Предварительная обработка данных (data preprocessing) — это, возможно, самый важный и трудоемкий этап в любом проекте по анализу данных или машинному обучению. Качество вашей модели или анализа напрямую зависит от качества данных, которые вы в неё подаете. Существует золотое правило: "Мусор на входе — мусор на выходе" (Garbage In, Garbage Out).
Этот гайд проведет вас через стандартный и логически выверенный процесс подготовки данных с использованием популярных библиотек Python, таких как Pandas, NumPy и Scikit-learn.
Общая последовательность шагов:
- Загрузка и первичный осмотр данных
- Очистка данных
Работа с пропущенными значениями
Обработка дубликатов
Коррекция типов данных
Анализ и обработка выбросов - Преобразование признаков (Feature Engineering & Transformation)
Создание новых признаков
Кодирование категориальных признаков
Масштабирование числовых признаков - Разделение данных на обучающую и тестовую выборки
Давайте разберем каждый шаг подробно.
Шаг 1: Загрузка и первичный осмотр данных 🚀
Что делаем?
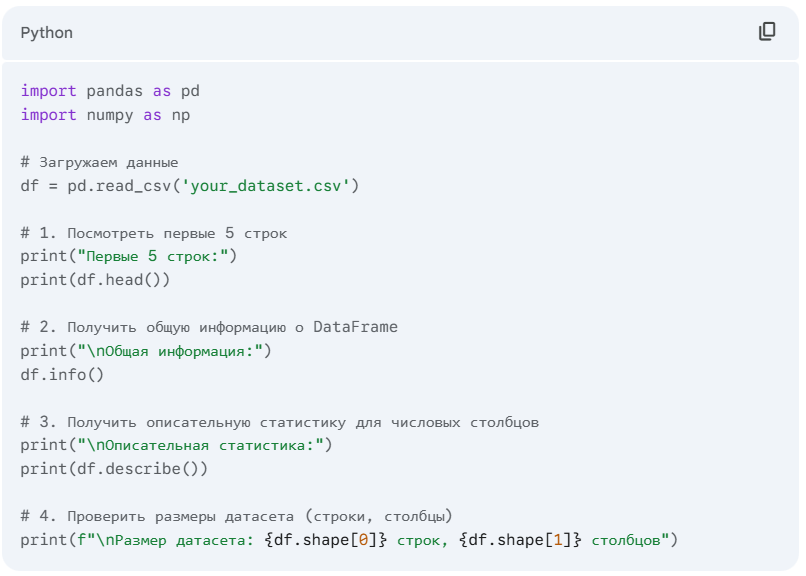
Первым делом мы загружаем наш набор данных (например, из CSV-файла) в структуру данных, удобную для работы, — Pandas DataFrame. Сразу после этого мы проводим беглый осмотр, чтобы понять, с чем имеем дело.
Код на Python:
Почему это важно?
Этот шаг — наша отправная точка. Он позволяет мгновенно ответить на ключевые вопросы:
- df.head(): Как выглядят данные? Какие у нас столбцы и какие значения они содержат?
- df.info(): Сколько у нас записей? Есть ли пропущенные значения (Non-Null Count)? Какие типы данных у каждого столбца (Dtype)? Это крайне важно, так как числовые данные, прочитанные как текст (object), не позволят проводить математические операции.
- df.describe(): Каковы основные статистические показатели (среднее, медиана, стандартное отклонение, мин/макс) для числовых признаков? Это может сразу указать на наличие выбросов или аномалий (например, если максимальный возраст человека — 200 лет).
Почему это первый шаг?
Невозможно начать чистить, анализировать или моделировать то, что еще не загружено и не изучено на самом базовом уровне. Это фундамент для всех последующих действий.
Шаг 2: Очистка данных 🧹
Это самый критичный этап, где мы исправляем все "недостатки" сырых данных.
а) Работа с пропущенными значениями (Missing Values)
Что делаем?
Находим столбцы с пропущенными значениями (NaN, None, NaT) и решаем, что с ними делать: удалить или заполнить (impute).
Код на Python:
Почему это важно?
Большинство алгоритмов машинного обучения не могут работать с пропущенными данными и выдадут ошибку. Пропуски могут исказить результаты анализа (например, при расчете среднего значения). Выбор стратегии (удаление или заполнение) зависит от количества пропусков и важности данных. Удаление большого количества строк может привести к потере ценной информации.
б) Обработка дубликатов (Duplicates)
Что делаем?
Находим и удаляем полностью идентичные строки.
Код на Python:
Почему это важно?
