Добрый день!
Сегодня мы с вами погрузимся в мир нейронных сетей в микроконтроллере.
Да, да. В микроконтроллер тоже можно всунуть нейронку, только мини.
И сейчас покажу как это сделать.
Начнём мы работу в среде Edge Impulse.
Edge Impulse — это ведущая платформа для разработки и развертывания искусственного интеллекта (ИИ) на периферийных устройствах (edge devices), которая предоставляет end-to-end решение для сбора данных, обучения моделей машинного обучения и их деплоя на различные устройства, от микроконтроллеров до мощных процессоров.
Начинаем с загрузки CSV файлов для обучения и тестирования нейронки:
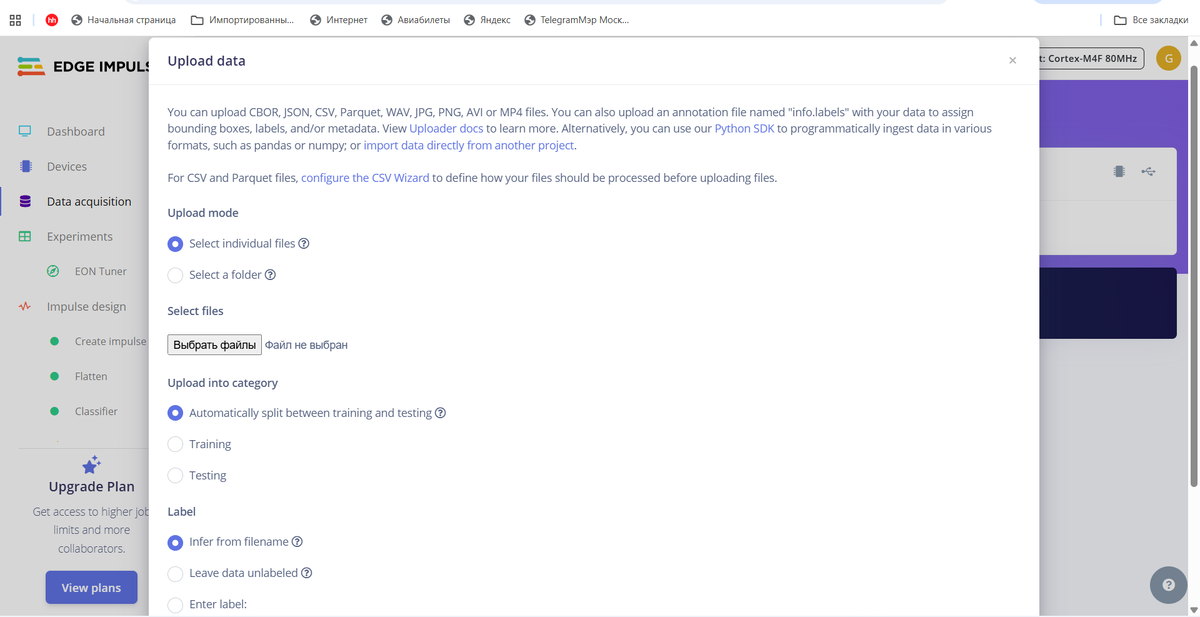
У нас появляется dataset, состоящий из файлов training и test. В том и том разделе я загрузил 4 файла с измерениями от микроконтроллера. Для training я использую 250 измерений, для test - 50, отличающихся на 10-15% от значений training файлов. Это нужно для лучшего теста модели нейронки.
Соотношение TRAIN/TEST SPLIT 83% / 17% является приемлемым.
Приступаем к созданию ИМПУЛЬСА.
импульс — это законченный проект или "рецепт", который включает в себя все этапы работы модели:
- Обработка входных данных (Data processing): извлечение признаков из сырых данных (например, преобразование аудио в спектрограмму или данных акселерометра в набор статистических features).
- Архитектура нейронной сети: сама модель, которая будет обучаться на извлеченных признаках.
- Настройки обучения: параметры, такие как скорость обучения, количество эпох и т.д.
- Постобработка: логика преобразования выхода модели в полезный результат (например, классификация).
В Times series data мы задаём следующие параметры:
Window size - размер окна в миллисекундах
Window increase - интервал между окнами в миллисекундах
Frequency - количество измерений за единицу времени. 1Hz - это значение в секунду.
Zero-pad data - это техника предобработки данных, при которой к исходному массиву данных добавляются нули для увеличения его длины до определенного размера.
Наша нейронка видит наши данные как временную диаграмму, которую для обучения делит на фрагменты (Window size), между которыми ставится интервал (Window increase), что бы не было наслоения фрагмента на фрагмент. В фрагменте длиной 20 000 мс у нас будет 20 измерений или 20 точек, потому что Frequency = 1Hz.
