Привет! Хочу поделиться с вами нууу очень приятной новостью из мира ИИ, которая буквально взорвала интернет в последние недели. Google выпустил Gemini 2.5 Flash Image — инструмент для редактирования изображений, который может кардинально изменить то, как мы работаем с визуальным контентом.
Для тех, кто предпочитает сразу перейти к делу и не тратить время на длинные объяснения, я подготовил небольшой интерактивный гайдик для новичков по работе с моделью. Ссылку на приложение Вы найдете ЗДЕСЬ. В приложении помимо объяснения как работать с моделью в разделе Творческая студия доступен простой, но, как мне кажется, достаточно функциональный генератор и редактор изображений. Там же редактирование изображений, Inpaint и Outpaint-пока правда с танцами с бубном но думаю скоро и это исправят. Заходите, смотрите, не пожалеете.
Если вы заметите какие-либо недочеты или ошибки, пожалуйста, сообщите мне в личные сообщения в Telegram или в комментариях. Я обязательно их исправлю.
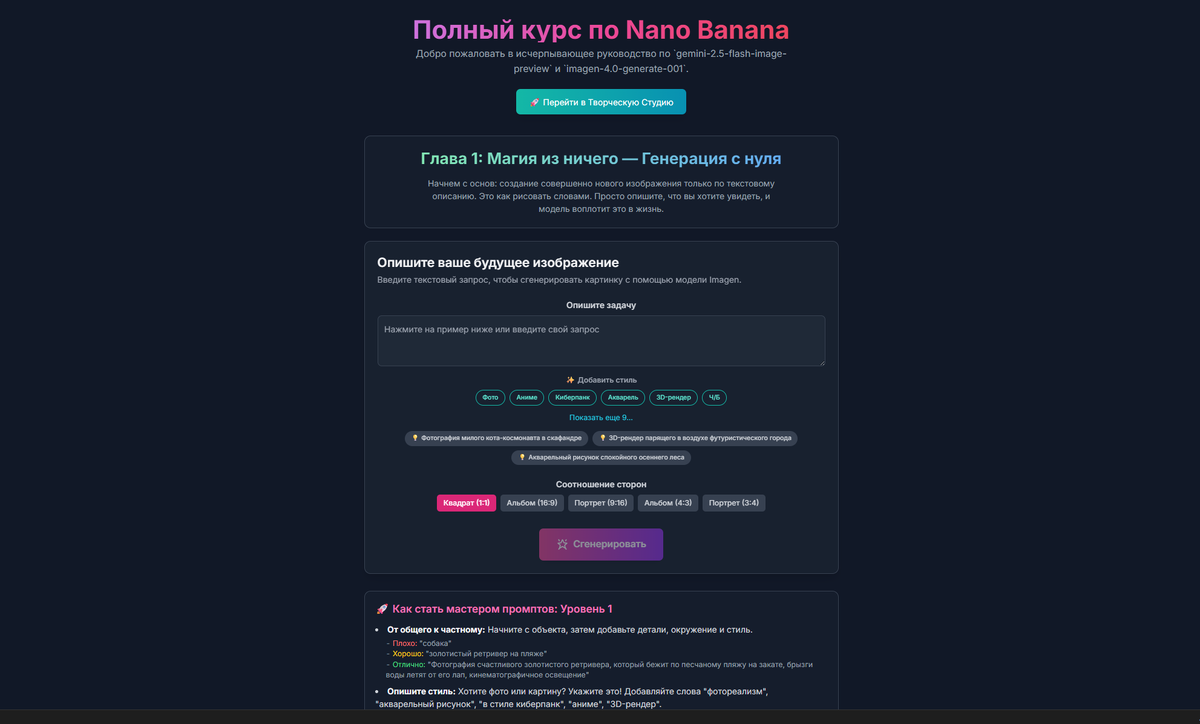
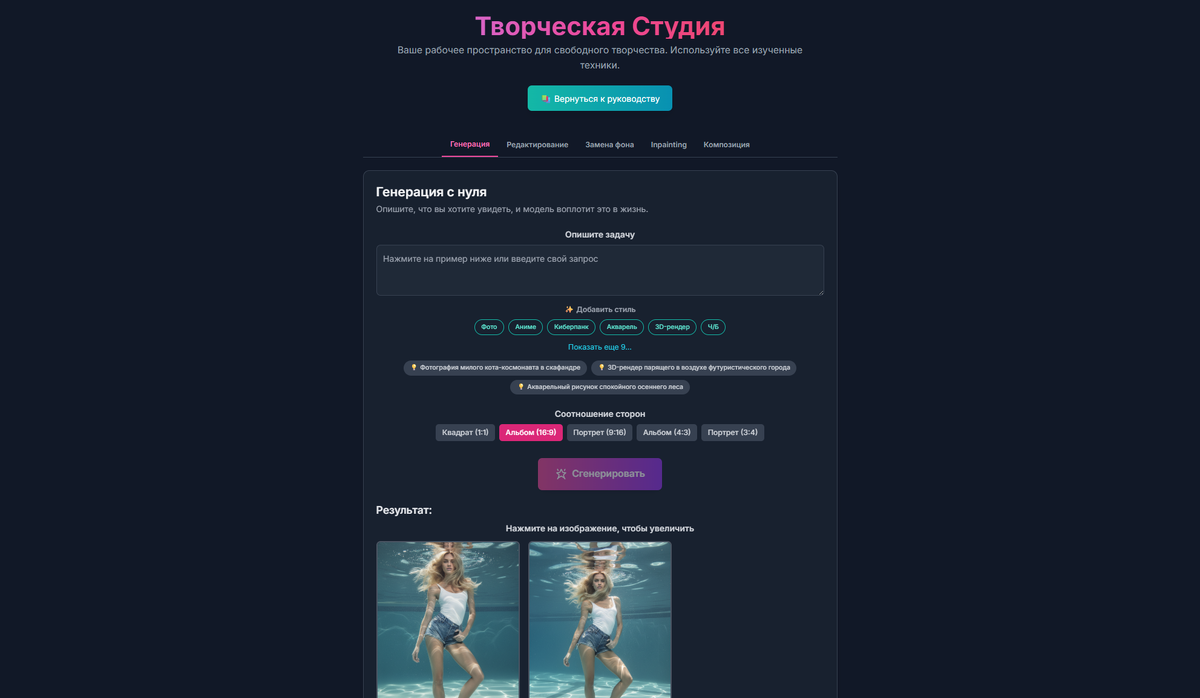
Ну а для тех кому интересно почитать с чего собственно все началось, продолжим. А началось всё довольно "драматично". На платформе LM Arena появился загадочный редактор изображений под кодовым названием "Nano Banana". Никто не знал, кто его создал, но результаты были просто ошеломляющими. Модель моментально взлетела на вершину рейтингов, оставив позади всех конкурентов с огромным отрывом.
Когда наконец раскрылось, что за "Nano Banana" стоит Google DeepMind, многих это не удивило — только такой гигант мог создать нечто подобное. Но самое интересное, что пользователи так полюбили оригинальное название, что многие до сих пор называют инструмент именно так.
Что делает эту модель особенной?
