
При создании даже небольшого приложения для анализа данных, код имеет тенденцию быстро разрастаться. Вся логика, смешанная в одном файле app.py — загрузка данных, их обработка, построение графиков, элементы интерфейса — превращается в так называемый "код-спагетти". Его сложно читать, невозможно тестировать и практически нереально поддерживать или расширять.
Решение этой проблемы — модульная разработка. Это подход, при котором приложение разбивается на небольшие, независимые и взаимозаменяемые части (модули), каждая из которых отвечает за одну конкретную задачу.
## Почему модульность — это ключ к успеху? 🧠
- Читаемость и поддержка (Readability & Maintainability): Вместо одного файла на 1000 строк у вас будет несколько файлов по 50-100 строк. Найти нужный фрагмент кода, отвечающий за построение графика, становится тривиальной задачей — вы просто открываете plotting.py.
- Повторное использование кода (Reusability): Функцию загрузки данных из модуля data_loader.py можно использовать на разных страницах вашего Streamlit-приложения или даже в других проектах.
- Упрощение тестирования (Testability): Вы можете написать тесты для конкретной функции (например, для очистки данных) в полной изоляции от пользовательского интерфейса Streamlit. Это делает тесты надежнее и проще.
- Параллельная разработка (Teamwork): Один разработчик может работать над модулем визуализации, а другой — над модулем загрузки данных, не мешая друг другу.
## Правильная организация структуры проекта 📂
Хорошая структура — это фундамент вашего приложения. Для Streamlit-приложения по анализу данных идеально подходит следующая структура:
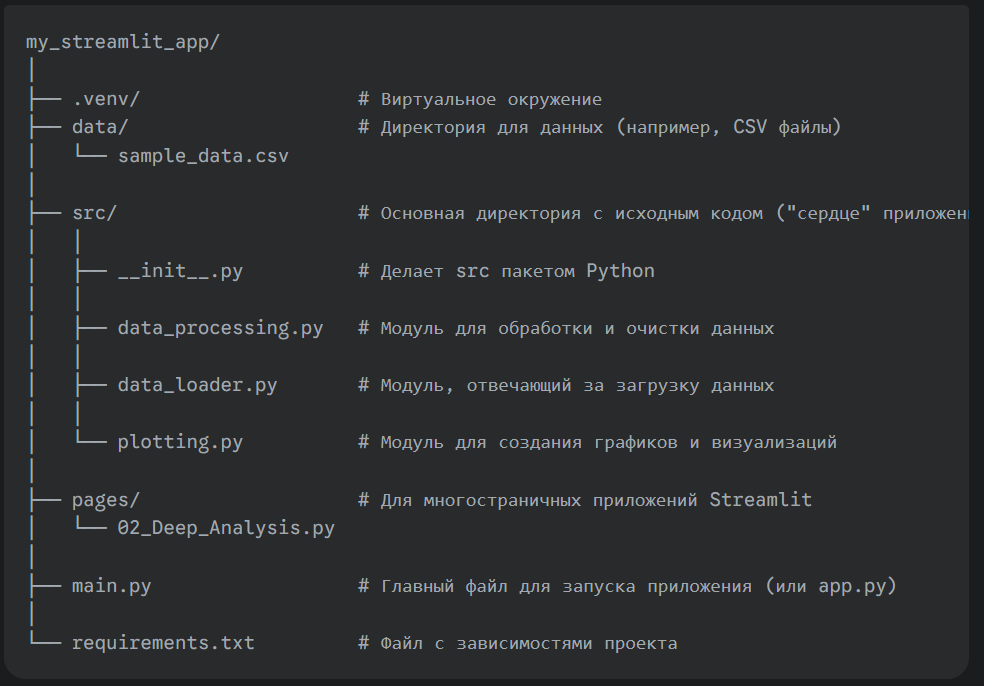
Объяснение каждого элемента:
- main.py: Это ваша точка входа. Этот файл должен быть "тонким". Его задача — импортировать функции из модулей в src/ и собрать из них пользовательский интерфейс с помощью команд st.title, st.button, st.dataframe и т.д. Он не должен содержать сложной логики обработки данных.
