
В последние годы нейросети стали неотъемлемой частью множества технологий и приложений, от обработки изображений до создания текстов. Они предоставляют уникальные возможности для решения сложных задач и анализа больших объемов данных. Однако для многих это остается загадкой, так как процесс создания и обучения нейросети может показаться сложным и запутанным. В данной статье мы подробно рассмотрим, как создать нейросеть с нуля, предоставляя пошаговое руководство, которое поможет вам освоить этот захватывающий процесс.
Наша цель — сделать обучение доступным и понятным для каждого, даже если у вас нет глубоких знаний в области программирования или математики. Мы обсудим основные компоненты нейросетей, такие как слои, функции активации и алгоритмы обучения, и, кроме того, предложим практические примеры и схемы. Вы узнаете, какие инструменты и библиотеки могут сделать вашу работу более эффективной, а также получите представление о важности предварительной обработки данных. В результате вы сможете самостоятельно создать и обучить свою первую нейросеть, что откроет перед вами новые горизонты в мире искусственного интеллекта.
Полезные ИИ сервисы:
- 🧠 Онлайн сервис помощи ученикам: Кампус
- 📊 Работает без VPN: Study AI
- ✏️ Сервис ChatGPT, DALL-E, Midjourney: GoGPT
- ⏳ Платформа для общения с ChatGPT: GPT-Tools
- 📚 Для создания и корректировки учебных работ: Автор24
- 💡 Сервис для создания текстов и изображений: AiWriteArt
- ✅ Быстрое решение задач и получения информации через Telegram: StudGPT
- 📐 Для генерации текстов, картинок и решения задач: RuGPT
- 📖 Для создания контента: текстов, изображений и SEO-материалов: RoboGPT
- ⌛ Для общения, генерации текстов и решения задач, доступный без VPN: ChatGPT
Основы нейросетей: ключевые понятия и принципы работы
Нейросети — это математические модели, вдохновлённые структурой и работой человеческого мозга. Они состоят из множества связанных между собой узлов или «нейронов», которые обрабатывают информацию через последовательные слои. Каждый нейрон получает входные данные, применяет к ним весовые коэффициенты и функцию активации, после чего передаёт результат дальше. Благодаря такой архитектуре нейросети способны выявлять сложные зависимости в данных и обучаться на примерах, что делает их эффективными для задач классификации, регрессии и распознавания образов.
Основные принципы работы нейросети включают в себя:
- Инициализацию весов — случайное или преднамеренное задание начальных параметров;
- Прямое распространение — прохождение данных через все слои сети для получения результата;
- Обратное распространение ошибки — корректировку весов на основе разницы между предсказанным и истинным значением;
- Оптимизацию — минимизацию функции потерь с помощью алгоритмов, таких как градиентный спуск;
- Повторение цикла обучения до достижения желаемой точности модели.
Понимание этих ключевых понятий поможет создать собственную нейросеть с нуля и эффективно обучать её для решения конкретных задач.
👉 Онлайн сервис помощи ученикам: Кампус
Выбор инструментов и языков программирования для создания нейросети
При создании нейросети выбор инструментов и языков программирования играет ключевую роль и зависит от целей проекта, уровня подготовки разработчика и доступных ресурсов. Наиболее популярными языками для разработки нейросетей являются Python, благодаря своей простоте и огромному количеству библиотек и фреймворков, таких как TensorFlow, PyTorch и Keras. Эти инструменты предоставляют удобный интерфейс для быстрой реализации сложных моделей и их обучения, а также обеспечивают поддержку GPU для ускорения вычислений.
Кроме Python, используются и другие языки, в зависимости от специфики задачи и требований производительности. Например, C++ часто применяется для написания высокопроизводительного кода и интеграции нейросетей в промышленные приложения. Важно учитывать следующие критерии при выборе инструментов и языков:
- наличие и качество библиотек для глубокого обучения;
- легкость освоения и поддержки кода;
- возможность масштабирования и интеграции;
- сообщество и документация;
- требования к скорости и ресурсам.