Главная фишка Gemini 2.5 Flash Image — это способность сохранять внешность людей в разных сценариях. Представьте: вы загружаете свою фотографию и просите показать себя в роли космонавта, повара или рок-звезды. Модель создаст совершенно новые изображения, но ваше изображение останется узнаваемым практически на каждом из них.
(Пример промпта: "Превратить этого человека в профессионального повара, работающего на современной кухне ресторана, сохраняя черты лица и характерные особенности внешности")
Раньше такое было возможно только с использованием сложных техник вроде FaceSwap, LoRA или DreamBooth, которые требовали технических знаний или времени на обучение. Теперь достаточно простой текстовой команды.
Умное понимание контекста
В отличие от многих других ИИ-генераторов, эта модель действительно понимает, что происходит на изображении. Можно сказать "убери шлем с этого космонавта" или "замени красную машину на синюю", и она точно поймёт, о чём речь, не затронув остальные элементы картинки.
(Пример промпта для редактирования: "Убрать шлем у космонавта, оставив все остальные элементы скафандра и фон без изменений")
Низкая цена
При стоимости около $0,039 за изображение, модель стоит в разы дешевле аналогичных решений. Для сравнения: многие конкурирующие сервисы берут в 10-15 раз больше за похожий функционал.
Где и как использовать
Для обычных пользователей
Google AI Studio — самый простой способ попробовать модель прямо сейчас. Пока что бесплатно (правда, с лимитами до 500 запросов в день, потом можно сменить аккаунт и продолжить свои эксперименты). Заходим, загружаем картинку и начинаем экспериментировать. Чтобы попасть на сервис, возможно, понадобится воспользоваться другим сервисом, который из трех букв. Вариантов много, некоторые из них есть у меня на Boosty и в Telegram (ссылки в конце статьи).
Приложение Gemini — работает как ChatGPT, только с изображениями. Загружаем фото и общаемся с ИИ, описывая нужные изменения естественным языком. Главное не ругайтесь, а то обидится и не будет с вами дружить :-) и если что, я вполне серьезно.