Дубликаты могут искусственно завысить "вес" определенных записей, что приведет к смещению в анализе и переобучению модели. Чаще всего они возникают из-за ошибок при сборе или объединении данных.
в) Коррекция типов данных (Data Types)
Что делаем?
Приводим столбцы к корректным типам данных (например, строки с числами — к int или float, даты — к datetime).
Код на Python:
Почему это важно?
Некорректный тип данных блокирует возможность проводить с ними соответствующие операции. Вы не сможете считать среднюю цену, если она хранится в виде текста, или извлекать год из даты, если это просто строка.
г) Анализ и обработка выбросов (Outliers)
Что делаем?
Находим аномально высокие или низкие значения, которые сильно отличаются от основной массы данных. Их можно визуализировать (например, с помощью boxplot) или найти с помощью статистических методов (например, межквартильный размах - IQR).
Код на Python:
Почему это важно?
Выбросы могут сильно искажать статистические показатели (особенно среднее) и негативно влиять на производительность многих моделей машинного обучения (например, линейной регрессии), "перетягивая" модель на себя.
Почему такая последовательность внутри очистки?
Логично сначала разобраться с дубликатами и пропусками, прежде чем исправлять типы данных или искать выбросы, так как предыдущие шаги могут повлиять на последующие. Например, после заполнения пропусков у вас может измениться распределение данных.
Шаг 3: Преобразование признаков (Feature Engineering & Transformation) 🛠️
После того как данные очищены, мы делаем их более "удобными" и "понятными" для модели.
а) Создание новых признаков (Feature Creation)
Что делаем?
Генерируем новые, более информативные признаки из существующих.
Код на Python:
Почему это важно?
Это один из самых креативных этапов. Хорошо продуманный новый признак может значительно улучшить качество модели, так как он может содержать в себе скрытую взаимосвязь, которую модель не смогла бы уловить из сырых данных.
б) Кодирование категориальных признаков (Categorical Encoding)
Что делаем?
Преобразуем текстовые категории в числа, так как модели работают с числами.
Код на Python:
Почему это важно?
Алгоритмы не понимают слова "Москва" или "Лондон". One-Hot Encoding создает новые бинарные столбцы для каждой категории, что идеально для номинальных данных. Label Encoding присваивает каждой категории уникальное число (0, 1, 2...), что подходит для данных с естественным порядком (например, "Низкий", "Средний", "Высокий").
в) Масштабирование числовых признаков (Numerical Scaling) ⚖️
Что делаем?
Приводим все числовые признаки к единому масштабу.
Код на Python:
Почему это важно?
Многие алгоритмы (например, градиентный спуск, KNN, SVM) чувствительны к масштабу признаков. Если один признак измеряется в миллионах (например, доход), а другой — в десятках (например, возраст), то первый признак будет доминировать при обучении модели. Масштабирование уравнивает их "в правах".
Шаг 4: Разделение данных ✂️
Что делаем?
Разделяем наш обработанный датасет на две части: одну для обучения модели (train), другую — для ее проверки (test).
Код на Python:
Почему это важно?
Это абсолютно критичный шаг для объективной оценки качества модели. Мы обучаем модель только на обучающей выборке (X_train, y_train). Затем мы проверяем, насколько хорошо она работает на данных, которые она никогда не видела — на тестовой выборке (X_test, y_test). Это позволяет понять, способна ли модель обобщать знания, а не просто "запомнить" обучающие примеры.
Почему это последний шаг? (Это очень важно!)
Вы должны разделять данные на train и test ДО того, как будете применять некоторые преобразования, особенно масштабирование или заполнение пропусков средним/медианой.
Причина — предотвращение утечки данных (Data Leakage).
- Пример: Если вы рассчитаете среднюю зарплату для заполнения пропусков по всему датасету, а потом разделите его, то информация из будущей "тестовой" выборки (которую модель не должна видеть) уже "просочилась" в вашу "тренировочную" выборку через это среднее значение. Модель получит несправедливое преимущество, и ее оценка на тесте будет завышенной и нереалистичной.
Правильная последовательность:
- Разделить данные на train и test.
- Настроить (fit) скейлер или импьютер только на train данных.
- Применить (transform) это настроенное преобразование и к train, и к test данным.
Таким образом, все параметры для преобразования (среднее, стандартное отклонение и т.д.) вычисляются исключительно на основе обучающих данных, что имитирует реальную ситуацию, когда новые данные поступают для предсказания.
Надеюсь, эта статья дала вам четкое и структурированное понимание процесса обработки данных!