👉 Работает без VPN: Study AI
Подготовка данных: сбор, очистка и форматирование для обучения
Подготовка данных начинается с определения источников и состава датасета. Важно собрать достаточное количество примеров, обеспечить разнообразие и корректность аннотаций, а также учесть лицензионные ограничения и правовые аспекты использования данных. При работе с реальными данными полезно рассмотреть синтетические данные или аугментацию, чтобы восполнить редкие случаи. Перед началом обучения стоит продумать разметку и структуру данных: отделение признаков от целей, единообразные форматы хранения и корректное разделение на обучающую, валидационную и тестовую выборки.
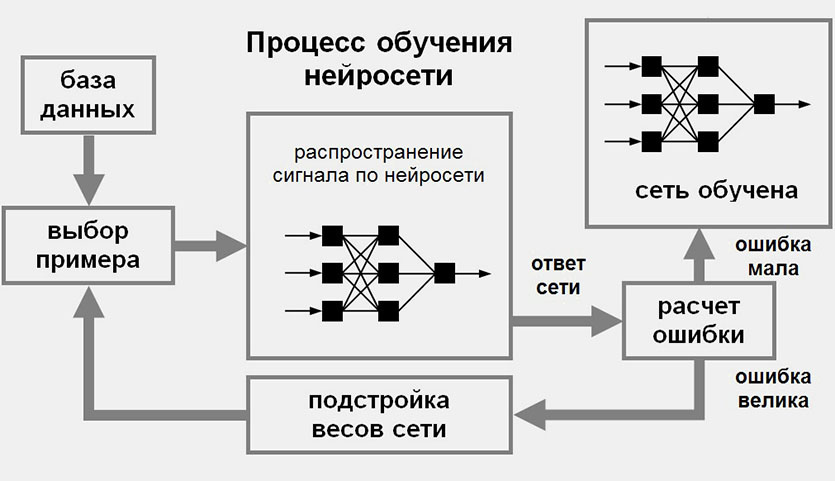
Для воспроизводимости полезно фиксировать источники данных, версии наборов и параметры препроцессинга. Рассмотрите следующие моменты:
- Источник данных и лицензии
- Качество и единообразие аннотаций
- Объем и разнообразие примеров
- Методы синтетического увеличения данных
- Этические и правовые ограничения
Очистка и форматирование данных превращают сырые примеры в пригодный для обучения набор. Начните с удаления дубликатов и устранения шумов, заполнения пропусков и приведения единиц измерения к одному стандарту. Далее переходите к нормализации и кодированию признаков: числовые признаки приводите к единому масштабу, категориальные — к one-hot кодированию или эмбеддингам. Важна последовательная конвертация данных в формат, ожидаемый вашей моделью (например, тензоры для PyTorch или матрицы NumPy) и фиксация этапов препроцессинга для воспроизводимости. Затем выполните разбиение на обучающую, валидационную и тестовую выборки и настройку пайплайнов для генерации данных во время обучения. Ниже приведен упрощенный набор этапов подготовки:
- Удаление дубликатов и шумов
- Обработка пропусков
- Унификация единиц измерения и форматов
- Нормализация числовых признаков
- Кодирование категориальных признаков
- Формирование наборов train/val/test
Такой подход обеспечивает устойчивость обучения и снижает риск переобучения на конкретном источнике данных.
👉 Сервис ChatGPT, DALL-E, Midjourney: GoGPT
Проектирование архитектуры нейросети: выбор типа и структуры слоев
Проектирование архитектуры нейросети начинается с понимания задачи и данных: какие признаки доступны, какая цель и какие ограничения по памяти и времени существуют. Выбор типа сети во многом предопределяет, какие зависимости в данных можно эффективно моделировать и какие операции будут наиболее выгодны по вычислениям. Ниже приведены основные типы слоев, которые часто встречаются на старте:
- Полносвязные слои (Dense/Linear) — универсальны для табличных данных и просты в настройке, но быстро расходуют параметры.
- Сверточные слои (Convolutional) — идеальны для локальных пространственных зависимостей и изображений, позволяют экономить параметры за счёт совместного использования весов.
- Рекуррентные слои (RNN/LSTM/GRU) — хорошо работают с последовательностями и временными данными, но требуют аккуратной настройки и могут быть медленными.