Для профессионалов
ComfyUI Integration — для тех, кто серьёзно занимается генерацией изображений. Есть специальная нода для интеграции в рабочие процессы. Требует платный Google Gemini API ключ, так как бесплатная версия не поддерживает генерацию изображений.
Альтернативные ноды:
- Visionatrix/ComfyUI-Gemini — более общие ноды для работы с Gemini API
- Official ComfyUI API Nodes — нативная поддержка через официальные API-ноды
Adobe Firefly Boards — Adobe уже добавила поддержку модели, правда, как премиум-функцию.
Где можно реально применить модель
Да где угодно. Дизайнеры теперь могут мгновенно примерять разные стили на моделей. Хотите посмотреть, как будет выглядеть коллекция в стиле 80-х, 90-х или в футуристическом ключе? Загружаете базовый образ и получаете множество вариаций за секунды.
(Пример промпта: "Превратить наряд этой модели в 3 разных стиля моды 1980-х годов: панк-рок, преппи, новая волна, сохраняя позу модели и черты лица")
Архитектура и дизайн интерьеров
Это просто мечта любого дизайнера интерьеров! Можно взять фото своей комнаты и попросить показать её в скандинавском стиле, лофте или классике. Модель сохранит планировку и расположение мебели, но полностью изменит атмосферу.
(Пример промпта: "Превратить эту гостиную в скандинавский минималистский стиль со светлой деревянной мебелью, белыми стенами, уютным текстилем и естественным освещением, сохраняя планировку комнаты, мебель, технику и расположение окон")
Архитекторы могут создавать фотореалистичные визуализации из простых чертежей. Нарисовали план — получили готовую 3D-визуализацию.
(Пример промпта: "Превратить этот архитектурный план в фотореалистичную 3D-визуализацию современного двухэтажного дома с большими окнами, современными материалами и ландшафтным садом")
Контент для социальных сетей
Блогеры и маркетологи уже активно используют модель для создания уникального контента. Можно сделать серию фотографий в разных локациях, не выходя из дома. Или создать персонажа для своего бренда и показывать его в разных ситуациях.
(Пример промпта: "Поместить этого человека в уютную кофейню с тёплым освещением, винтажным интерьером, паром от кофейной чашки, сохраняя черты лица и стиль повседневной одежды")
Реставрация и улучшение старых фотографий
У вас есть старые семейные фотографии с царапинами, пятнами или выцветшими цветами? Gemini 2.5 Flash Image справляется с реставрацией лучше многих специализированных программ. Может даже добавить цвет к чёрно-белым снимкам, сохранив историческую достоверность.
(Пример промпта: "Восстановить эту старую чёрно-белую семейную фотографию, убрав царапины, пятна пыли и разрывы, затем раскрасить её в исторически точные цвета для одежды и обстановки 1950-х годов")
Создание визуальных историй
Одна из самых крутых фишек — возможность создавать последовательности изображений с одними и теми же персонажами. Предположим вы пишете комикс или детскую книжку. Раньше нужно было либо рисовать самому, либо нанимать художника либо долго сидеть в ComfyUI с кучей нодов. Теперь достаточно описать сюжет и получить готовые иллюстрации с консистентными героями.
(Пример промпта: "Создать комикс из 4 панелей: 1) Юный волшебник находит магическую книгу в библиотеке, 2) Тот же волшебник произносит своё первое заклинание с летящими искрами, 3) Заклинание идёт не так и создаёт цветной хаос, 4) Волшебник смеётся, убирая магический беспорядок. Сохранить внешность персонажа во всех панелях.")
Seasonal трансформации
Хотите показать, как выглядит одно и то же место в разные времена года? Загружаете одну фотографию и просите создать варианты для весны, лета, осени и зимы. Получается потрясающая серия!
(Пример промпта: "Создать изображение из 4 панелей. Превратить эту сцену парка в четыре сезонных варианта: весна с цветущими цветами и свежей зелёной листвой, лето с пышной зеленью и ярким солнечным светом, осень с золотыми и красными опадающими листьями, и зима со снежными деревьями и скамейками")
Микс реальности и фантазии
Модель отлично справляется с созданием сюрреалистичных композиций. Можно объединить портрет человека с космическим пейзажем или поместить обычных людей в сказочные миры.