- src/: Здесь живет вся бизнес-логика.
data_loader.py: Содержит функции для загрузки данных из разных источников (CSV, Excel, API, база данных).
data_processing.py: Функции для очистки данных, создания новых признаков, фильтрации.
plotting.py: Функции, которые принимают на вход DataFrame и возвращают готовый график (например, объект Plotly или Matplotlib). - pages/: Встроенная функция Streamlit. Любой .py файл в этой директории автоматически становится отдельной страницей в вашем приложении.
- requirements.txt: Список всех библиотек, необходимых для работы проекта (streamlit, pandas, plotly и т.д.).
## Пример: Модульное приложение для анализа данных 📊
Давайте создадим простое приложение, которое загружает CSV-файл, показывает основную статистику и строит гистограмму для выбранного столбца.
requirements.txt
src/data_processing.py (Отвечает только за анализ)
src/plotting.py (Отвечает только за графики)
main.py (Собирает все вместе в интерфейс)
Как видите, main.py не выполняет никакой "грязной" работы. Он действует как дирижер, вызывая нужные функции из оркестра модулей в src/.
## Промпт для LLM (ChatGPT, Gemini и др.)
Чтобы заставить языковую модель сгенерировать код в таком стиле, нужен очень точный и структурированный промпт. Вот пример такого промпта.
**Роль:** Ты — опытный Python-разработчик, специализирующийся на создании поддерживаемых и масштабируемых веб-приложений для анализа данных с использованием Streamlit. Твой главный приоритет — чистота кода, следование принципу единственной ответственности (Single Responsibility Principle) и строгая модульная архитектура.
**Задача:** Создай код для простого Streamlit-приложения, которое выполняет следующие функции:
1. Загружает CSV-файл, предоставленный пользователем.
2. Выводит первые 10 строк загруженного датафрейма.
3. Позволяет пользователю выбрать один из числовых столбцов.
4. Строит и отображает диаграмму рассеяния (scatter plot) для двух выбранных пользователем числовых столбцов.
**Технологический стек:**
- Python 3.9+
- Streamlit
- Pandas
- Plotly Express
**Строгие ограничения и требования к архитектуре:**
1. **Модульная структура:** Весь код должен быть разделен на модули внутри директории `src/`. Главный файл `main.py` должен содержать только UI-логику и вызывать функции из модулей.
2. **Структура файлов:** Ты должен предоставить код для следующих файлов:
- `main.py` (точка входа, UI)
- `src/data_loader.py` (только функции для загрузки данных)
- `src/plotting.py` (только функции для создания графиков)
- `src/utils.py` (вспомогательные функции, например, для получения списка числовых столбцов)
- `requirements.txt` (файл зависимостей)
3. **Ограничение по длине модуля:** **КРАЙНЕ ВАЖНО!** Каждый файл с кодом Python (`.py`) не должен превышать **70 строк кода** (не считая пустых строк и комментариев). Это заставит тебя придерживаться принципа единственной ответственности.
4. **Чистота функций:** Функции должны быть "чистыми" — принимать данные как аргументы и возвращать результат. Они не должны полагаться на глобальные переменные. Используй аннотации типов (type hints).
5. **Кэширование:** Используй декоратор `@st.cache_data` для функции загрузки данных для оптимизации производительности.
**Формат вывода:**
Предоставь ответ в виде последовательности блоков кода. Каждый блок должен начинаться с полного пути к файлу (например, `src/data_loader.py`), за которым следует сам код.
Начинай генерацию.
Этот промпт четко определяет роль, задачу, структуру, технологии и, что самое важное, жесткие ограничения, которые заставляют модель следовать модульному подходу, а не сваливать все в один файл. Указание на ограничение количества строк — это мощный трюк, заставляющий LLM дробить логику на более мелкие функции и файлы.