Далее идёт:
processing block (блок обработки) — это предварительно настроенный модуль или алгоритм, который выполняет специфический этап обработки или преобразования входных данных перед их подачей в модель машинного обучения.
На этом этапе мы обрабатываем RAW DATA (входные данные) или сырые данные для получения структурированных признаков, пригодных для обучения модели.
Примеры:
- Для аудио: спектрограммы, MFCC (Mel-Frequency Cepstral Coefficients).
- Для данных с датчиков: FFT (быстрое преобразование Фурье), фильтрация, статистические features (среднее, дисперсия).
- Для изображений: нормализация, изменение размера.
Здесь мы выбираем блок обработки в зависимости от нашей задачи:
Где:
Flatten (уплощение или сглаживание) - это операция преобразования многомерных данных (например, матрицы или тензора) в одномерный вектор.
Spectral Analysis (FFT) - Преобразовывает сигнал в частотный спектр для анализа
Spectogram — это визуальное представление спектра частот сигнала (например, звука или вибрации) в зависимости от времени. По сути, это "картинка", которая показывает, как частоты в сигнале изменяются с течением времени.
IMU - преобразует необработанные данные с акселерометра и гироскопа в информативные признаки (features), пригодные для обучения модели машинного обучения.
HR and HRV features - преобразует необработанные биосигналы в набор информативных числовых параметров (признаков), которые точно описывают состояние сердечно-сосудистой системы.
RAW DATA - это необработанные, "сырые" данные, которые напрямую поступают с сенсора (например, акселерометра, микрофона, датчика сердечного ритма) и подаются на вход блока обработки для преобразования в информативные признаки (features).
Следующий этап:
Learning Block (блок обучения) — это компонент в ML-платформах, который отвечает за создание, обучение и настройку модели машинного обучения на основе признаков, извлеченных из данных. Если Processing Block подготавливает данные, то Learning Block — это "мозг", который учится на этих данных и делает прогнозы.
🧠 Типы Learning Block в Edge Impulse:
- Классификация (Classification): Для задач категоризации (распознавание звуковых команд, видов активности, жестов).
- Обнаружение объектов (Object Detection): Для поиска и классификации объектов на изображении (YOLO, MobileNetSSD).
- Обнаружение аномалий (Anomaly Detection): Для выявления нестандартного поведения или отклонений (например, сбой в работе механизма).
- Регрессия (Regression): Для предсказания числовых значений (например, температуры или положения объекта).
Когда все блоки сконфигурированы мы сохраняем ИМПУЛЬС.
После сохранения импульса (Impulse) в Edge Impulse наш конвейер обработки данных и модель готовы, но это только середина пути. Дальнейшие шаги направлены на то, чтобы превратить этот импульс в работающее решение на устройстве.
Вот что нужно делать после сохранения импульса:
Обучение модели (Train Model)
- Что делать: На вкладке "Training" запустите процесс обучения, нажав соответствующую кнопку.
- Что происходит: Edge Impulse использует ваши размеченные данные и созданный импульс (processing block + learning block) для обучения нейронной сети.
- Результат: После завершения вы увидите метрики качества модели (точность, потери) и сможете проанализировать, насколько хорошо она работает.
Результат: ТОЧНОСТЬ 100% ПОТЕРИ 0 %
Тестирование модели (Test Model)
- Что делать: Перейдите на вкладку "Model testing" и запустите тестирование на отдельном наборе данных, который не использовался при обучении.
- Что происходит: Модель проверяется на новых данных, чтобы оценить ее способность к обобщению (убедиться, что она не переобучилась).
- Результат: Вы получаете объективную оценку точности модели на реальных данных.
И финишная прямая:
Развертывание модели (Deployment)
Это ключевой этап — перенос модели на устройство. На вкладке "Deployment" вам доступно несколько вариантов:
- Создание библиотеки для вашего устройства:
Выбираете тип вашего устройства (например, Arduino, Raspberry Pi, Linux).
Edge Impulse собирает готовую прошивку или библиотеку, которая содержит вашу модель и весь конвейер обработки данных.
Вы скачиваете архив и загружаете его на свое устройство. - Экспорт модели:
Можно экспортировать саму обученную модель (например, в формате .tflite для TensorFlow Lite или .onnx) для интеграции в ваше собственное приложение. - Развертывание в облако:
Вариант для более мощных устройств — развернуть модель как REST-API или контейнер Docker
Ну всё мы создали библиотеку, которую вставляем в код и прошиваем наше AIoT устройство!
#AIoT #IoT #AI #ИИ #DataScience #ЭлектроникаБудущего #Электроника #EdgeImpulse #TensorFlowLite