(Пример промпта: "Совместить этот портрет с сюрреалистичным космическим пейзажем, где человек парит среди туманностей и звёзд, а его отражение видно в множественных кристаллических поверхностях, которые фрагментируют реальность вокруг него")
Некоторые технические особенности, про которые стоит знать
Модель может обрабатывать до пяти изображений одновременно, создавая из них единую композицию. Это открывает массу возможностей для креативных экспериментов.
Понимание физики и логики
В отличие от многих ИИ-генераторов, Gemini 2.5 Flash Image довольно хорошо понимает, как устроен реальный мир. Тени падают правильно, отражения выглядят естественно, пропорции соблюдаются.
Пример промпта: "Поместить этого человека под воду в бассейне, обеспечив реалистичные эффекты преломления света в воде, правильное освещение, фильтрующееся сквозь воду, и естественную подводную физику движения волос и одежды")
Работа с текстом на изображениях
Модель может не только удалять текст с картинок, но и добавлять новый, сохраняя стиль и читаемость. Особенно полезно для создания мемов или рекламных материалов.
(Пример промпта: "Заменить существующий текст на вывеске этого магазина на 'Уютный Уголок Кафе', используя тот же стиль шрифта, цвет и освещение, как у оригинальной вывески, чтобы текст выглядел естественно интегрированным")
Поддержка разных форматов
Модель поддерживает множество соотношений сторон: 1:1, 16:9, 9:16, 4:3, 3:4, что делает её универсальной для разных платформ и задач. К сожалению не из коробки и для этого необходимы некоторые знания программирования либо потратьте 1 день времени и весь дневной лимит и напишите себе свое собственное приложение-генератор с помощью того же Gemini.
Критические ограничения и проблемы
Несмотря на все впечатляющие возможности, важно понимать серьёзные недостатки модели, о которых честно рассказывают даже её создатели:
Отсутствие точного кадрирования: Модель не предлагает детального контроля над размерами изображения или кадрированием, что ограничивает применение в случаях, требующих пиксельной точности.
Проблемы с разрешением: В зависимости от промпта, некоторые изображения могут получаться размытыми или с недостатком деталей, что делает их непригодными для профессионального использования.
Проблемы с водяными знаками: Текущие водяные знаки видимы, но их легко обрезать или убрать с помощью inpaint через мое приложение. Внедрение невидимых SynthID-меток от Google до сих пор не завершено.
Проблемы совместимости и интеграции
Ошибки аутентификации: Многие пользователи сталкиваются с проблемами настройки API-ключей и аутентификации. Особенно часто возникает ошибка "Thinking is not enabled for models/gemini-2.5-flash-image-preview".
Проблемы с лимитами запросов: Ошибка 429 (RATE_LIMIT_EXCEEDED) встречается особенно часто в пиковые часы (09:00-11:00).
Нестабильность API: Пользователи сообщают о случаях, когда модель выдает ответ "OK, here is your updated image", но изменений не происходит. В таких ситуациях приходится каждый раз буквально "заставлять" её повторить действие.
Качественные недостатки
Проблемы с генерацией изображений: На Reddit пользователи жалуются на полную неспособность создавать изображения в течение 20+ часов, с ошибкой "NameError name '_generation' not defined".
Анатомические искажения: Как и многие другие ИИ-модели, иногда неправильно изображает анатомию человека, особенно руки и лица в сложных положениях. Я не сталкивался с этой проблемой и не могу назвать это недостатком модели.
(Пример проблемного промпта: "Человек играет на пианино с детальной постановкой пальцев" — часто приводит к искажённым рукам и неправильному количеству пальцев)
Проблемы с текстом: Несмотря на заявленные возможности, иногда искажает или неправильно отображает текст на изображениях.
(Пример проблемного промпта: "Книжная полка с чётко читаемыми названиями книг на разных языках" — текст часто получается нечитаемым или искажённым)
Ограничения понимания контекста
Неточная интерпретация сложных запросов: При многоступенчатых или сложных инструкциях модель может неправильно понять задачу.
(Пример проблемного промпта: "Создать изображение, где человек одновременно отражается в трёх разных зеркалах, показывающих три разных периода его жизни, сохраняя при этом фотореалистичное качество" — слишком сложно для корректного выполнения)
Проблемы с культурными и региональными особенностями: Модель может некорректно отображать специфические культурные элементы или архитектурные стили.
(Пример проблемного промпта: "Традиционная русская деревянная церковь с аутентичными луковичными куполами и православными иконографическими деталями" — может смешивать разные архитектурные традиции)
Настройка и устранение неполадок
Для ComfyUI
При установке ноды ComfyUI-NanoBanano обязательно:
- Установите все зависимости:
pip install google-generativeai torch pillow numpy requests
- Настройте API-ключ: Требуется платный Google Gemini API ключ - бесплатная версия НЕ поддерживает генерацию изображений.
