — есть бесплатный уровень и кредиты на начальной стадии
- Microsoft Azure Neural Voices — бесплатный уровень и пробные кредиты
- Descript Overdub или ElevenLabs — коммерческие сервисы с ограничениями бесплатного доступа
После генерации можно заняться пост-обработкой: шумоподавление, нормализация громкости, подстройка пауз, дыхания и темпа, а затем экспорт в нужном формате и синхронизация с видеорядом.
👉 Платформа для общения с ChatGPT: GPT-Tools
Синхронизация озвучки с видеорядом
Синхронизация озвучки с видеорядом — ключевой этап при создании качественного видео с помощью нейросетей. Точность совпадения аудио с движением губ и выражениями героев позволяет добиться максимальной естественности и погружения зрителя в контент. Для этого важно правильно настроить временные метки и учесть особенности ритма и интонации речи, чтобы голос звучал плавно и органично. Нейросети, используемые для озвучки, часто предоставляют инструменты для автоматической подгонки аудиодорожки под видео, что значительно облегчает работу и сокращает время монтажа.
Для эффективной синхронизации рекомендуется придерживаться следующих шагов:
- Использовать скрипты или субтитры для точного определения временных промежутков озвучивания;
- Проверять и корректировать автонастраиваемые параметры синхронизации в интерфейсе нейросети;
- Проводить тестовые прослушивания и при необходимости вносить правки вручную;
- Обращать внимание на плавность переходов, особенно в сценах с динамичным диалогом или изменением темпа речи.
Такой подход гарантирует, что озвучка будет естественной, а видео — профессионально оформленным, что особенно важно при создании обучающих, рекламных или развлекательных материалов.
👉 Для создания и корректировки учебных работ: Автор24
Редактирование и корректировка озвучки
После генерации озвучки нейросеткой процесс редакции начинается с проверки соответствия речи кадрам. Слушайте внимательно ритм, паузы, ударения, и исправляйте произношение слов, которых нейросеть могла неправильно произнести. Важна плавность чтения, чтобы речь не шла рывками и не звучала механически. Затем подгоняйте темп: если сцена длинная, можно увеличить паузы или, наоборот, ускорить фрагменты с быстрыми диалогами. Также следите за естественностью дыхания и отсутствием лишних шумов.
- Синхронизация с кадрами и артикуляцией губ
- Корректировка произношения и ударений
- Настройка темпа, пауз и динамики
- Удаление шумов и артефактов нейросети
После корректировок переходите к финальному аудиопрогону: прослушайте озвучку в связке с видеорядом и устраните любые несостыковки, проверьте громкость по общему уровню и динамику, чтобы голос не перегружал звук. Сделайте финальные правки: подстройте паузы под монтажные сцены, добавьте вкусовые дыхания, при необходимости примените легкое эквалайзирование и подавление шумов. Затем экспортируйте финальный файл с правильной кодировкой и форматами, сохраните проект и добавьте метаданные, субтитры и синхронные подписи, чтобы конечный материал был готов к публикации.
- Проверка громкости и баланса по всей дорожке
- Финальные правки пауз под монтаж и дыхание
- Экспорт в нужном формате и сохранение версий
- Добавление субтитров, метаданных и титров
👉 Сервис для создания текстов и изображений: AiWriteArt
Сохранение и экспорт финального видео
Когда вы завершили процесс озвучивания видео через нейросеть, следующим шагом становится сохранение проекта для дальнейшей работы и экспорт готового видеофайла. Обычно платформы для озвучки позволяют выбрать формат экспортируемого файла — это могут быть MP4, AVI или другие стандартные варианты, подходящие для публикации в социальных сетях или на видеохостингах. Сам процесс экспорта не занимает много времени: нужно указать нужные параметры качества и путь для сохранения.
Если вы планируете использовать видео на разных платформах, обратите внимание на требования к разрешению и кодекам. Зачастую сервисы предлагают дополнительные настройки, такие как сжатие, выбор битрейта и даже автоматическую оптимизацию под YouTube или TikTok. При экспорте стоит выбрать подходящий вариант:
- Высокое качество для просмотра на больших экранах или профессиональной презентации;
- Сжатый файл для быстрой загрузки и экономии места в облаке или на устройстве.
👉 Быстрое решение задач и получения информации через Telegram: StudGPT
Советы по улучшению качества бесплатной нейроозвучки
Для улучшения качества бесплатной нейроозвучки в видео важно выбрать правильные настройки и инструменты. Начните с выбора нейросети, которая предлагает высокое качество синтеза речи. Обратите внимание на наличие вариантов для настройки тембра, скорости и интонации. Эти параметры могут значительно повлиять на восприятие озвучки. Также стоит предварительно подготовить текст, убрав любые лишние слова или сложные конструкции, чтобы сделать его более естественным для озвучки.
Кроме того, можно использовать следующие советы для повышения качества звука:
- Тщательно выбирайте языковую модель, исходя из контекста и целевой аудитории.
- Добавляйте паузы в нужных местах для обеспечения естественности речи.
- Используйте фоновые звуковые эффекты, чтобы скрыть недостатки в озвучке и улучшить общее восприятие видео.
- Тестируйте различные варианты озвучки, чтобы найти наиболее подходящий для вашего контента.
👉 Для генерации текстов, картинок и решения задач: RuGPT
Часто задаваемые вопросы
Как бесплатно озвучить видео с помощью нейросети?
Можно использовать бесплатные открытые модели TTS, запущенные локально или в облаке (например Coqui TTS или Mozilla TTS) через Google Colab или на своем ПК. Подготовьте текст сценария, выберите голос и параметры модели, сгенерируйте аудиодорожку в формате WAV и затем объедините её с видео с помощью ffmpeg или любого редактора. В итоге получится полностью бесплатная озвучка.
Какие бесплатные сервисы и программы подойдут для озвучивания через нейросеть?
Подойдут открытые проекты Coqui TTS и Mozilla TTS, которые можно запустить локально или в облаке. Также можно использовать готовые Colab-ноутбуки с преднастройками TTS. Важно учесть требования лицензий на модели и ограничение по вычислениям в бесплатных средах, а затем экспортировать аудио и собрать его с видео.
Как выбрать голос и настроить интонацию для нужного видео?
Обратите внимание на доступность языков и голосов, естественность произношения и качество озвучки. При необходимости используйте SSML для управления паузами, ударением и скоростью речи. В настройках модели можно регулировать скорость, ударение, паузы и тембр, чтобы получить нужный характер голоса и подходящий темп.
Как синхронизировать озвучку с видеорядом?
Используйте текст с таймкодами или инструмент для выравнивания речи (forced alignment), например Aeneas, чтобы привязать слова к конкретным моментам видео. Затем экспортируйте аудио отдельно и с помощью ffmpeg или редактора видео замените дорожку, подгоняя длительность под сцену и при необходимости редактируя паузы и темп.
Какие советы по подготовке текста и постобработке аудио помогут получить качественную озвучку?
Пишите понятно и коротко, используйте знаки препинания для управления паузами. Разделяйте длинные фразы на более короткие. После генерации проверьте аудио на шумы и проверьте частоту дискретизации (желательно 22–48 кГц). Применяйте легкую компрессию и эквализацию, чтобы выровнять уровень громкости и четкость голоса, и удалите лишние шумы перед финальным монтажом.