- Трансформеры (Self-attention) — мощны для длинных зависимостей и текста, требуют большого объёма данных и памяти, но сейчас стали стандартом во многих задачах.
- Обработочные и нормализационные слои (BatchNorm/LayersNorm, Dropout) — помогают стабилизировать обучение и бороться с переобучением.
Глубокие архитектуры дают возможность выделять сложные паттерны, но требуют больше данных и вычислительных ресурсов. Начинайте с простой конфигурации, затем оценивайте производительность и обобщение, добавляйте слои или отдельные блоки, вводите резидуальные соединения и регуляризацию, чтобы баланс между эффективностью и устойчивостью обучения был комфортен.
После выбора типа сети переходим к структурному проектированию слоёв: определяем форму входа, выбираем блоки обработки признаков и конструируем голову под задачу. Типичный каркас выглядит так: входной слой — блоки свёрток или линейных слоёв — слой агрегации или пулинга — глобальный слой представления — выходной слой (классификатор или регрессор). При проектировании помните о следующих принципах:
- Определите размер и форму входа, чтобы не терять данные и избежать несовместимости тензоров.
- Разбейте архитектуру на повторяемые блоки и применяйте паттерны: резидуальные соединения, пропуски, нормализацию.
- Учитывайте вычислительную стоимость и требования к памяти, выбирая параметры слоёв и размер батча.
- Планируйте регуляризацию заранее: Dropout, нормализацию, раннюю остановку.
- Проводите валидацию на отдельных подвыборках, чтобы понять, где сеть может недообучаться или переобучаться.
В итоге архитектура должна быть достаточно гибкой, чтобы адаптироваться к данным и задаче, не становясь тяжёлой и медленной для обучения.
👉 Платформа для общения с ChatGPT: GPT-Tools
Написание кода нейросети: от инициализации до прямого распространения
Начало написания кода нейросети заключается в правильной инициализации всех необходимых параметров. Сначала создаются структуры для хранения весов и смещений, которые будут оптимизироваться в процессе обучения. Обычно веса инициализируют случайными значениями в определённом диапазоне, чтобы обеспечить разнообразие сигналов на входах нейронов. Также важно определить архитектуру сети: количество слоёв, число нейронов в каждом и функции активации, которые будут использоваться для передачи информации дальше.
После инициализации приступают к реализации прямого распространения — ключевого этапа вычислений в нейросети. Оно включает поэтапный проход данных через каждый слой, преобразование входных сигналов с помощью весов, добавление смещений и применение функций активации для получения выходных значений. Процесс прямого распространения можно описать шагами:
- умножение входных данных на соответствующие веса;
- сложение результатов с величинами смещений;
- применение функции активации к полученным значениям;
- передача результатов на следующий слой или вывод сети.
Правильная реализация этих шагов позволяет нейросети эффективно обрабатывать данные и формировать предсказания для последующего обучения.👉 Для создания и корректировки учебных работ: Автор24
Обучение нейросети: оптимизация, функции потерь и алгоритмы градиентного спуска
Обучение нейросети строится вокруг идеи оптимизации – процесса поиска наилучших весов для всех связей внутри модели. Для этого используется функция потерь, которая измеряет разницу между предсказаниями нейросети и реальными значениями. Чем меньше функция потерь, тем точнее работает модель. К примеру, для задач классификации часто выбирают кросс-энтропию, а для регрессии – среднеквадратичную ошибку.
Алгоритмы градиентного спуска — основное средство для минимизации функции потерь и обучения нейросети. Суть алгоритма заключается в последовательном изменении весов в направлении наибольшего уменьшения ошибки. Существует несколько вариантов градиентного спуска:
- Стохастический градиентный спуск (SGD) – обновление весов после каждого примера.
- Пакетный (mini-batch) – обновление по небольшим группам данных.
- Адаптивные методы (Adam, RMSprop) – используют дополнительные оценки градиентов для ускорения и стабилизации обучения.
Выбор метода и параметров сильно влияет на скорость сходимости и итоговую точность нейросети.