- Учтите все ограничения: Максимум 4 изображения за запрос, до 5 референсных изображений.
Частые ошибки и решения
Ошибка 400 "Bad request": Проверьте формат промпта и размер загружаемых изображений.
Ошибка 401 "UNAUTHENTICATED": Убедитесь, что API-ключ валиден и имеет необходимые разрешения.
Ошибка 403 "PERMISSION_DENIED": Возможны географические ограничения, используйте сервис на три буквы или другие методы.
Практические советы по использованию
Оптимизация промптов
- Описывайте сцену, а не перечисляйте ключевые слова: Модель лучше понимает связные описания
(Хороший пример: "Уютный интерьер кофейни с тёплой деревянной мебелью, мягким светом от подвесных ламп, паром от свежесваренного кофе и посетителями, читающими книги у больших окон")
(Плохой пример: "кофе, магазин, интерьер, деревянный, освещение, пар, книги, окна")
- Будьте конкретны: Вместо "измени стиль" напишите "сделай в стиле импрессионизма"
(Хороший пример: "Превратить этот портрет в стиль импрессионистских картин Клода Моне с видимыми мазками кисти, мягким смешением цветов и акцентом на свете и атмосфере")
- Указывайте детали: Освещение, ракурс, настроение — всё влияет на результат
(Пример детального промпта: "Профессиональный портрет с мягким софтбоксным освещением слева, лёгкой улыбкой, прямым взглядом в камеру, нейтральным серым фоном, снято объективом 85мм с малой глубиной резкости")
Экономия ресурсов
- Используйте кэширование: Сохраняйте удачные результаты с хэшами промптов
- Группируйте запросы: Batch-обработка снижает стоимость на 50%
- Мониторьте расход токенов через Google Cloud Console
Влияние на творческие профессии
Новые возможности, а не замена
Важно понимать, что такие инструменты не заменяют творческих людей, а дают им новые возможности. Фотографу по-прежнему нужно знать, как поставить кадр. Дизайнеру — понимать принципы композиции. Художнику — чувствовать цвет и форму.
Но теперь все эти профессионалы могут воплощать свои идеи намного быстрее и экспериментировать с вариантами, которые раньше потребовали бы недель работы.
С другой стороны, такие инструменты делают визуальное творчество доступным для всех. Небольшой бизнес теперь может создавать качественные рекламные материалы без найма дорогих агентств. Блогер может делать уникальный контент без знания Photoshop или другого прикладного ПО.
Что ждёт нас дальше?
Судя по темпам развития, в ближайшие месяцы мы увидим ещё больше улучшений. Google уже анонсировал работу над видео-версией модели. Я даже и не представляю что в скором времени нам станет доступно редактирование видео простыми текстовыми командами.
Также обещают улучшение работы с 3D-объектами и более точное понимание сложных сцен с множеством персонажей.
Переход из статуса preview в стабильную версию ожидается уже в сентябре 2025 года, что принесёт улучшения производительности и расширенный функционал. Правда, эксперты прогнозируют рост цены на 20-30% после выхода из preview.
Заключение
Gemini 2.5 Flash Image действительно представляет собой прорыв в области ИИ-генерации изображений. Модель сочетает мощный функционал с простотой использования и доступной ценой.
Главные преимущества:
- Непревзойдённая консистентность персонажей
- Точное локальное редактирование
- Возможность создания визуальных серий
- Доступная цена ($0.039 за изображение)
- Простота использования
- Поддержка написания промптов на русском языке
Критические недостатки:
- Отсутствие точного контроля размеров
- Проблемы с разрешением выходных изображений и соотношением сторон из коробки
- Частые API-ошибки и проблемы стабильности
- Некоторые ограниченное понимание сложных контекстов
Да, у модели есть серьёзные ограничения, и она не заменит творческих профессионалов. Но как инструмент для расширения возможностей — это действительно революционное решение.
Ну и конечно же, если вам понравилась эта статья, буду рад любой вашей поддержке и подпискам, комментариям и лайкам. Недавно я запустил Discord-канал и постараюсь поддерживать его насколько возможно, там вы сможете не только следить за новостями, но и общаться, делиться опытом и приобретать новые знания о нейросетях. Чтобы всегда быть в курсе моих новых материалов, подписывайтесь на мой Boosty, Telegram-канал и страницу "ВКонтакте". Пока что нас немного, но я надеюсь, что с течением времени сообщество станет больше. Это станет отличной мотивацией для меня активно работать и над другими социальными сетями.