👉 Сервис для создания текстов и изображений: AiWriteArt
Тестирование и валидация модели: оценка качества и предотвращение переобучения
Тестирование и валидация модели являются важнейшими этапами в процессе создания нейросети. На этих этапах проверяется, насколько хорошо модель работает с новыми, не виденными ранее данными. Для этого часто используется разделение набора данных на три части: обучающую, валидационную и тестовую. Обучающая выборка служит для обучения модели, валидационная - для настройки параметров и предотвращения переобучения, а тестовая - для окончательной оценки качества модели. Качество модели обычно оценивается по таким метрикам, как точность, полнота и F1-мера.
Чтобы предотвратить переобучение, можно применять различные методы регуляризации. Среди них стоит выделить:
- Использование методов ранней остановки (early stopping), когда обучение прекращается, если модель начинает показывать ухудшение на валидационной выборке.
- Применение дропаутов (dropout), которые случайным образом отключают отдельные нейроны во время обучения, тем самым предотвращая зависимость модели от конкретных параметров.
- Регуляризация L1 и L2, которые добавляют штраф за сложность модели в функцию потерь, что способствует более простым и обобщающим решениям.
Правильное использование этих методов помогает создать устойчивую нейросеть, способную адекватно работать даже с новыми данными.
👉 Быстрое решение задач и получения информации через Telegram: StudGPT
Развертывание и дальнейшее улучшение нейросети: практические советы и рекомендации
После успешного развертывания нейросети важно тщательно протестировать ее производительность и оптимизировать для получения наилучших результатов. Для этого стоит обратить внимание на использование различных методов валидации, таких как кросс-валидация, и оценивать точность модели на отложенном тестовом наборе данных. Также следует анализировать результаты, чтобы выявить возможные проблемы, например, переобучение, и принимать меры по их устранению.
Возможные шаги для улучшения нейросети могут включать:
- Настройка гиперпараметров, таких как скорость обучения и количество слоев;
- Использование регуляризации для уменьшения переобучения;
- Применение различных архитектур моделей для нахождения оптимального решения;
- Введение новых данных или увеличение объема обучающего набора для повышения качества обучения;
- Эксперименты с различными оптимизаторами и функциями потерь.
Дальнейшее развитие модели может включать внедрение систем мониторинга, чтобы отслеживать ее производительность в реальном времени, а также организовать автоматизированные процессы обновления модели по мере поступления новых данных. Таким образом, стоит задуматься о создании фреймворка для регулярной оценки и переобучения вашей нейросети, чтобы она оставалась актуальной и соответствовала последним требованиям. Взаимодействие с сообществом и обмен опытом может также принести новые идеи и подходы к улучшению модели.
👉 Для генерации текстов, картинок и решения задач: RuGPT
Часто задаваемые вопросы
С чего начать создание нейросети с нуля?
Определите задачу и тип данных, выберите целевую метрику, наметьте простую архитектуру (например, MLP или небольшую CNN) и спланируйте экспериментальный цикл: какие данные понадобятся, как вы будете обучать модель и какие инструменты использовать.
Как собрать и подготовить данные для обучения?
Соберите набор данных, разделите его на обучающую, валидационную и тестовую части, очистите данные, выполните нормализацию или стандартизацию признаков, при необходимости примените аугментацию и приведите данные к единообразному формату.
Как выбрать архитектуру и гиперпараметры?
Начните с простой архитектуры, подходящей задаче: для табличных данных — MLP, для изображений — маленькая CNN. Определите размер входа и выхода, количество слоёв, функции активации и размер батча. Выберите функцию потерь и скорость обучения, затем экспериментируйте: подбирайте параметры по наблюдаемым графикам обучения и по результатам валидации.
Как реализовать нейросеть с нуля без фреймворков?
Напишите базовые слои и операции в Python с использованием NumPy: прямой проход, вычисление потерь, обратное распространение и обновление параметров (градиентный спуск или его вариации). Постройте цикл обучения, ведите журнал метрик и постепенно расширяйте архитектуру по мере освоения.
Как организовать обучение и валидацию, чтобы не перегрузиться и понять результат?
Разделите данные на обучающие и валидационные наборы, отслеживайте графики потерь и метрик, применяйте регуляризацию (L1/L2, dropout), используйте раннюю остановку и нормализацию входов, подбирайте разумный размер батча и число эпох, сравнивайте обученную модель на тестовом наборе.